 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Discovering and Learning New Visual Categories with Ranking Statistics
Feb 13, 2020
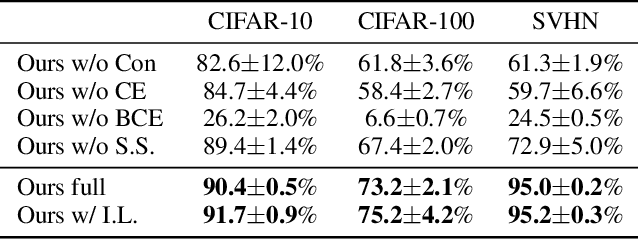
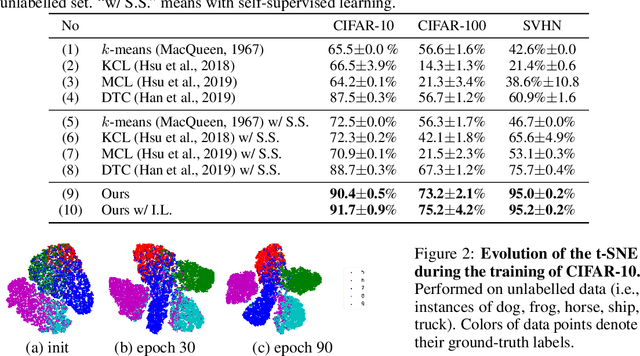
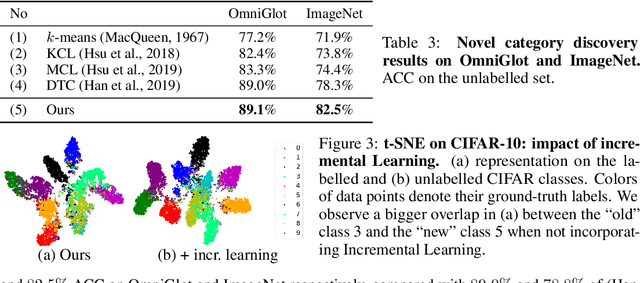
We tackle the problem of discovering novel classes in an image collection given labelled examples of other classes. This setting is similar to semi-supervised learning, but significantly harder because there are no labelled examples for the new classes. The challenge, then, is to leverage the information contained in the labelled images in order to learn a general-purpose clustering model and use the latter to identify the new classes in the unlabelled data. In this work we address this problem by combining three ideas: (1) we suggest that the common approach of bootstrapping an image representation using the labeled data only introduces an unwanted bias, and that this can be avoided by using self-supervised learning to train the representation from scratch on the union of labelled and unlabelled data; (2) we use rank statistics to transfer the model's knowledge of the labelled classes to the problem of clustering the unlabelled images; and, (3) we train the data representation by optimizing a joint objective function on the labelled and unlabelled subsets of the data, improving both the supervised classification of the labelled data, and the clustering of the unlabelled data. We evaluate our approach on standard classification benchmarks and outperform current methods for novel category discovery by a significant margin.
