 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjected Latent Distillation for Data-Agnostic Consolidation in Distributed Continual Learning
Mar 28, 2023



Distributed learning on the edge often comprises self-centered devices (SCD) which learn local tasks independently and are unwilling to contribute to the performance of other SDCs. How do we achieve forward transfer at zero cost for the single SCDs? We formalize this problem as a Distributed Continual Learning scenario, where SCD adapt to local tasks and a CL model consolidates the knowledge from the resulting stream of models without looking at the SCD's private data. Unfortunately, current CL methods are not directly applicable to this scenario. We propose Data-Agnostic Consolidation (DAC), a novel double knowledge distillation method that consolidates the stream of SC models without using the original data. DAC performs distillation in the latent space via a novel Projected Latent Distillation loss. Experimental results show that DAC enables forward transfer between SCDs and reaches state-of-the-art accuracy on Split CIFAR100, CORe50 and Split TinyImageNet, both in reharsal-free and distributed CL scenarios. Somewhat surprisingly, even a single out-of-distribution image is sufficient as the only source of data during consolidation.
Avalanche: A PyTorch Library for Deep Continual Learning
Feb 02, 2023

Continual learning is the problem of learning from a nonstationary stream of data, a fundamental issue for sustainable and efficient training of deep neural networks over time. Unfortunately, deep learning libraries only provide primitives for offline training, assuming that model's architecture and data are fixed. Avalanche is an open source library maintained by the ContinualAI non-profit organization that extends PyTorch by providing first-class support for dynamic architectures, streams of datasets, and incremental training and evaluation methods. Avalanche provides a large set of predefined benchmarks and training algorithms and it is easy to extend and modular while supporting a wide range of continual learning scenarios. Documentation is available at \url{https://avalanche.continualai.org}.
Class-Incremental Learning with Repetition
Jan 26, 2023



Real-world data streams naturally include the repetition of previous concepts. From a Continual Learning (CL) perspective, repetition is a property of the environment and, unlike replay, cannot be controlled by the user. Nowadays, Class-Incremental scenarios represent the leading test-bed for assessing and comparing CL strategies. This family of scenarios is very easy to use, but it never allows revisiting previously seen classes, thus completely disregarding the role of repetition. We focus on the family of Class-Incremental with Repetition (CIR) scenarios, where repetition is embedded in the definition of the stream. We propose two stochastic scenario generators that produce a wide range of CIR scenarios starting from a single dataset and a few control parameters. We conduct the first comprehensive evaluation of repetition in CL by studying the behavior of existing CL strategies under different CIR scenarios. We then present a novel replay strategy that exploits repetition and counteracts the natural imbalance present in the stream. On both CIFAR100 and TinyImageNet, our strategy outperforms other replay approaches, which are not designed for environments with repetition.
Continual Learning for Human State Monitoring
Jun 29, 2022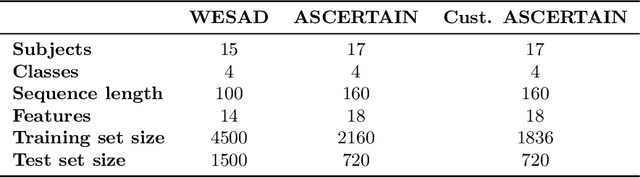
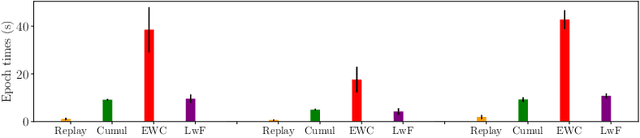
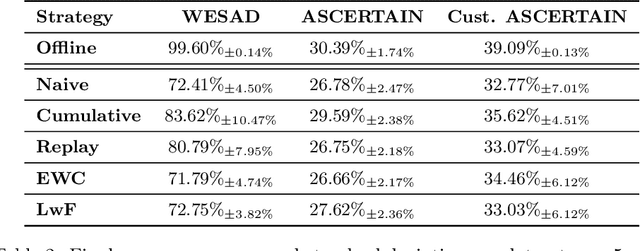
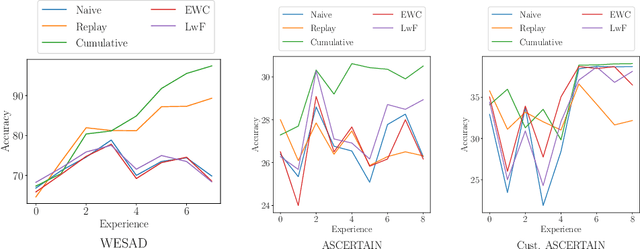
Continual Learning (CL) on time series data represents a promising but under-studied avenue for real-world applications. We propose two new CL benchmarks for Human State Monitoring. We carefully designed the benchmarks to mirror real-world environments in which new subjects are continuously added. We conducted an empirical evaluation to assess the ability of popular CL strategies to mitigate forgetting in our benchmarks. Our results show that, possibly due to the domain-incremental properties of our benchmarks, forgetting can be easily tackled even with a simple finetuning and that existing strategies struggle in accumulating knowledge over a fixed, held-out, test subject.
