 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Policy Composition with Generalized Policy Improvement and Divergence Correction
Dec 05, 2018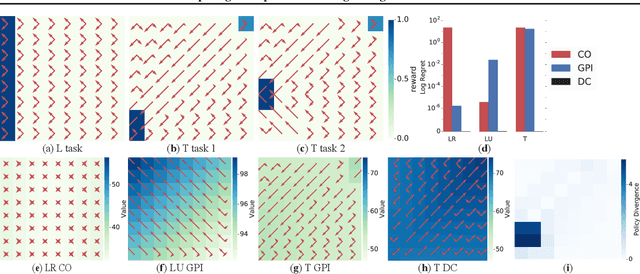

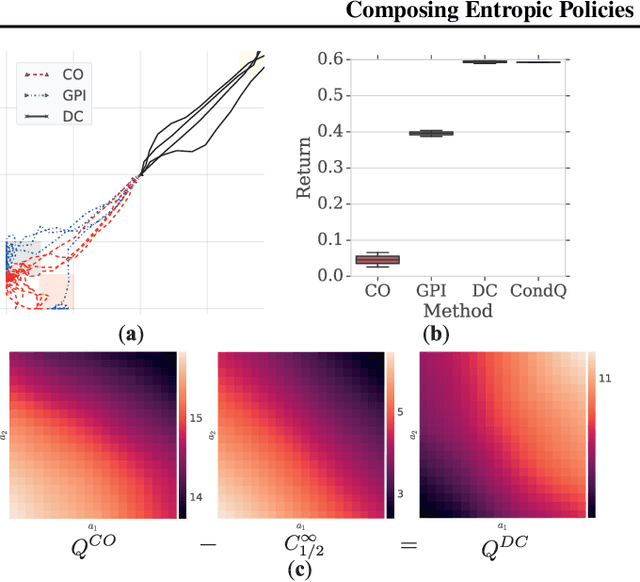

Deep reinforcement learning (RL) algorithms have made great strides in recent years. An important remaining challenge is the ability to quickly transfer existing skills to novel tasks, and to combine existing skills with newly acquired ones. In domains where tasks are solved by composing skills this capacity holds the promise of dramatically reducing the data requirements of deep RL algorithms, and hence increasing their applicability. Recent work has studied ways of composing behaviors represented in the form of action-value functions. We analyze these methods to highlight their strengths and weaknesses, and point out situations where each of them is susceptible to poor performance. To perform this analysis we extend generalized policy improvement to the max-entropy framework and introduce a method for the practical implementation of successor features in continuous action spaces. Then we propose a novel approach which, in principle, recovers the optimal policy during transfer. This method works by explicitly learning the (discounted, future) divergence between policies. We study this approach in the tabular case and propose a scalable variant that is applicable in multi-dimensional continuous action spaces. We compare our approach with existing ones on a range of non-trivial continuous control problems with compositional structure, and demonstrate qualitatively better performance despite not requiring simultaneous observation of all task rewards.
Temporal Difference Learning with Neural Networks - Study of the Leakage Propagation Problem
Jul 09, 2018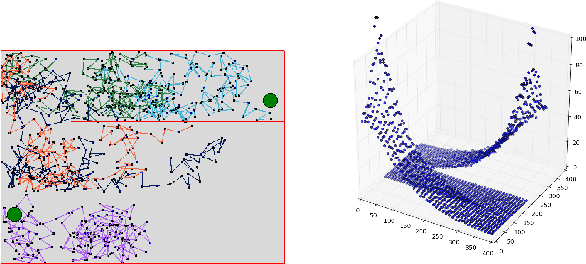
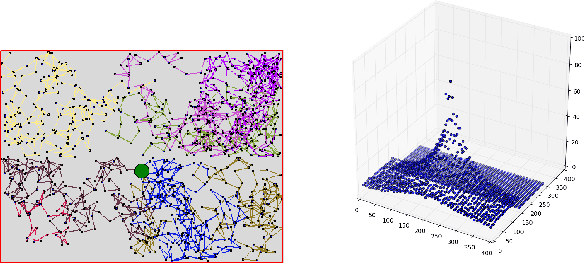
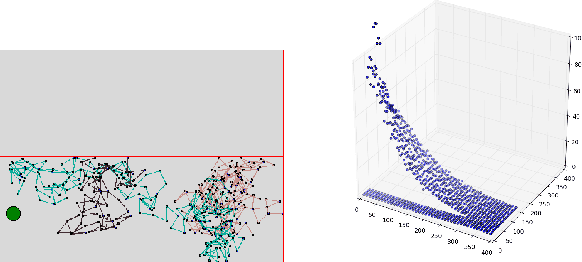
Temporal-Difference learning (TD) [Sutton, 1988] with function approximation can converge to solutions that are worse than those obtained by Monte-Carlo regression, even in the simple case of on-policy evaluation. To increase our understanding of the problem, we investigate the issue of approximation errors in areas of sharp discontinuities of the value function being further propagated by bootstrap updates. We show empirical evidence of this leakage propagation, and show analytically that it must occur, in a simple Markov chain, when function approximation errors are present. For reversible policies, the result can be interpreted as the tension between two terms of the loss function that TD minimises, as recently described by [Ollivier, 2018]. We show that the upper bounds from [Tsitsiklis and Van Roy, 1997] hold, but they do not imply that leakage propagation occurs and under what conditions. Finally, we test whether the problem could be mitigated with a better state representation, and whether it can be learned in an unsupervised manner, without rewards or privileged information.
The Predictron: End-To-End Learning and Planning
Jul 20, 2017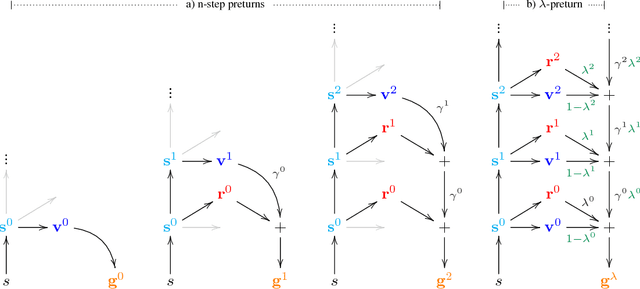