Self-labelling via simultaneous clustering and representation learning
Nov 26, 2019
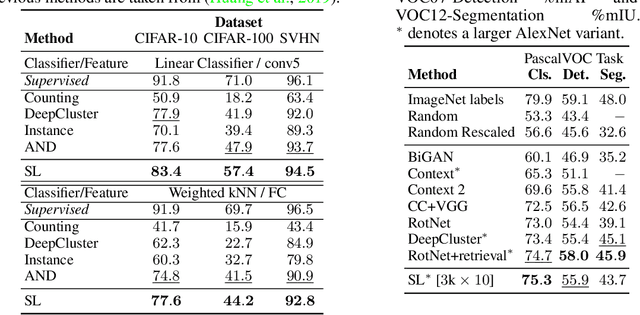
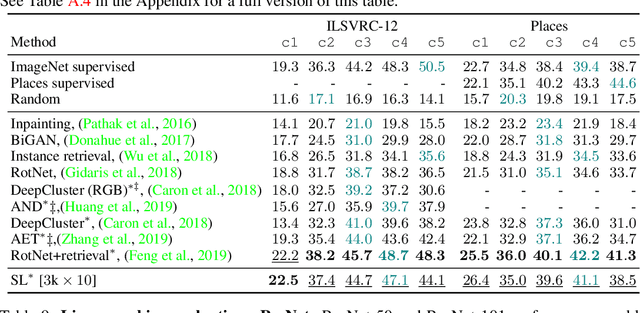
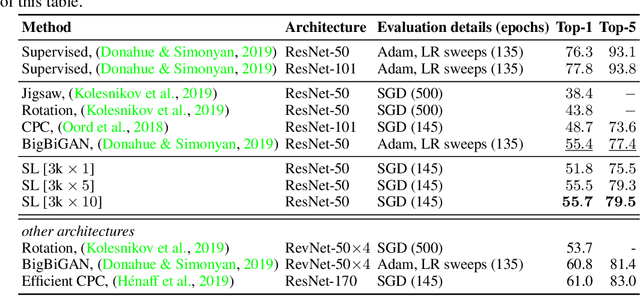
Combining clustering and representation learning is one of the most promising approaches for unsupervised learning of deep neural networks. However, doing so naively leads to ill posed learning problems with degenerate solutions. In this paper, we propose a novel and principled learning formulation that addresses these issues. The method is obtained by maximizing the information between labels and input data indices. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently for millions of input images and thousands of labels using a fast variant of the Sinkhorn-Knopp algorithm. The resulting method is able to self-label visual data so as to train highly competitive image representations without manual labels. Our method achieves state of the art representation learning performance for AlexNet and ResNet-50 on SVHN, CIFAR-10, CIFAR-100 and ImageNet.
Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
Nov 25, 2019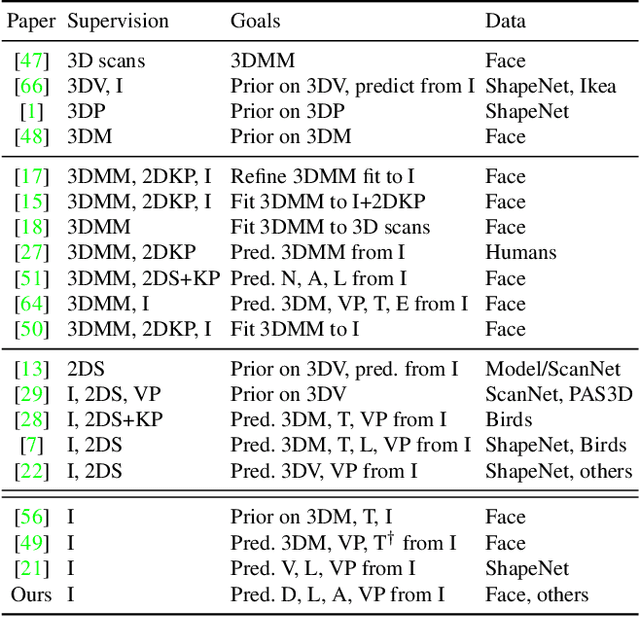
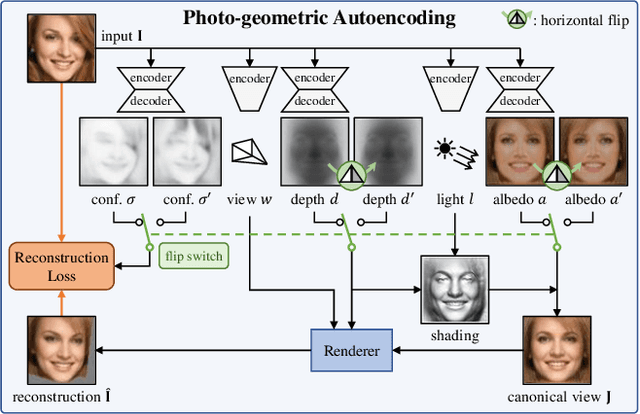
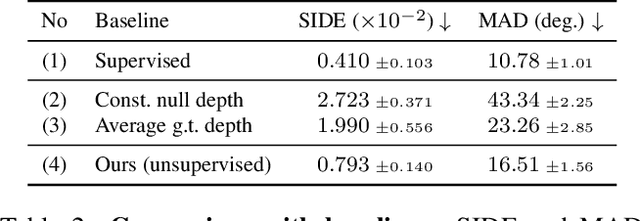
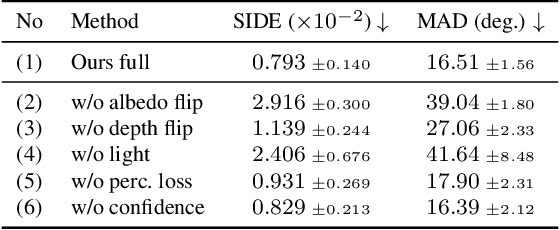
We propose a method to learn 3D deformable object categories from raw single-view images, without external supervision. The method is based on an autoencoder that factors each input image into depth, albedo, viewpoint and illumination. In order to disentangle these components without supervision, we use the fact that many object categories have, at least in principle, a symmetric structure. We show that reasoning about illumination allows us to exploit the underlying object symmetry even if the appearance is not symmetric due to shading. Furthermore, we model objects that are probably, but not certainly, symmetric by predicting a symmetry probability map, learned end-to-end with the other components of the model. Our experiments show that this method can recover very accurately the 3D shape of human faces, cat faces and cars from single-view images, without any supervision or a prior shape model. On benchmarks, we demonstrate superior accuracy compared to another method that uses supervision at the level of 2D image correspondences.
Occlusions for Effective Data Augmentation in Image Classification
