 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnCommon Objects in 3D
Jan 13, 2025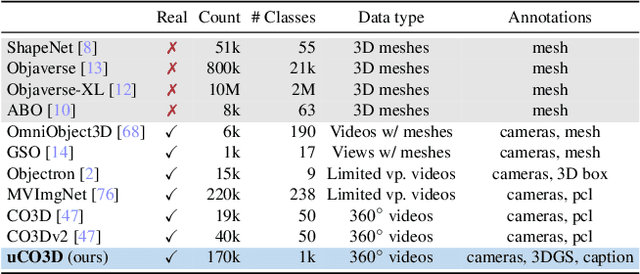
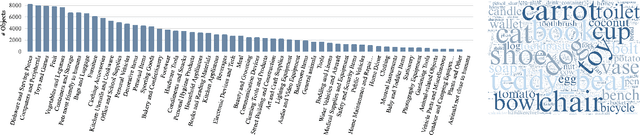


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
PartGen: Part-level 3D Generation and Reconstruction with Multi-View Diffusion Models
Dec 24, 2024



Text- or image-to-3D generators and 3D scanners can now produce 3D assets with high-quality shapes and textures. These assets typically consist of a single, fused representation, like an implicit neural field, a Gaussian mixture, or a mesh, without any useful structure. However, most applications and creative workflows require assets to be made of several meaningful parts that can be manipulated independently. To address this gap, we introduce PartGen, a novel approach that generates 3D objects composed of meaningful parts starting from text, an image, or an unstructured 3D object. First, given multiple views of a 3D object, generated or rendered, a multi-view diffusion model extracts a set of plausible and view-consistent part segmentations, dividing the object into parts. Then, a second multi-view diffusion model takes each part separately, fills in the occlusions, and uses those completed views for 3D reconstruction by feeding them to a 3D reconstruction network. This completion process considers the context of the entire object to ensure that the parts integrate cohesively. The generative completion model can make up for the information missing due to occlusions; in extreme cases, it can hallucinate entirely invisible parts based on the input 3D asset. We evaluate our method on generated and real 3D assets and show that it outperforms segmentation and part-extraction baselines by a large margin. We also showcase downstream applications such as 3D part editing.
DualPM: Dual Posed-Canonical Point Maps for 3D Shape and Pose Reconstruction
Dec 05, 2024



The choice of data representation is a key factor in the success of deep learning in geometric tasks. For instance, DUSt3R has recently introduced the concept of viewpoint-invariant point maps, generalizing depth prediction, and showing that one can reduce all the key problems in the 3D reconstruction of static scenes to predicting such point maps. In this paper, we develop an analogous concept for a very different problem, namely, the reconstruction of the 3D shape and pose of deformable objects. To this end, we introduce the Dual Point Maps (DualPM), where a pair of point maps is extracted from the {same} image, one associating pixels to their 3D locations on the object, and the other to a canonical version of the object at rest pose. We also extend point maps to amodal reconstruction, seeing through self-occlusions to obtain the complete shape of the object. We show that 3D reconstruction and 3D pose estimation reduce to the prediction of the DualPMs. We demonstrate empirically that this representation is a good target for a deep network to predict; specifically, we consider modeling horses, showing that DualPMs can be trained purely on 3D synthetic data, consisting of a single model of a horse, while generalizing very well to real images. With this, we improve by a large margin previous methods for the 3D analysis and reconstruction of this type of objects.
3D Convex Splatting: Radiance Field Rendering with 3D Smooth Convexes
Nov 26, 2024



Recent advances in radiance field reconstruction, such as 3D Gaussian Splatting (3DGS), have achieved high-quality novel view synthesis and fast rendering by representing scenes with compositions of Gaussian primitives. However, 3D Gaussians present several limitations for scene reconstruction. Accurately capturing hard edges is challenging without significantly increasing the number of Gaussians, creating a large memory footprint. Moreover, they struggle to represent flat surfaces, as they are diffused in space. Without hand-crafted regularizers, they tend to disperse irregularly around the actual surface. To circumvent these issues, we introduce a novel method, named 3D Convex Splatting (3DCS), which leverages 3D smooth convexes as primitives for modeling geometrically-meaningful radiance fields from multi-view images. Smooth convex shapes offer greater flexibility than Gaussians, allowing for a better representation of 3D scenes with hard edges and dense volumes using fewer primitives. Powered by our efficient CUDA-based rasterizer, 3DCS achieves superior performance over 3DGS on benchmarks such as Mip-NeRF360, Tanks and Temples, and Deep Blending. Specifically, our method attains an improvement of up to 0.81 in PSNR and 0.026 in LPIPS compared to 3DGS while maintaining high rendering speeds and reducing the number of required primitives. Our results highlight the potential of 3D Convex Splatting to become the new standard for high-quality scene reconstruction and novel view synthesis. Project page: convexsplatting.github.io.
MVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
Nov 07, 2024



