 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Independent Frames: Latent Attention Masked Autoencoders for Multi-View Echocardiography
Apr 16, 2026Echocardiography is a widely used modality for cardiac assessment due to its non-invasive and cost-effective nature, but the sparse and heterogeneous spatiotemporal views of the heart pose distinct challenges. Existing masked autoencoder (MAE) approaches typically process images or short clips independently, failing to capture the inherent multi-view structure required for coherent cardiac representation. We introduce Latent Attention Masked Autoencoder (LAMAE), a foundation model architecture tailored to the multi-view nature of medical imaging. LAMAE augments the standard MAE with a latent attention module that enables information exchange across frames and views directly in latent space. This allows the model to aggregate variable-length sequences and distinct views, reconstructing a holistic representation of cardiac function from partial observations. We pretrain LAMAE on MIMIC-IV-ECHO, a large-scale, uncurated dataset reflecting real-world clinical variability. To the best of our knowledge, we present the first results for predicting ICD-10 codes from MIMIC-IV-ECHO videos. Furthermore, we empirically demonstrate that representations learned from adult data transfer effectively to pediatric cohorts despite substantial anatomical differences. These results provide evidence that incorporating structural priors, such as multi-view attention, yields significantly more robust and transferable representations.
Foundation Model for Cardiac Time Series via Masked Latent Attention
Mar 27, 2026Electrocardiograms (ECGs) are among the most widely available clinical signals and play a central role in cardiovascular diagnosis. While recent foundation models (FMs) have shown promise for learning transferable ECG representations, most existing pretraining approaches treat leads as independent channels and fail to explicitly leverage their strong structural redundancy. We introduce the latent attention masked autoencoder (LAMAE) FM that directly exploits this structure by learning cross-lead connection mechanisms during self-supervised pretraining. Our approach models higher-order interactions across leads through latent attention, enabling permutation-invariant aggregation and adaptive weighting of lead-specific representations. We provide empirical evidence on the Mimic-IV-ECG database that leveraging the cross-lead connection constitutes an effective form of structural supervision, improving representation quality and transferability. Our method shows strong performance in predicting ICD-10 codes, outperforming independent-lead masked modeling and alignment-based baselines.
* First two authors are co-first. Last two authors are co-senior
Weakly-Supervised Multimodal Learning on MIMIC-CXR
Nov 15, 2024



Multimodal data integration and label scarcity pose significant challenges for machine learning in medical settings. To address these issues, we conduct an in-depth evaluation of the newly proposed Multimodal Variational Mixture-of-Experts (MMVM) VAE on the challenging MIMIC-CXR dataset. Our analysis demonstrates that the MMVM VAE consistently outperforms other multimodal VAEs and fully supervised approaches, highlighting its strong potential for real-world medical applications.
Multi-Armed Bandit Problem with Temporally-Partitioned Rewards: When Partial Feedback Counts
Jun 01, 2022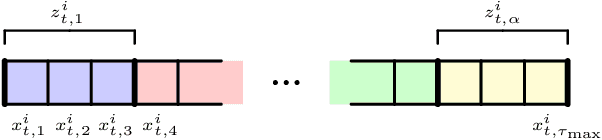
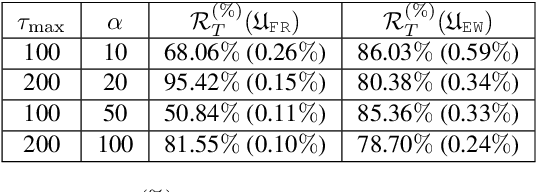
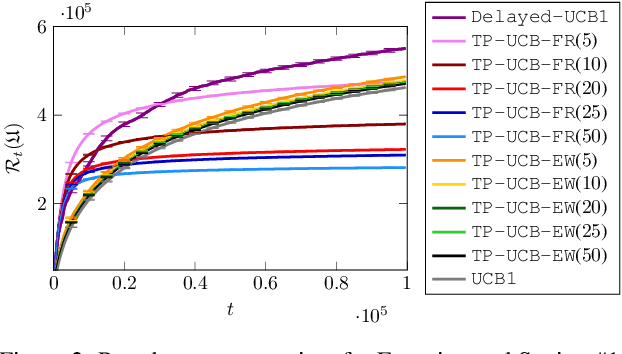
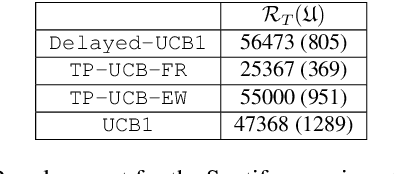
There is a rising interest in industrial online applications where data becomes available sequentially. Inspired by the recommendation of playlists to users where their preferences can be collected during the listening of the entire playlist, we study a novel bandit setting, namely Multi-Armed Bandit with Temporally-Partitioned Rewards (TP-MAB), in which the stochastic reward associated with the pull of an arm is partitioned over a finite number of consecutive rounds following the pull. This setting, unexplored so far to the best of our knowledge, is a natural extension of delayed-feedback bandits to the case in which rewards may be dilated over a finite-time span after the pull instead of being fully disclosed in a single, potentially delayed round. We provide two algorithms to address TP-MAB problems, namely, TP-UCB-FR and TP-UCB-EW, which exploit the partial information disclosed by the reward collected over time. We show that our algorithms provide better asymptotical regret upper bounds than delayed-feedback bandit algorithms when a property characterizing a broad set of reward structures of practical interest, namely alpha-smoothness, holds. We also empirically evaluate their performance across a wide range of settings, both synthetically generated and from a real-world media recommendation problem.