Oct 25, 2019
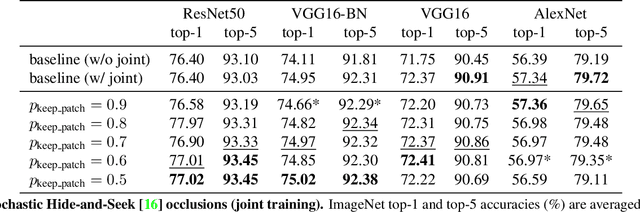

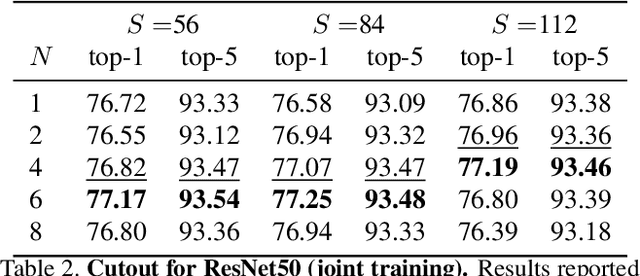
Deep networks for visual recognition are known to leverage "easy to recognise" portions of objects such as faces and distinctive texture patterns. The lack of a holistic understanding of objects may increase fragility and overfitting. In recent years, several papers have proposed to address this issue by means of occlusions as a form of data augmentation. However, successes have been limited to tasks such as weak localization and model interpretation, but no benefit was demonstrated on image classification on large-scale datasets. In this paper, we show that, by using a simple technique based on batch augmentation, occlusions as data augmentation can result in better performance on ImageNet for high-capacity models (e.g., ResNet50). We also show that varying amounts of occlusions used during training can be used to study the robustness of different neural network architectures.
NormGrad: Finding the Pixels that Matter for Training
Oct 19, 2019

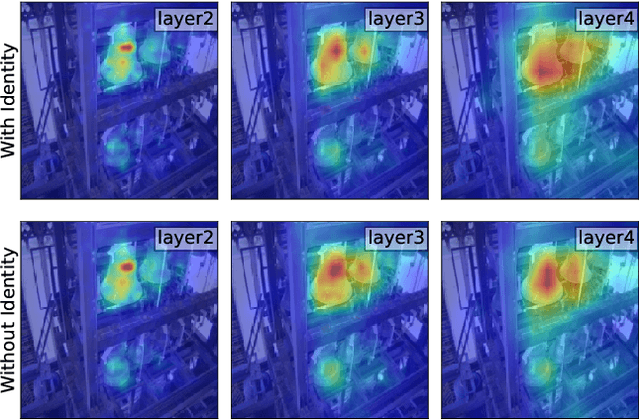
The different families of saliency methods, either based on contrastive signals, closed-form formulas mixing gradients with activations or on perturbation masks, all focus on which parts of an image are responsible for the model's inference. In this paper, we are rather interested by the locations of an image that contribute to the model's training. First, we propose a principled attribution method that we extract from the summation formula used to compute the gradient of the weights for a 1x1 convolutional layer. The resulting formula is fast to compute and can used throughout the network, allowing us to efficiently produce fined-grained importance maps. We will show how to extend it in order to compute saliency maps at any targeted point within the network. Secondly, to make the attribution really specific to the training of the model, we introduce a meta-learning approach for saliency methods by considering an inner optimisation step within the loss. This way, we do not aim at identifying the parts of an image that contribute to the model's output but rather the locations that are responsible for the good training of the model on this image. Conversely, we also show that a similar meta-learning approach can be used to extract the adversarial locations which can lead to the degradation of the model.
