 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounter-Dyna: Data-Efficient RL-Based HVAC Control using Counterfactual Building Models
May 06, 2026Model-based reinforcement learning (MBRL) offers a promising approach for data-efficient energy management in buildings, combining the strengths of predictive modeling and reinforcement learning. While previous MBRL methods applied to HVAC control have reduced training data requirements, they still require several months of interaction with the building to learn a satisfactory control policy. A key reason is that existing surrogate models attempt to predict the entire state-space, including weather and electricity prices that are unaffected by control actions, or completely ignore these variables. Addressing these issues, we propose Counter-Dyna, a method that enhances the data-efficiency of Dyna, an MBRL method. We create data-efficient counterfactual surrogate models (CSM) by leveraging invariances in the state-space. Using a CSM in Dyna speeds up RL training measured in environment interaction data compared to previous results. In comparison with previous state-of-the-art that used 6-12 months of environment interactions, our method needs only 5 weeks. We evaluate our method in a large simulation study using the literature standard BOPTEST framework and proximal policy algorithm (PPO) as the RL algorithm. Our results show cost-saving potentials of 5.3% to 17.0% in a hypothetical deployment scenario. Our work is a significant step towards making real-world deployment of RL algorithms in HVAC control practically viable.
Transfer Learning for Neural Parameter Estimation applied to Building RC Models
Apr 07, 2026Parameter estimation for dynamical systems remains challenging due to non-convexity and sensitivity to initial parameter guesses. Recent deep learning approaches enable accurate and fast parameter estimation but do not exploit transferable knowledge across systems. To address this, we introduce a transfer-learning-based neural parameter estimation framework based on a pretraining-fine-tuning paradigm. This approach improves accuracy and eliminates the need for an initial parameter guess. We apply this framework to building RC thermal models, evaluating it against a Genetic Algorithm and a from-scratch neural baseline across eight simulated buildings, one real-world building, two RC model configurations, and four training data lengths. Results demonstrate an 18.6-24.0% performance improvement with only 12 days of training data and up to 49.4% with 72 days. Beyond buildings, the proposed method represents a new paradigm for parameter estimation in dynamical systems.
BOOST-RPF: Boosted Sequential Trees for Radial Power Flow
Mar 23, 2026Accurate power flow analysis is critical for modern distribution systems, yet classical solvers face scalability issues, and current machine learning models often struggle with generalization. We introduce BOOST-RPF, a novel method that reformulates voltage prediction from a global graph regression task into a sequential path-based learning problem. By decomposing radial networks into root-to-leaf paths, we leverage gradient-boosted decision trees (XGBoost) to model local voltage-drop regularities. We evaluate three architectural variants: Absolute Voltage, Parent Residual, and Physics-Informed Residual. This approach aligns the model architecture with the recursive physics of power flow, ensuring size-agnostic application and superior out-of-distribution robustness. Benchmarked against the Kerber Dorfnetz grid and the ENGAGE suite, BOOST-RPF achieves state-of-the-art results with its Parent Residual variant which consistently outperforms both analytical and neural baselines in standard accuracy and generalization tasks. While global Multi-Layer Perceptrons (MLPs) and Graph Neural Networks (GNNs) often suffer from performance degradation under topological shifts, BOOST-RPF maintains high precision across unseen feeders. Furthermore, the framework displays linear $O(N)$ computational scaling and significantly increased sample efficiency through per-edge supervision, offering a scalable and generalizable alternative for real-time distribution system operator (DSO) applications.
Adapting to Change: A Comparison of Continual and Transfer Learning for Modeling Building Thermal Dynamics under Concept Drifts
Aug 29, 2025Transfer Learning (TL) is currently the most effective approach for modeling building thermal dynamics when only limited data are available. TL uses a pretrained model that is fine-tuned to a specific target building. However, it remains unclear how to proceed after initial fine-tuning, as more operational measurement data are collected over time. This challenge becomes even more complex when the dynamics of the building change, for example, after a retrofit or a change in occupancy. In Machine Learning literature, Continual Learning (CL) methods are used to update models of changing systems. TL approaches can also address this challenge by reusing the pretrained model at each update step and fine-tuning it with new measurement data. A comprehensive study on how to incorporate new measurement data over time to improve prediction accuracy and address the challenges of concept drifts (changes in dynamics) for building thermal dynamics is still missing. Therefore, this study compares several CL and TL strategies, as well as a model trained from scratch, for thermal dynamics modeling during building operation. The methods are evaluated using 5--7 years of simulated data representative of single-family houses in Central Europe, including scenarios with concept drifts from retrofits and changes in occupancy. We propose a CL strategy (Seasonal Memory Learning) that provides greater accuracy improvements than existing CL and TL methods, while maintaining low computational effort. SML outperformed the benchmark of initial fine-tuning by 28.1\% without concept drifts and 34.9\% with concept drifts.
