 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Retrieval in RAG Systems for Large Legal Datasets
Oct 08, 2025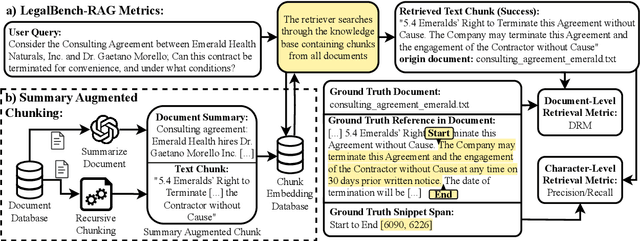

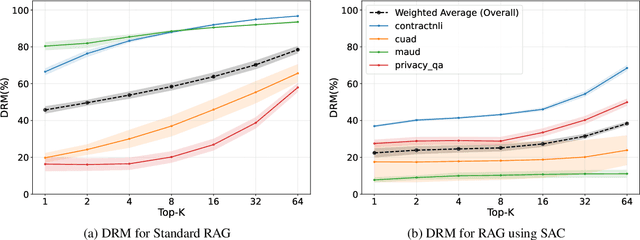
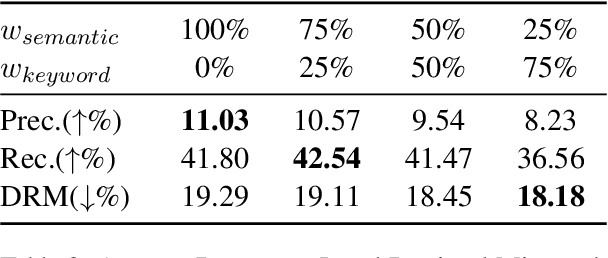
Retrieval-Augmented Generation (RAG) is a promising approach to mitigate hallucinations in Large Language Models (LLMs) for legal applications, but its reliability is critically dependent on the accuracy of the retrieval step. This is particularly challenging in the legal domain, where large databases of structurally similar documents often cause retrieval systems to fail. In this paper, we address this challenge by first identifying and quantifying a critical failure mode we term Document-Level Retrieval Mismatch (DRM), where the retriever selects information from entirely incorrect source documents. To mitigate DRM, we investigate a simple and computationally efficient technique which we refer to as Summary-Augmented Chunking (SAC). This method enhances each text chunk with a document-level synthetic summary, thereby injecting crucial global context that would otherwise be lost during a standard chunking process. Our experiments on a diverse set of legal information retrieval tasks show that SAC greatly reduces DRM and, consequently, also improves text-level retrieval precision and recall. Interestingly, we find that a generic summarization strategy outperforms an approach that incorporates legal expert domain knowledge to target specific legal elements. Our work provides evidence that this practical, scalable, and easily integrable technique enhances the reliability of RAG systems when applied to large-scale legal document datasets.