Understanding Deep Networks via Extremal Perturbations and Smooth Masks
Oct 18, 2019
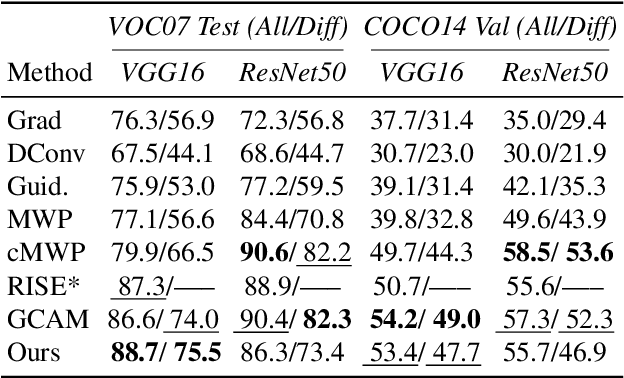
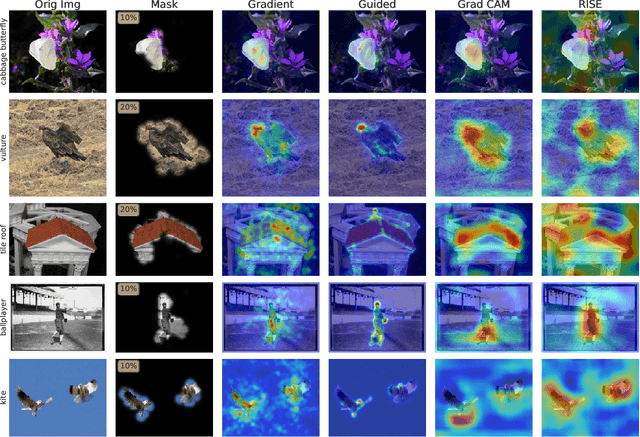

The problem of attribution is concerned with identifying the parts of an input that are responsible for a model's output. An important family of attribution methods is based on measuring the effect of perturbations applied to the input. In this paper, we discuss some of the shortcomings of existing approaches to perturbation analysis and address them by introducing the concept of extremal perturbations, which are theoretically grounded and interpretable. We also introduce a number of technical innovations to compute extremal perturbations, including a new area constraint and a parametric family of smooth perturbations, which allow us to remove all tunable hyper-parameters from the optimization problem. We analyze the effect of perturbations as a function of their area, demonstrating excellent sensitivity to the spatial properties of the deep neural network under stimulation. We also extend perturbation analysis to the intermediate layers of a network. This application allows us to identify the salient channels necessary for classification, which, when visualized using feature inversion, can be used to elucidate model behavior. Lastly, we introduce TorchRay, an interpretability library built on PyTorch.