We introduce MVSplat360, a feed-forward approach for 360{\deg} novel view synthesis (NVS) of diverse real-world scenes, using only sparse observations. This setting is inherently ill-posed due to minimal overlap among input views and insufficient visual information provided, making it challenging for conventional methods to achieve high-quality results. Our MVSplat360 addresses this by effectively combining geometry-aware 3D reconstruction with temporally consistent video generation. Specifically, it refactors a feed-forward 3D Gaussian Splatting (3DGS) model to render features directly into the latent space of a pre-trained Stable Video Diffusion (SVD) model, where these features then act as pose and visual cues to guide the denoising process and produce photorealistic 3D-consistent views. Our model is end-to-end trainable and supports rendering arbitrary views with as few as 5 sparse input views. To evaluate MVSplat360's performance, we introduce a new benchmark using the challenging DL3DV-10K dataset, where MVSplat360 achieves superior visual quality compared to state-of-the-art methods on wide-sweeping or even 360{\deg} NVS tasks. Experiments on the existing benchmark RealEstate10K also confirm the effectiveness of our model. The video results are available on our project page: https://donydchen.github.io/mvsplat360.
CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
Oct 15, 2024Most state-of-the-art point trackers are trained on synthetic data due to the difficulty of annotating real videos for this task. However, this can result in suboptimal performance due to the statistical gap between synthetic and real videos. In order to understand these issues better, we introduce CoTracker3, comprising a new tracking model and a new semi-supervised training recipe. This allows real videos without annotations to be used during training by generating pseudo-labels using off-the-shelf teachers. The new model eliminates or simplifies components from previous trackers, resulting in a simpler and often smaller architecture. This training scheme is much simpler than prior work and achieves better results using 1,000 times less data. We further study the scaling behaviour to understand the impact of using more real unsupervised data in point tracking. The model is available in online and offline variants and reliably tracks visible and occluded points.
Flex3D: Feed-Forward 3D Generation With Flexible Reconstruction Model And Input View Curation
Oct 02, 2024



Generating high-quality 3D content from text, single images, or sparse view images remains a challenging task with broad applications. Existing methods typically employ multi-view diffusion models to synthesize multi-view images, followed by a feed-forward process for 3D reconstruction. However, these approaches are often constrained by a small and fixed number of input views, limiting their ability to capture diverse viewpoints and, even worse, leading to suboptimal generation results if the synthesized views are of poor quality. To address these limitations, we propose Flex3D, a novel two-stage framework capable of leveraging an arbitrary number of high-quality input views. The first stage consists of a candidate view generation and curation pipeline. We employ a fine-tuned multi-view image diffusion model and a video diffusion model to generate a pool of candidate views, enabling a rich representation of the target 3D object. Subsequently, a view selection pipeline filters these views based on quality and consistency, ensuring that only the high-quality and reliable views are used for reconstruction. In the second stage, the curated views are fed into a Flexible Reconstruction Model (FlexRM), built upon a transformer architecture that can effectively process an arbitrary number of inputs. FlemRM directly outputs 3D Gaussian points leveraging a tri-plane representation, enabling efficient and detailed 3D generation. Through extensive exploration of design and training strategies, we optimize FlexRM to achieve superior performance in both reconstruction and generation tasks. Our results demonstrate that Flex3D achieves state-of-the-art performance, with a user study winning rate of over 92% in 3D generation tasks when compared to several of the latest feed-forward 3D generative models.
CatFree3D: Category-agnostic 3D Object Detection with Diffusion
Aug 22, 2024



Image-based 3D object detection is widely employed in applications such as autonomous vehicles and robotics, yet current systems struggle with generalisation due to complex problem setup and limited training data. We introduce a novel pipeline that decouples 3D detection from 2D detection and depth prediction, using a diffusion-based approach to improve accuracy and support category-agnostic detection. Additionally, we introduce the Normalised Hungarian Distance (NHD) metric for an accurate evaluation of 3D detection results, addressing the limitations of traditional IoU and GIoU metrics. Experimental results demonstrate that our method achieves state-of-the-art accuracy and strong generalisation across various object categories and datasets.
3D-Aware Instance Segmentation and Tracking in Egocentric Videos
Aug 19, 2024



Egocentric videos present unique challenges for 3D scene understanding due to rapid camera motion, frequent object occlusions, and limited object visibility. This paper introduces a novel approach to instance segmentation and tracking in first-person video that leverages 3D awareness to overcome these obstacles. Our method integrates scene geometry, 3D object centroid tracking, and instance segmentation to create a robust framework for analyzing dynamic egocentric scenes. By incorporating spatial and temporal cues, we achieve superior performance compared to state-of-the-art 2D approaches. Extensive evaluations on the challenging EPIC Fields dataset demonstrate significant improvements across a range of tracking and segmentation consistency metrics. Specifically, our method outperforms the next best performing approach by $7$ points in Association Accuracy (AssA) and $4.5$ points in IDF1 score, while reducing the number of ID switches by $73\%$ to $80\%$ across various object categories. Leveraging our tracked instance segmentations, we showcase downstream applications in 3D object reconstruction and amodal video object segmentation in these egocentric settings.
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics
Aug 08, 2024



We present Puppet-Master, an interactive video generative model that can serve as a motion prior for part-level dynamics. At test time, given a single image and a sparse set of motion trajectories (i.e., drags), Puppet-Master can synthesize a video depicting realistic part-level motion faithful to the given drag interactions. This is achieved by fine-tuning a large-scale pre-trained video diffusion model, for which we propose a new conditioning architecture to inject the dragging control effectively. More importantly, we introduce the all-to-first attention mechanism, a drop-in replacement for the widely adopted spatial attention modules, which significantly improves generation quality by addressing the appearance and background issues in existing models. Unlike other motion-conditioned video generators that are trained on in-the-wild videos and mostly move an entire object, Puppet-Master is learned from Objaverse-Animation-HQ, a new dataset of curated part-level motion clips. We propose a strategy to automatically filter out sub-optimal animations and augment the synthetic renderings with meaningful motion trajectories. Puppet-Master generalizes well to real images across various categories and outperforms existing methods in a zero-shot manner on a real-world benchmark. See our project page for more results: vgg-puppetmaster.github.io.