 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN Explanations that do not Explain and How to find Them
Jan 28, 2026Explanations provided by Self-explainable Graph Neural Networks (SE-GNNs) are fundamental for understanding the model's inner workings and for identifying potential misuse of sensitive attributes. Although recent works have highlighted that these explanations can be suboptimal and potentially misleading, a characterization of their failure cases is unavailable. In this work, we identify a critical failure of SE-GNN explanations: explanations can be unambiguously unrelated to how the SE-GNNs infer labels. We show that, on the one hand, many SE-GNNs can achieve optimal true risk while producing these degenerate explanations, and on the other, most faithfulness metrics can fail to identify these failure modes. Our empirical analysis reveals that degenerate explanations can be maliciously planted (allowing an attacker to hide the use of sensitive attributes) and can also emerge naturally, highlighting the need for reliable auditing. To address this, we introduce a novel faithfulness metric that reliably marks degenerate explanations as unfaithful, in both malicious and natural settings. Our code is available in the supplemental.
Rethinking GNNs and Missing Features: Challenges, Evaluation and a Robust Solution
Jan 08, 2026Handling missing node features is a key challenge for deploying Graph Neural Networks (GNNs) in real-world domains such as healthcare and sensor networks. Existing studies mostly address relatively benign scenarios, namely benchmark datasets with (a) high-dimensional but sparse node features and (b) incomplete data generated under Missing Completely At Random (MCAR) mechanisms. For (a), we theoretically prove that high sparsity substantially limits the information loss caused by missingness, making all models appear robust and preventing a meaningful comparison of their performance. To overcome this limitation, we introduce one synthetic and three real-world datasets with dense, semantically meaningful features. For (b), we move beyond MCAR and design evaluation protocols with more realistic missingness mechanisms. Moreover, we provide a theoretical background to state explicit assumptions on the missingness process and analyze their implications for different methods. Building on this analysis, we propose GNNmim, a simple yet effective baseline for node classification with incomplete feature data. Experiments show that GNNmim is competitive with respect to specialized architectures across diverse datasets and missingness regimes.
Multiclass Local Calibration With the Jensen-Shannon Distance
Oct 30, 2025Developing trustworthy Machine Learning (ML) models requires their predicted probabilities to be well-calibrated, meaning they should reflect true-class frequencies. Among calibration notions in multiclass classification, strong calibration is the most stringent, as it requires all predicted probabilities to be simultaneously calibrated across all classes. However, existing approaches to multiclass calibration lack a notion of distance among inputs, which makes them vulnerable to proximity bias: predictions in sparse regions of the feature space are systematically miscalibrated. This is especially relevant in high-stakes settings, such as healthcare, where the sparse instances are exactly those most at risk of biased treatment. In this work, we address this main shortcoming by introducing a local perspective on multiclass calibration. First, we formally define multiclass local calibration and establish its relationship with strong calibration. Second, we theoretically analyze the pitfalls of existing evaluation metrics when applied to multiclass local calibration. Third, we propose a practical method for enhancing local calibration in Neural Networks, which enforces alignment between predicted probabilities and local estimates of class frequencies using the Jensen-Shannon distance. Finally, we empirically validate our approach against existing multiclass calibration techniques.
Symbol Grounding in Neuro-Symbolic AI: A Gentle Introduction to Reasoning Shortcuts
Oct 16, 2025



Neuro-symbolic (NeSy) AI aims to develop deep neural networks whose predictions comply with prior knowledge encoding, e.g. safety or structural constraints. As such, it represents one of the most promising avenues for reliable and trustworthy AI. The core idea behind NeSy AI is to combine neural and symbolic steps: neural networks are typically responsible for mapping low-level inputs into high-level symbolic concepts, while symbolic reasoning infers predictions compatible with the extracted concepts and the prior knowledge. Despite their promise, it was recently shown that - whenever the concepts are not supervised directly - NeSy models can be affected by Reasoning Shortcuts (RSs). That is, they can achieve high label accuracy by grounding the concepts incorrectly. RSs can compromise the interpretability of the model's explanations, performance in out-of-distribution scenarios, and therefore reliability. At the same time, RSs are difficult to detect and prevent unless concept supervision is available, which is typically not the case. However, the literature on RSs is scattered, making it difficult for researchers and practitioners to understand and tackle this challenging problem. This overview addresses this issue by providing a gentle introduction to RSs, discussing their causes and consequences in intuitive terms. It also reviews and elucidates existing theoretical characterizations of this phenomenon. Finally, it details methods for dealing with RSs, including mitigation and awareness strategies, and maps their benefits and limitations. By reformulating advanced material in a digestible form, this overview aims to provide a unifying perspective on RSs to lower the bar to entry for tackling them. Ultimately, we hope this overview contributes to the development of reliable NeSy and trustworthy AI models.