C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion
Oct 15, 2019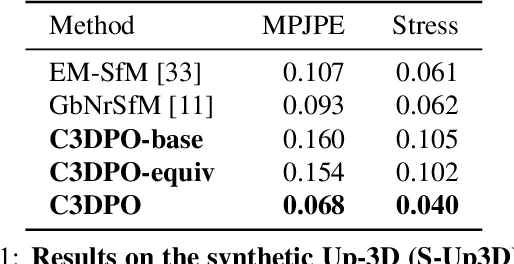
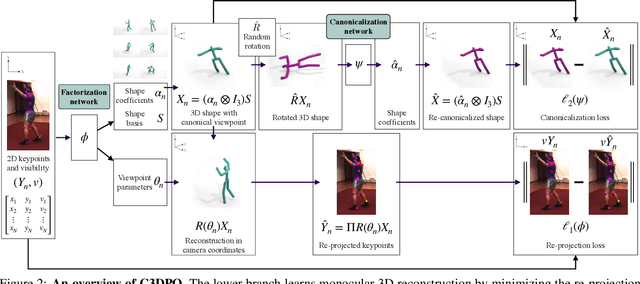
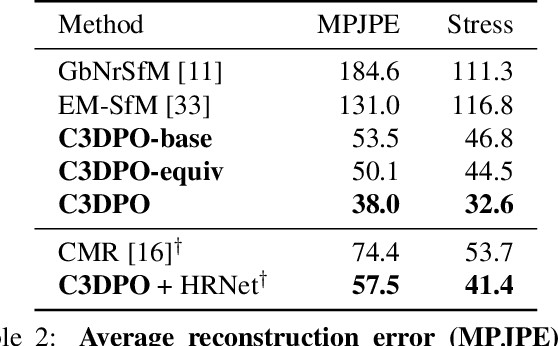
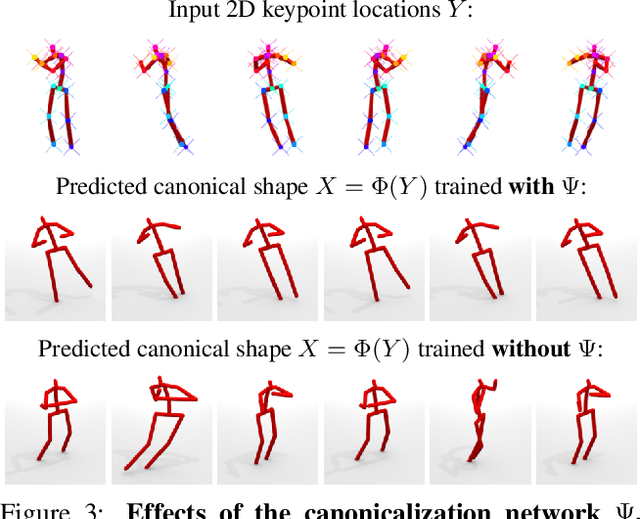
We propose C3DPO, a method for extracting 3D models of deformable objects from 2D keypoint annotations in unconstrained images. We do so by learning a deep network that reconstructs a 3D object from a single view at a time, accounting for partial occlusions, and explicitly factoring the effects of viewpoint changes and object deformations. In order to achieve this factorization, we introduce a novel regularization technique. We first show that the factorization is successful if, and only if, there exists a certain canonicalization function of the reconstructed shapes. Then, we learn the canonicalization function together with the reconstruction one, which constrains the result to be consistent. We demonstrate state-of-the-art reconstruction results for methods that do not use ground-truth 3D supervision for a number of benchmarks, including Up3D and PASCAL3D+. Source code has been made available at https://github.com/facebookresearch/c3dpo_nrsfm.