Sample Condensation in Online Continual Learning
Jun 23, 2022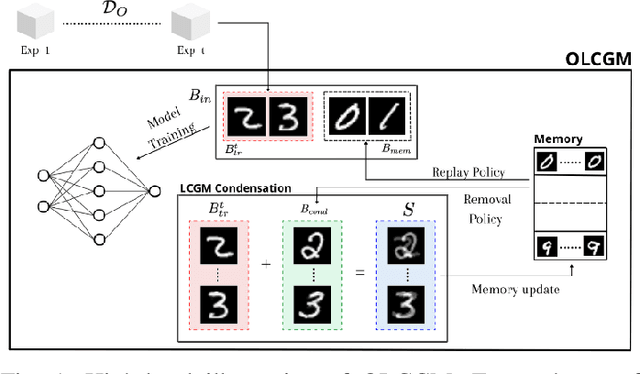


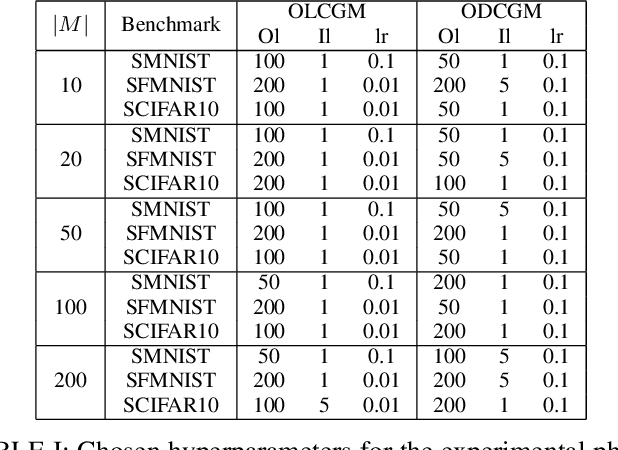
Online Continual learning is a challenging learning scenario where the model must learn from a non-stationary stream of data where each sample is seen only once. The main challenge is to incrementally learn while avoiding catastrophic forgetting, namely the problem of forgetting previously acquired knowledge while learning from new data. A popular solution in these scenario is to use a small memory to retain old data and rehearse them over time. Unfortunately, due to the limited memory size, the quality of the memory will deteriorate over time. In this paper we propose OLCGM, a novel replay-based continual learning strategy that uses knowledge condensation techniques to continuously compress the memory and achieve a better use of its limited size. The sample condensation step compresses old samples, instead of removing them like other replay strategies. As a result, the experiments show that, whenever the memory budget is limited compared to the complexity of the data, OLCGM improves the final accuracy compared to state-of-the-art replay strategies.