Memory networks for consumer protection:unfairness exposed
Jul 24, 2020
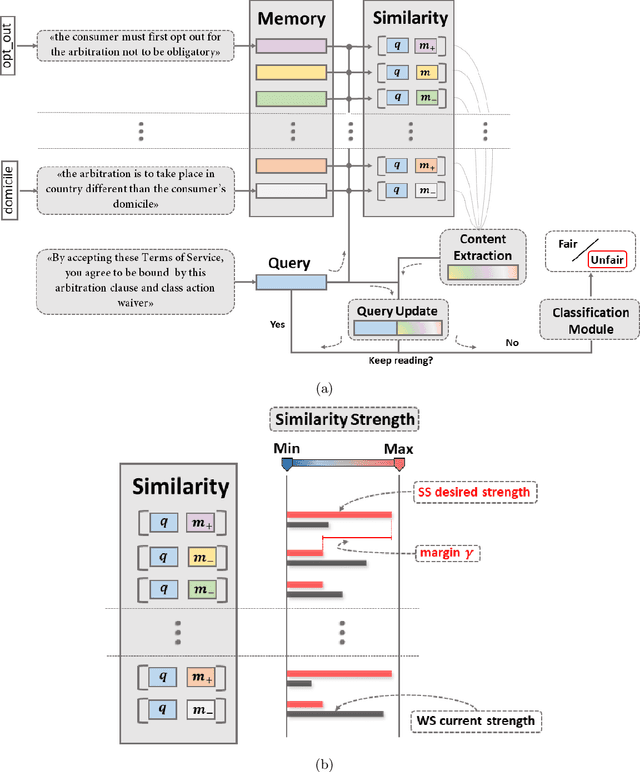
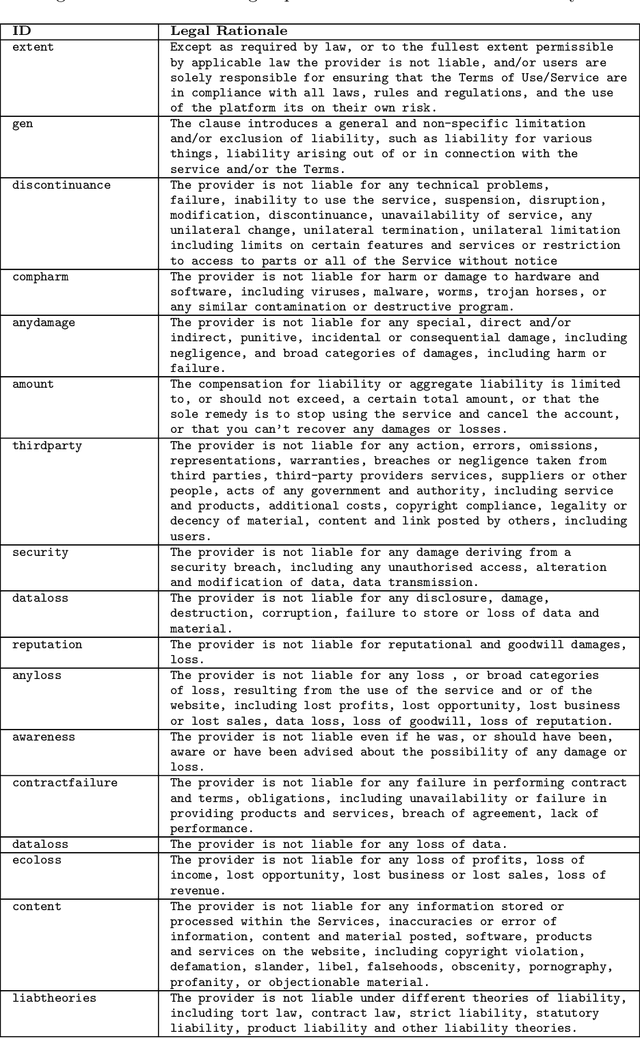
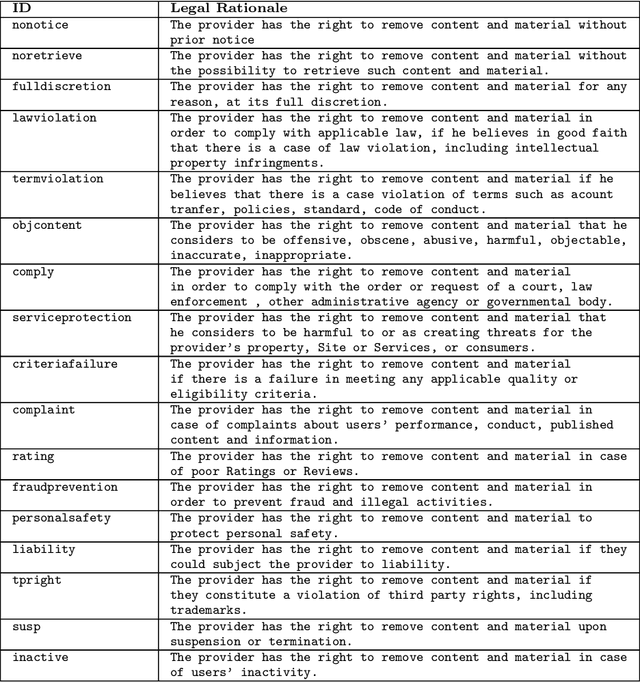
Recent work has demonstrated how data-driven AI methods can leverage consumer protection by supporting the automated analysis of legal documents. However, a shortcoming of data-driven approaches is poor explainability. We posit that in this domain useful explanations of classifier outcomes can be provided by resorting to legal rationales. We thus consider several configurations of memory-augmented neural networks where rationales are given a special role in the modeling of context knowledge. Our results show that rationales not only contribute to improve the classification accuracy, but are also able to offer meaningful, natural language explanations of otherwise opaque classifier outcomes.
CLAUDETTE: an Automated Detector of Potentially Unfair Clauses in Online Terms of Service
May 03, 2018
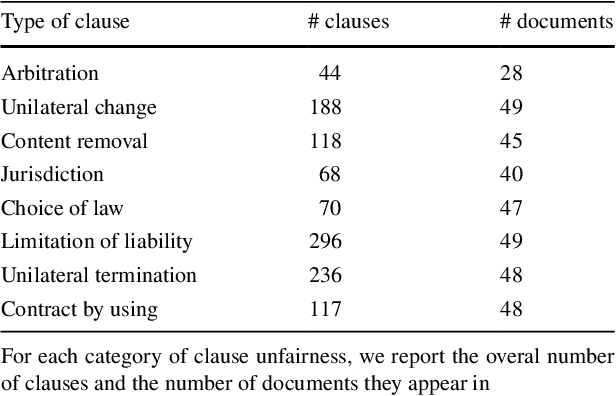
Terms of service of on-line platforms too often contain clauses that are potentially unfair to the consumer. We present an experimental study where machine learning is employed to automatically detect such potentially unfair clauses. Results show that the proposed system could provide a valuable tool for lawyers and consumers alike.