* Added a link to the source code into the abstract
Learning to Discover Novel Visual Categories via Deep Transfer Clustering
Aug 26, 2019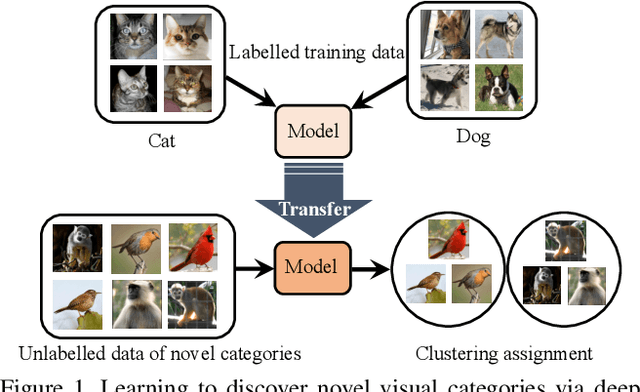
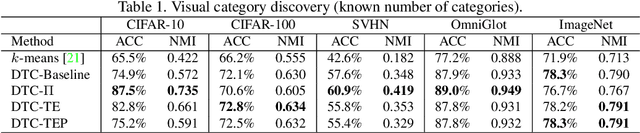

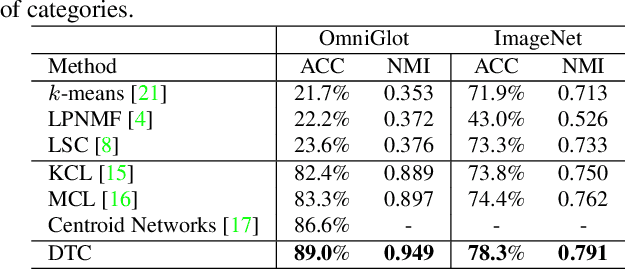
We consider the problem of discovering novel object categories in an image collection. While these images are unlabelled, we also assume prior knowledge of related but different image classes. We use such prior knowledge to reduce the ambiguity of clustering, and improve the quality of the newly discovered classes. Our contributions are twofold. The first contribution is to extend Deep Embedded Clustering to a transfer learning setting; we also improve the algorithm by introducing a representation bottleneck, temporal ensembling, and consistency. The second contribution is a method to estimate the number of classes in the unlabelled data. This also transfers knowledge from the known classes, using them as probes to diagnose different choices for the number of classes in the unlabelled subset. We thoroughly evaluate our method, substantially outperforming state-of-the-art techniques in a large number of benchmarks, including ImageNet, OmniGlot, CIFAR-100, CIFAR-10, and SVHN.
Unsupervised Learning of Landmarks by Descriptor Vector Exchange
Aug 18, 2019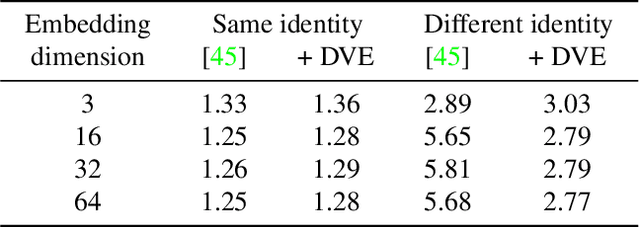
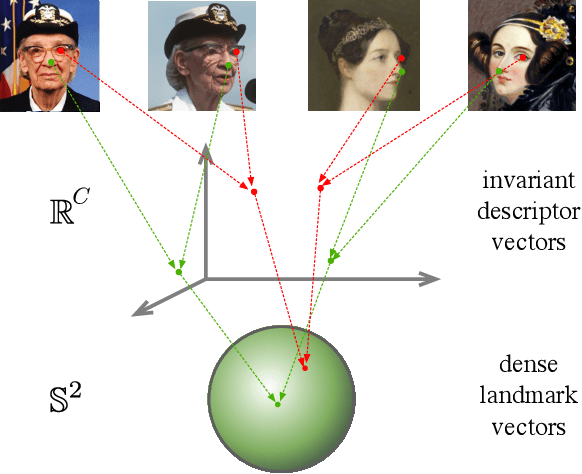
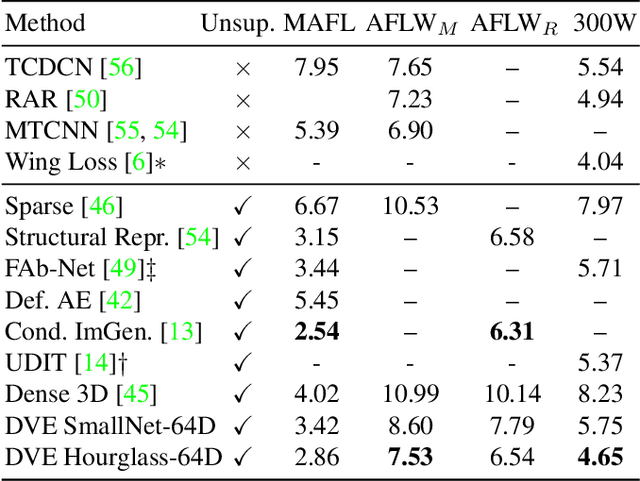
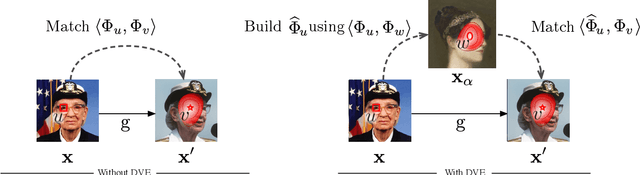
Equivariance to random image transformations is an effective method to learn landmarks of object categories, such as the eyes and the nose in faces, without manual supervision. However, this method does not explicitly guarantee that the learned landmarks are consistent with changes between different instances of the same object, such as different facial identities. In this paper, we develop a new perspective on the equivariance approach by noting that dense landmark detectors can be interpreted as local image descriptors equipped with invariance to intra-category