Continual Pre-Training Mitigates Forgetting in Language and Vision
May 19, 2022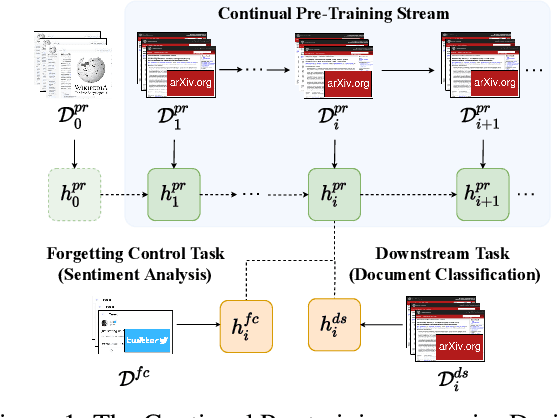
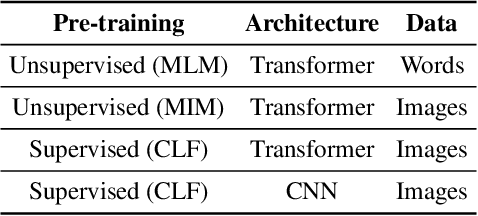
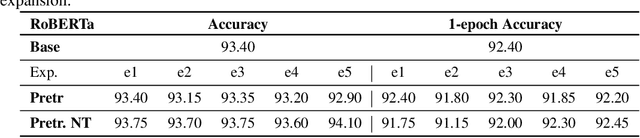
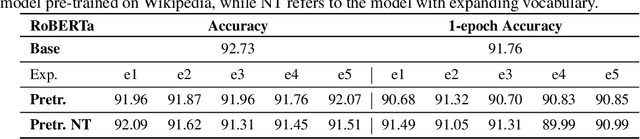
Pre-trained models are nowadays a fundamental component of machine learning research. In continual learning, they are commonly used to initialize the model before training on the stream of non-stationary data. However, pre-training is rarely applied during continual learning. We formalize and investigate the characteristics of the continual pre-training scenario in both language and vision environments, where a model is continually pre-trained on a stream of incoming data and only later fine-tuned to different downstream tasks. We show that continually pre-trained models are robust against catastrophic forgetting and we provide strong empirical evidence supporting the fact that self-supervised pre-training is more effective in retaining previous knowledge than supervised protocols. Code is provided at https://github.com/AndreaCossu/continual-pretraining-nlp-vision .
Practical Recommendations for Replay-based Continual Learning Methods
Mar 19, 2022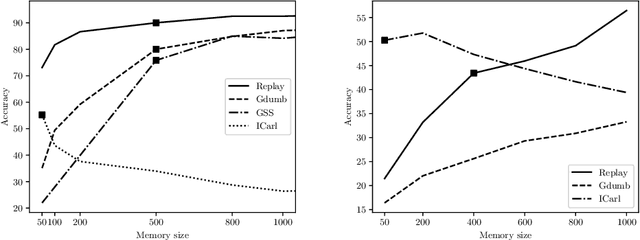
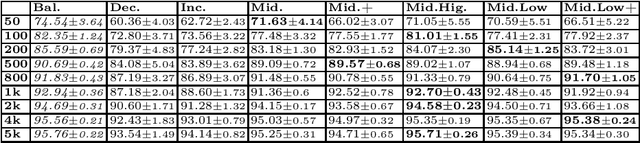
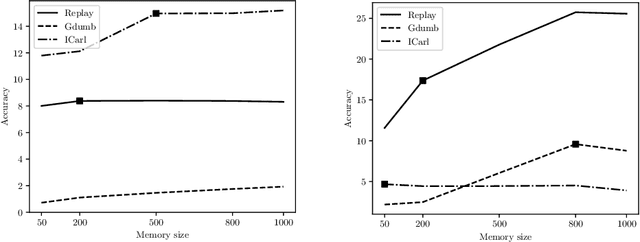

Continual Learning requires the model to learn from a stream of dynamic, non-stationary data without forgetting previous knowledge. Several approaches have been developed in the literature to tackle the Continual Learning challenge. Among them, Replay approaches have empirically proved to be the most effective ones. Replay operates by saving some samples in memory which are then used to rehearse knowledge during training in subsequent tasks. However, an extensive comparison and deeper understanding of different replay implementation subtleties is still missing in the literature. The aim of this work is to compare and analyze existing replay-based strategies and provide practical recommendations on developing efficient, effective and generally applicable replay-based strategies. In particular, we investigate the role of the memory size value, different weighting policies and discuss about the impact of data augmentation, which allows reaching better performance with lower memory sizes.