Towards Reliable Retrieval in RAG Systems for Large Legal Datasets
Oct 08, 2025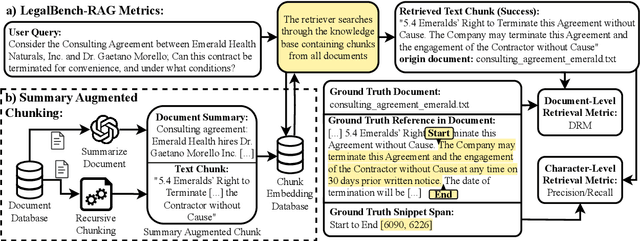

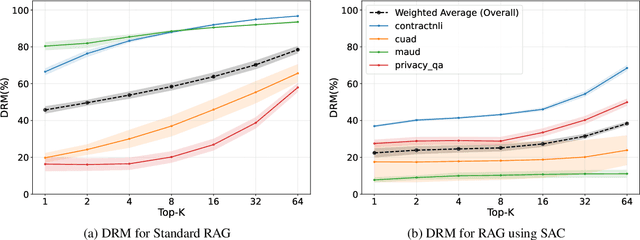
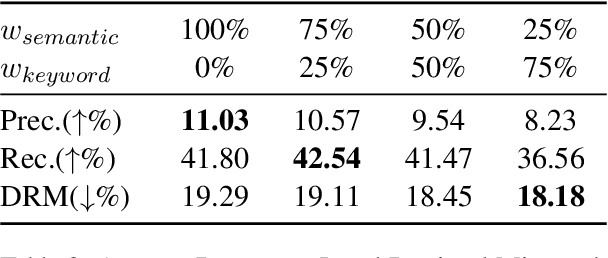
Retrieval-Augmented Generation (RAG) is a promising approach to mitigate hallucinations in Large Language Models (LLMs) for legal applications, but its reliability is critically dependent on the accuracy of the retrieval step. This is particularly challenging in the legal domain, where large databases of structurally similar documents often cause retrieval systems to fail. In this paper, we address this challenge by first identifying and quantifying a critical failure mode we term Document-Level Retrieval Mismatch (DRM), where the retriever selects information from entirely incorrect source documents. To mitigate DRM, we investigate a simple and computationally efficient technique which we refer to as Summary-Augmented Chunking (SAC). This method enhances each text chunk with a document-level synthetic summary, thereby injecting crucial global context that would otherwise be lost during a standard chunking process. Our experiments on a diverse set of legal information retrieval tasks show that SAC greatly reduces DRM and, consequently, also improves text-level retrieval precision and recall. Interestingly, we find that a generic summarization strategy outperforms an approach that incorporates legal expert domain knowledge to target specific legal elements. Our work provides evidence that this practical, scalable, and easily integrable technique enhances the reliability of RAG systems when applied to large-scale legal document datasets.
A Neuro-Symbolic Approach for Probabilistic Reasoning on Graph Data
Jul 29, 2025Graph neural networks (GNNs) excel at predictive tasks on graph-structured data but often lack the ability to incorporate symbolic domain knowledge and perform general reasoning. Relational Bayesian Networks (RBNs), in contrast, enable fully generative probabilistic modeling over graph-like structures and support rich symbolic knowledge and probabilistic inference. This paper presents a neuro-symbolic framework that seamlessly integrates GNNs into RBNs, combining the learning strength of GNNs with the flexible reasoning capabilities of RBNs. We develop two implementations of this integration: one compiles GNNs directly into the native RBN language, while the other maintains the GNN as an external component. Both approaches preserve the semantics and computational properties of GNNs while fully aligning with the RBN modeling paradigm. We also propose a maximum a-posteriori (MAP) inference method for these neuro-symbolic models. To demonstrate the framework's versatility, we apply it to two distinct problems. First, we transform a GNN for node classification into a collective classification model that explicitly models homo- and heterophilic label patterns, substantially improving accuracy. Second, we introduce a multi-objective network optimization problem in environmental planning, where MAP inference supports complex decision-making. Both applications include new publicly available benchmark datasets. This work introduces a powerful and coherent neuro-symbolic approach to graph data, bridging learning and reasoning in ways that enable novel applications and improved performance across diverse tasks.