variations. We then propose a direct method to enforce such an invariance in the standard equivariant loss. We do so by exchanging descriptor vectors between images of different object instances prior to matching them geometrically. In this manner, the same vectors must work regardless of the specific object identity considered. We use this approach to learn vectors that can simultaneously be interpreted as local descriptors and dense landmarks, combining the advantages of both. Experiments on standard benchmarks show that this approach can match, and in some cases surpass state-of-the-art performance amongst existing methods that learn landmarks without supervision. Code is available at www.robots.ox.ac.uk/~vgg/research/DVE/.
AutoCorrect: Deep Inductive Alignment of Noisy Geometric Annotations
Aug 14, 2019
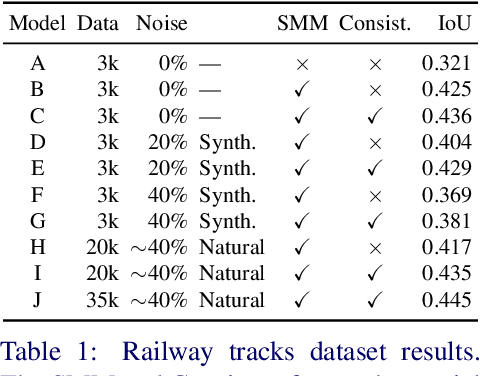
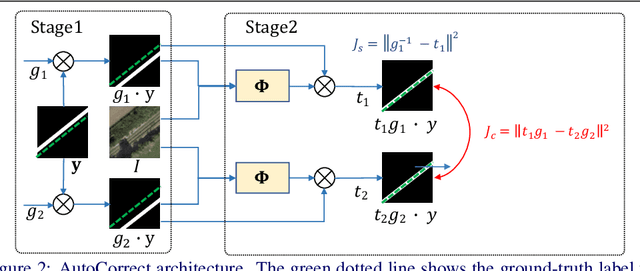
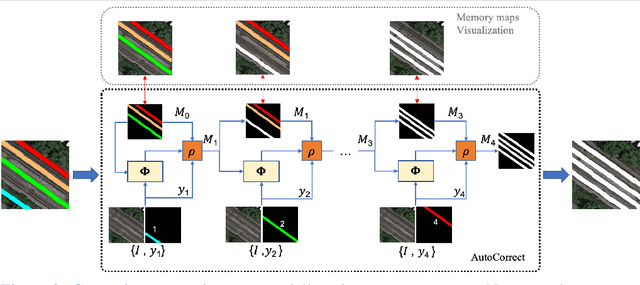
We propose AutoCorrect, a method to automatically learn object-annotation alignments from a dataset with annotations affected by geometric noise. The method is based on a consistency loss that enables deep neural networks to be trained, given only noisy annotations as input, to correct the annotations. When some noise-free annotations are available, we show that the consistency loss reduces to a stricter self-supervised loss. We also show that the method can implicitly leverage object symmetries to reduce the ambiguity arising in correcting noisy annotations. When multiple object-annotation pairs are present in an image, we introduce a spatial memory map that allows the network to correct annotations sequentially, one at a time, while accounting for all other annotations in the image and corrections performed so far. Through ablation, we show the benefit of these contributions, demonstrating excellent results on geo-spatial imagery. Specifically, we show results using a new Railway tracks dataset as well as the public INRIA Buildings benchmarks, achieving new state-of-the-art results for the latter.