Ex-Model: Continual Learning from a Stream of Trained Models
Dec 13, 2021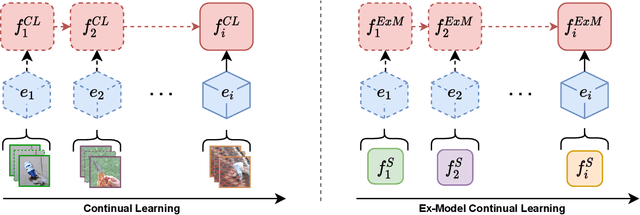
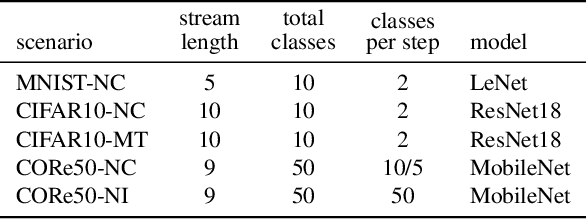
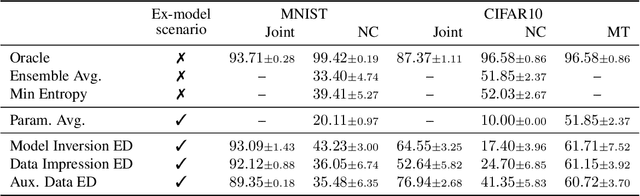

Learning continually from non-stationary data streams is a challenging research topic of growing popularity in the last few years. Being able to learn, adapt, and generalize continually in an efficient, effective, and scalable way is fundamental for a sustainable development of Artificial Intelligent systems. However, an agent-centric view of continual learning requires learning directly from raw data, which limits the interaction between independent agents, the efficiency, and the privacy of current approaches. Instead, we argue that continual learning systems should exploit the availability of compressed information in the form of trained models. In this paper, we introduce and formalize a new paradigm named "Ex-Model Continual Learning" (ExML), where an agent learns from a sequence of previously trained models instead of raw data. We further contribute with three ex-model continual learning algorithms and an empirical setting comprising three datasets (MNIST, CIFAR-10 and CORe50), and eight scenarios, where the proposed algorithms are extensively tested. Finally, we highlight the peculiarities of the ex-model paradigm and we point out interesting future research directions.
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021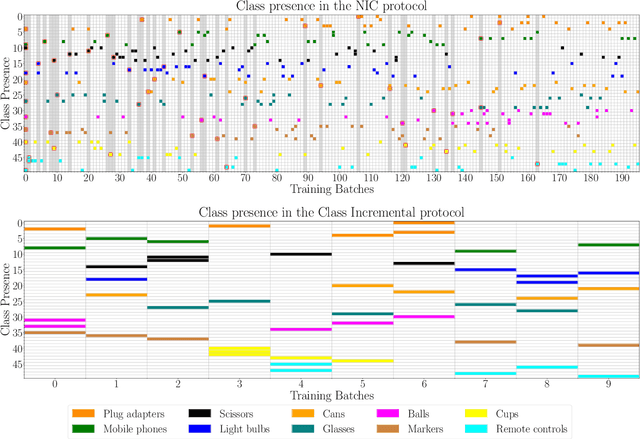
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Sustainable Artificial Intelligence through Continual Learning
Nov 17, 2021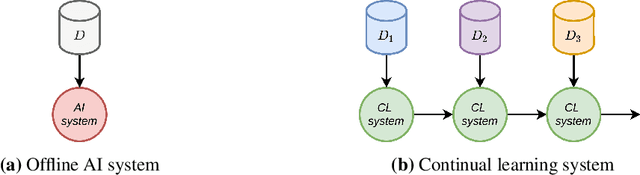
The increasing attention on Artificial Intelligence (AI) regulation has led to the definition of a set of ethical principles grouped into the Sustainable AI framework. In this article, we identify Continual Learning, an active area of AI research, as a promising approach towards the design of systems compliant with the Sustainable AI principles. While Sustainable AI outlines general desiderata for ethical applications, Continual Learning provides means to put such desiderata into practice.