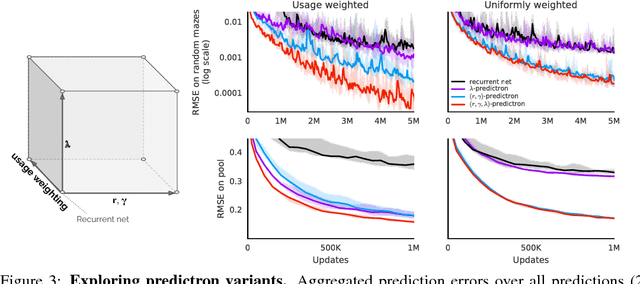
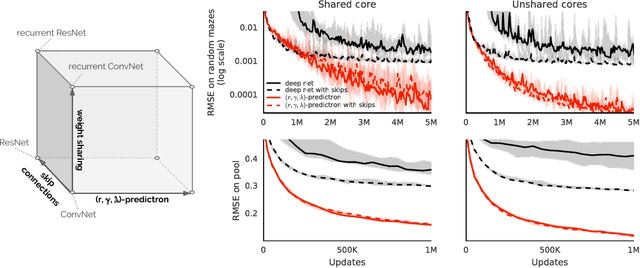
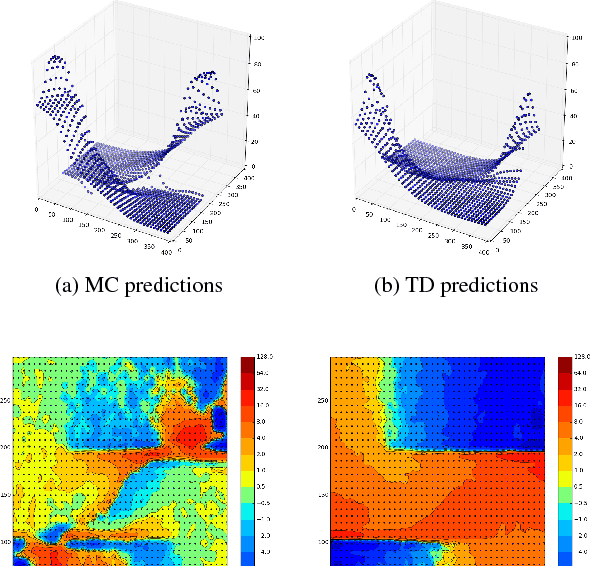
One of the key challenges of artificial intelligence is to learn models that are effective in the context of planning. In this document we introduce the predictron architecture. The predictron consists of a fully abstract model, represented by a Markov reward process, that can be rolled forward multiple "imagined" planning steps. Each forward pass of the predictron accumulates internal rewards and values over multiple planning depths. The predictron is trained end-to-end so as to make these accumulated values accurately approximate the true value function. We applied the predictron to procedurally generated random mazes and a simulator for the game of pool. The predictron yielded significantly more accurate predictions than conventional deep neural network architectures.