 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Games for Combinatorial Bayesian Optimization with Application to Protein Design
Sep 27, 2024Bayesian optimization (BO) is a powerful framework to optimize black-box expensive-to-evaluate functions via sequential interactions. In several important problems (e.g. drug discovery, circuit design, neural architecture search, etc.), though, such functions are defined over large $\textit{combinatorial and unstructured}$ spaces. This makes existing BO algorithms not feasible due to the intractable maximization of the acquisition function over these domains. To address this issue, we propose $\textbf{GameOpt}$, a novel game-theoretical approach to combinatorial BO. $\textbf{GameOpt}$ establishes a cooperative game between the different optimization variables, and selects points that are game $\textit{equilibria}$ of an upper confidence bound acquisition function. These are stable configurations from which no variable has an incentive to deviate$-$ analog to local optima in continuous domains. Crucially, this allows us to efficiently break down the complexity of the combinatorial domain into individual decision sets, making $\textbf{GameOpt}$ scalable to large combinatorial spaces. We demonstrate the application of $\textbf{GameOpt}$ to the challenging $\textit{protein design}$ problem and validate its performance on four real-world protein datasets. Each protein can take up to $20^{X}$ possible configurations, where $X$ is the length of a protein, making standard BO methods infeasible. Instead, our approach iteratively selects informative protein configurations and very quickly discovers highly active protein variants compared to other baselines.
Towards safe and tractable Gaussian process-based MPC: Efficient sampling within a sequential quadratic programming framework
Sep 13, 2024Learning uncertain dynamics models using Gaussian process~(GP) regression has been demonstrated to enable high-performance and safety-aware control strategies for challenging real-world applications. Yet, for computational tractability, most approaches for Gaussian process-based model predictive control (GP-MPC) are based on approximations of the reachable set that are either overly conservative or impede the controller's safety guarantees. To address these challenges, we propose a robust GP-MPC formulation that guarantees constraint satisfaction with high probability. For its tractable implementation, we propose a sampling-based GP-MPC approach that iteratively generates consistent dynamics samples from the GP within a sequential quadratic programming framework. We highlight the improved reachable set approximation compared to existing methods, as well as real-time feasible computation times, using two numerical examples.
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Aug 18, 2024



Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic B\"uchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Geometric Active Exploration in Markov Decision Processes: the Benefit of Abstraction
Jul 18, 2024

How can a scientist use a Reinforcement Learning (RL) algorithm to design experiments over a dynamical system's state space? In the case of finite and Markovian systems, an area called Active Exploration (AE) relaxes the optimization problem of experiments design into Convex RL, a generalization of RL admitting a wider notion of reward. Unfortunately, this framework is currently not scalable and the potential of AE is hindered by the vastness of experiment spaces typical of scientific discovery applications. However, these spaces are often endowed with natural geometries, e.g., permutation invariance in molecular design, that an agent could leverage to improve the statistical and computational efficiency of AE. To achieve this, we bridge AE and MDP homomorphisms, which offer a way to exploit known geometric structures via abstraction. Towards this goal, we make two fundamental contributions: we extend MDP homomorphisms formalism to Convex RL, and we present, to the best of our knowledge, the first analysis that formally captures the benefit of abstraction via homomorphisms on sample efficiency. Ultimately, we propose the Geometric Active Exploration (GAE) algorithm, which we analyse theoretically and experimentally in environments motivated by problems in scientific discovery.
Global Reinforcement Learning: Beyond Linear and Convex Rewards via Submodular Semi-gradient Methods
Jul 13, 2024In classic Reinforcement Learning (RL), the agent maximizes an additive objective of the visited states, e.g., a value function. Unfortunately, objectives of this type cannot model many real-world applications such as experiment design, exploration, imitation learning, and risk-averse RL to name a few. This is due to the fact that additive objectives disregard interactions between states that are crucial for certain tasks. To tackle this problem, we introduce Global RL (GRL), where rewards are globally defined over trajectories instead of locally over states. Global rewards can capture negative interactions among states, e.g., in exploration, via submodularity, positive interactions, e.g., synergetic effects, via supermodularity, while mixed interactions via combinations of them. By exploiting ideas from submodular optimization, we propose a novel algorithmic scheme that converts any GRL problem to a sequence of classic RL problems and solves it efficiently with curvature-dependent approximation guarantees. We also provide hardness of approximation results and empirically demonstrate the effectiveness of our method on several GRL instances.
Bandits with Preference Feedback: A Stackelberg Game Perspective
Jun 24, 2024