GenTL: A General Transfer Learning Model for Building Thermal Dynamics
Jan 23, 2025Transfer Learning (TL) is an emerging field in modeling building thermal dynamics. This method reduces the data required for a data-driven model of a target building by leveraging knowledge from a source building. Consequently, it enables the creation of data-efficient models that can be used for advanced control and fault detection & diagnosis. A major limitation of the TL approach is its inconsistent performance across different sources. Although accurate source-building selection for a target is crucial, it remains a persistent challenge. We present GenTL, a general transfer learning model for single-family houses in Central Europe. GenTL can be efficiently fine-tuned to a large variety of target buildings. It is pretrained on a Long Short-Term Memory (LSTM) network with data from 450 different buildings. The general transfer learning model eliminates the need for source-building selection by serving as a universal source for fine-tuning. Comparative analysis with conventional single-source to single-target TL demonstrates the efficacy and reliability of the general pretraining approach. Testing GenTL on 144 target buildings for fine-tuning reveals an average prediction error (RMSE) reduction of 42.1 % compared to fine-tuning single-source models.
* This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record will be published in the ACM library in Jun 2025
Household Electricity Demand Forecasting -- Benchmarking State-of-the-Art Methods
Apr 01, 2014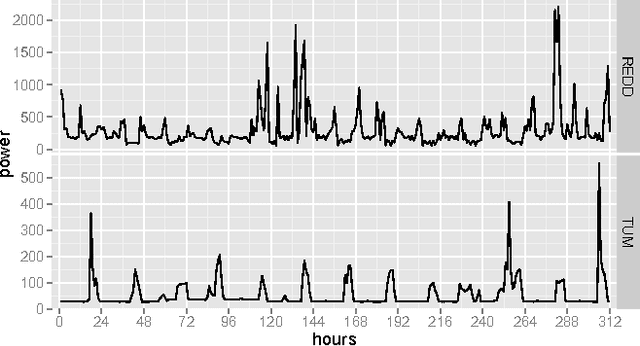
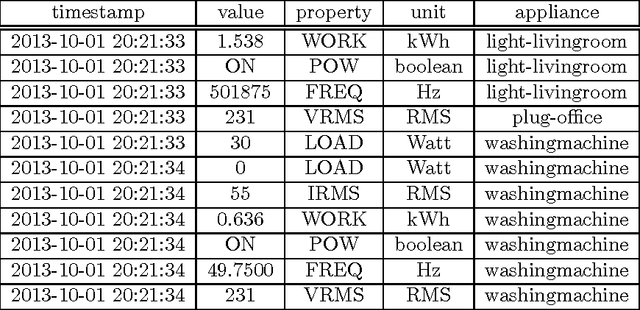
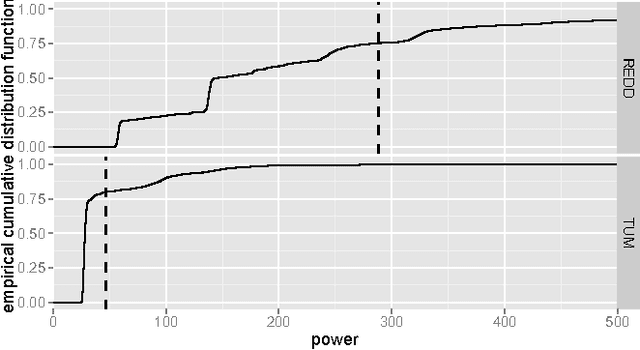
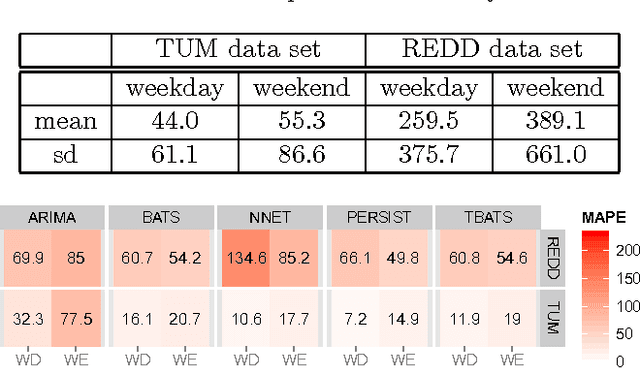
The increasing use of renewable energy sources with variable output, such as solar photovoltaic and wind power generation, calls for Smart Grids that effectively manage flexible loads and energy storage. The ability to forecast consumption at different locations in distribution systems will be a key capability of Smart Grids. The goal of this paper is to benchmark state-of-the-art methods for forecasting electricity demand on the household level across different granularities and time scales in an explorative way, thereby revealing potential shortcomings and find promising directions for future research in this area. We apply a number of forecasting methods including ARIMA, neural networks, and exponential smoothening using several strategies for training data selection, in particular day type and sliding window based strategies. We consider forecasting horizons ranging between 15 minutes and 24 hours. Our evaluation is based on two data sets containing the power usage of individual appliances at second time granularity collected over the course of several months. The results indicate that forecasting accuracy varies significantly depending on the choice of forecasting methods/strategy and the parameter configuration. Measured by the Mean Absolute Percentage Error (MAPE), the considered state-of-the-art forecasting methods rarely beat corresponding persistence forecasts. Overall, we observed MAPEs in the range between 5 and >100%. The average MAPE for the first data set was ~30%, while it was ~85% for the other data set. These results show big room for improvement. Based on the identified trends and experiences from our experiments, we contribute a detailed discussion of promising future research.