Boosting Team Modeling through Tempo-Relational Representation Learning
Jul 17, 2025Team modeling remains a fundamental challenge at the intersection of Artificial Intelligence and the Social Sciences. Social Science research emphasizes the need to jointly model dynamics and relations, while practical applications demand unified models capable of inferring multiple team constructs simultaneously, providing interpretable insights and actionable recommendations to enhance team performance. However, existing works do not meet these practical demands. To bridge this gap, we present TRENN, a novel tempo-relational architecture that integrates: (i) an automatic temporal graph extractor, (ii) a tempo-relational encoder, (iii) a decoder for team construct prediction, and (iv) two complementary explainability modules. TRENN jointly captures relational and temporal team dynamics, providing a solid foundation for MT-TRENN, which extends TReNN by replacing the decoder with a multi-task head, enabling the model to learn shared Social Embeddings and simultaneously predict multiple team constructs, including Emergent Leadership, Leadership Style, and Teamwork components. Experimental results demonstrate that our approach significantly outperforms approaches that rely exclusively on temporal or relational information. Additionally, experimental evaluation has shown that the explainability modules integrated in MT-TRENN yield interpretable insights and actionable suggestions to support team improvement. These capabilities make our approach particularly well-suited for Human-Centered AI applications, such as intelligent decision-support systems in high-stakes collaborative environments.
Personalized Interpretability -- Interactive Alignment of Prototypical Parts Networks
Jun 05, 2025Concept-based interpretable neural networks have gained significant attention due to their intuitive and easy-to-understand explanations based on case-based reasoning, such as "this bird looks like those sparrows". However, a major limitation is that these explanations may not always be comprehensible to users due to concept inconsistency, where multiple visual features are inappropriately mixed (e.g., a bird's head and wings treated as a single concept). This inconsistency breaks the alignment between model reasoning and human understanding. Furthermore, users have specific preferences for how concepts should look, yet current approaches provide no mechanism for incorporating their feedback. To address these issues, we introduce YoursProtoP, a novel interactive strategy that enables the personalization of prototypical parts - the visual concepts used by the model - according to user needs. By incorporating user supervision, YoursProtoP adapts and splits concepts used for both prediction and explanation to better match the user's preferences and understanding. Through experiments on both the synthetic FunnyBirds dataset and a real-world scenario using the CUB, CARS, and PETS datasets in a comprehensive user study, we demonstrate the effectiveness of YoursProtoP in achieving concept consistency without compromising the accuracy of the model.
If Concept Bottlenecks are the Question, are Foundation Models the Answer?
Apr 29, 2025Concept Bottleneck Models (CBMs) are neural networks designed to conjoin high performance with ante-hoc interpretability. CBMs work by first mapping inputs (e.g., images) to high-level concepts (e.g., visible objects and their properties) and then use these to solve a downstream task (e.g., tagging or scoring an image) in an interpretable manner. Their performance and interpretability, however, hinge on the quality of the concepts they learn. The go-to strategy for ensuring good quality concepts is to leverage expert annotations, which are expensive to collect and seldom available in applications. Researchers have recently addressed this issue by introducing "VLM-CBM" architectures that replace manual annotations with weak supervision from foundation models. It is however unclear what is the impact of doing so on the quality of the learned concepts. To answer this question, we put state-of-the-art VLM-CBMs to the test, analyzing their learned concepts empirically using a selection of significant metrics. Our results show that, depending on the task, VLM supervision can sensibly differ from expert annotations, and that concept accuracy and quality are not strongly correlated. Our code is available at https://github.com/debryu/CQA.
Boosting Relational Deep Learning with Pretrained Tabular Models
Apr 07, 2025Relational databases, organized into tables connected by primary-foreign key relationships, are a common format for organizing data. Making predictions on relational data often involves transforming them into a flat tabular format through table joins and feature engineering, which serve as input to tabular methods. However, designing features that fully capture complex relational patterns remains challenging. Graph Neural Networks (GNNs) offer a compelling alternative by inherently modeling these relationships, but their time overhead during inference limits their applicability for real-time scenarios. In this work, we aim to bridge this gap by leveraging existing feature engineering efforts to enhance the efficiency of GNNs in relational databases. Specifically, we use GNNs to capture complex relationships within relational databases, patterns that are difficult to featurize, while employing engineered features to encode temporal information, thereby avoiding the need to retain the entire historical graph and enabling the use of smaller, more efficient graphs. Our \textsc{LightRDL} approach not only improves efficiency, but also outperforms existing models. Experimental results on the RelBench benchmark demonstrate that our framework achieves up to $33\%$ performance improvement and a $526\times$ inference speedup compared to GNNs, making it highly suitable for real-time inference.