Bandits with preference feedback present a powerful tool for optimizing unknown target functions when only pairwise comparisons are allowed instead of direct value queries. This model allows for incorporating human feedback into online inference and optimization and has been employed in systems for fine-tuning large language models. The problem is well understood in simplified settings with linear target functions or over finite small domains that limit practical interest. Taking the next step, we consider infinite domains and nonlinear (kernelized) rewards. In this setting, selecting a pair of actions is quite challenging and requires balancing exploration and exploitation at two levels: within the pair, and along the iterations of the algorithm. We propose MAXMINLCB, which emulates this trade-off as a zero-sum Stackelberg game, and chooses action pairs that are informative and yield favorable rewards. MAXMINLCB consistently outperforms existing algorithms and satisfies an anytime-valid rate-optimal regret guarantee. This is due to our novel preference-based confidence sequences for kernelized logistic estimators.
Standardizing Structural Causal Models
Jun 17, 2024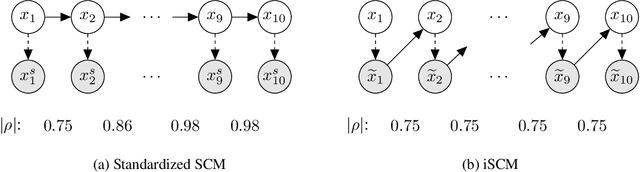
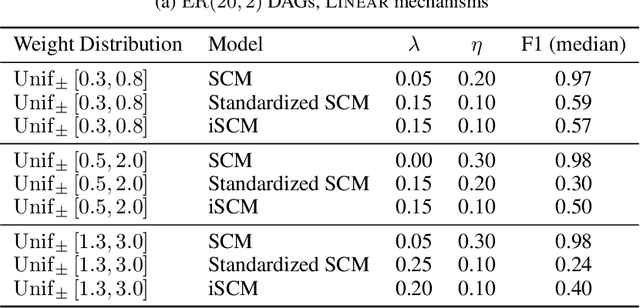
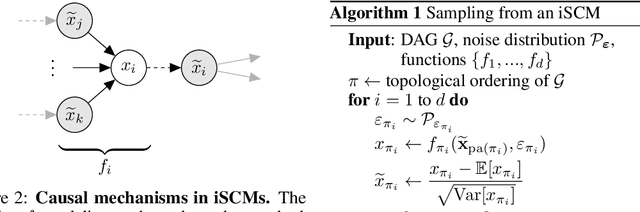
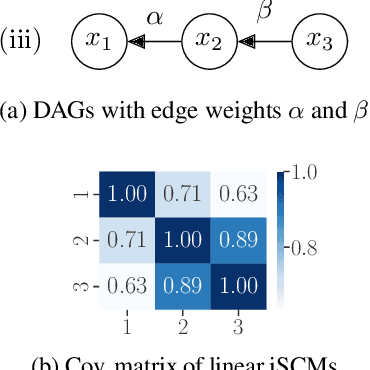
Synthetic datasets generated by structural causal models (SCMs) are commonly used for benchmarking causal structure learning algorithms. However, the variances and pairwise correlations in SCM data tend to increase along the causal ordering. Several popular algorithms exploit these artifacts, possibly leading to conclusions that do not generalize to real-world settings. Existing metrics like $\operatorname{Var}$-sortability and $\operatorname{R^2}$-sortability quantify these patterns, but they do not provide tools to remedy them. To address this, we propose internally-standardized structural causal models (iSCMs), a modification of SCMs that introduces a standardization operation at each variable during the generative process. By construction, iSCMs are not $\operatorname{Var}$-sortable, and as we show experimentally, not $\operatorname{R^2}$-sortable either for commonly-used graph families. Moreover, contrary to the post-hoc standardization of data generated by standard SCMs, we prove that linear iSCMs are less identifiable from prior knowledge on the weights and do not collapse to deterministic relationships in large systems, which may make iSCMs a useful model in causal inference beyond the benchmarking problem studied here.
Breeding Programs Optimization with Reinforcement Learning
Jun 06, 2024

Crop breeding is crucial in improving agricultural productivity while potentially decreasing land usage, greenhouse gas emissions, and water consumption. However, breeding programs are challenging due to long turnover times, high-dimensional decision spaces, long-term objectives, and the need to adapt to rapid climate change. This paper introduces the use of Reinforcement Learning (RL) to optimize simulated crop breeding programs. RL agents are trained to make optimal crop selection and cross-breeding decisions based on genetic information. To benchmark RL-based breeding algorithms, we introduce a suite of Gym environments. The study demonstrates the superiority of RL techniques over standard practices in terms of genetic gain when simulated in silico using real-world genomic maize data.
When to Sense and Control? A Time-adaptive Approach for Continuous-Time RL
Jun 04, 2024Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice. In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore, we generally prefer a time-adaptive approach with fewer interactions with the system. In this work, we formalize an RL framework, Time-adaptive Control & Sensing (TaCoS), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve. We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency. Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.
NeoRL: Efficient Exploration for Nonepisodic RL
Jun 04, 2024We study the problem of nonepisodic reinforcement learning (RL) for nonlinear dynamical systems, where the system dynamics are unknown and the RL agent has to learn from a single trajectory, i.e., without resets. We propose Nonepisodic Optimistic RL (NeoRL), an approach based on the principle of optimism in the face of uncertainty. NeoRL uses well-calibrated probabilistic models and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics. Under continuity and bounded energy assumptions on the system, we provide a first-of-its-kind regret bound of $\setO(\beta_T \sqrt{T \Gamma_T})$ for general nonlinear systems with Gaussian process dynamics. We compare NeoRL to other baselines on several deep RL environments and empirically demonstrate that NeoRL achieves the optimal average cost while incurring the least regret.