 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decade-Scale Benchmark Evaluating LLMs' Clinical Practice Guidelines Detection and Adherence in Multi-turn Conversations
Mar 26, 2026Clinical practice guidelines (CPGs) play a pivotal role in ensuring evidence-based decision-making and improving patient outcomes. While Large Language Models (LLMs) are increasingly deployed in healthcare scenarios, it is unclear to which extend LLMs could identify and adhere to CPGs during conversations. To address this gap, we introduce CPGBench, an automated framework benchmarking the clinical guideline detection and adherence capabilities of LLMs in multi-turn conversations. We collect 3,418 CPG documents from 9 countries/regions and 2 international organizations published in the last decade spanning across 24 specialties. From these documents, we extract 32,155 clinical recommendations with corresponding publication institute, date, country, specialty, recommendation strength, evidence level, etc. One multi-turn conversation is generated for each recommendation accordingly to evaluate the detection and adherence capabilities of 8 leading LLMs. We find that the 71.1%-89.6% recommendations can be correctly detected, while only 3.6%-29.7% corresponding titles can be correctly referenced, revealing the gap between knowing the guideline contents and where they come from. The adherence rates range from 21.8% to 63.2% in different models, indicating a large gap between knowing the guidelines and being able to apply them. To confirm the validity of our automatic analysis, we further conduct a comprehensive human evaluation involving 56 clinicians from different specialties. To our knowledge, CPGBench is the first benchmark systematically revealing which clinical recommendations LLMs fail to detect or adhere to during conversations. Given that each clinical recommendation may affect a large population and that clinical applications are inherently safety critical, addressing these gaps is crucial for the safe and responsible deployment of LLMs in real world clinical practice.
Self-eXplainable AI for Medical Image Analysis: A Survey and New Outlooks
Oct 03, 2024



The increasing demand for transparent and reliable models, particularly in high-stakes decision-making areas such as medical image analysis, has led to the emergence of eXplainable Artificial Intelligence (XAI). Post-hoc XAI techniques, which aim to explain black-box models after training, have been controversial in recent works concerning their fidelity to the models' predictions. In contrast, Self-eXplainable AI (S-XAI) offers a compelling alternative by incorporating explainability directly into the training process of deep learning models. This approach allows models to generate inherent explanations that are closely aligned with their internal decision-making processes. Such enhanced transparency significantly supports the trustworthiness, robustness, and accountability of AI systems in real-world medical applications. To facilitate the development of S-XAI methods for medical image analysis, this survey presents an comprehensive review across various image modalities and clinical applications. It covers more than 200 papers from three key perspectives: 1) input explainability through the integration of explainable feature engineering and knowledge graph, 2) model explainability via attention-based learning, concept-based learning, and prototype-based learning, and 3) output explainability by providing counterfactual explanation and textual explanation. Additionally, this paper outlines the desired characteristics of explainability and existing evaluation methods for assessing explanation quality. Finally, it discusses the major challenges and future research directions in developing S-XAI for medical image analysis.
Explain via Any Concept: Concept Bottleneck Model with Open Vocabulary Concepts
Aug 05, 2024



The concept bottleneck model (CBM) is an interpretable-by-design framework that makes decisions by first predicting a set of interpretable concepts, and then predicting the class label based on the given concepts. Existing CBMs are trained with a fixed set of concepts (concepts are either annotated by the dataset or queried from language models). However, this closed-world assumption is unrealistic in practice, as users may wonder about the role of any desired concept in decision-making after the model is deployed. Inspired by the large success of recent vision-language pre-trained models such as CLIP in zero-shot classification, we propose "OpenCBM" to equip the CBM with open vocabulary concepts via: (1) Aligning the feature space of a trainable image feature extractor with that of a CLIP's image encoder via a prototype based feature alignment; (2) Simultaneously training an image classifier on the downstream dataset; (3) Reconstructing the trained classification head via any set of user-desired textual concepts encoded by CLIP's text encoder. To reveal potentially missing concepts from users, we further propose to iteratively find the closest concept embedding to the residual parameters during the reconstruction until the residual is small enough. To the best of our knowledge, our "OpenCBM" is the first CBM with concepts of open vocabularies, providing users the unique benefit such as removing, adding, or replacing any desired concept to explain the model's prediction even after a model is trained. Moreover, our model significantly outperforms the previous state-of-the-art CBM by 9% in the classification accuracy on the benchmark dataset CUB-200-2011.
Post-hoc Part-prototype Networks
Jun 05, 2024



Post-hoc explainability methods such as Grad-CAM are popular because they do not influence the performance of a trained model. However, they mainly reveal "where" a model looks at for a given input, fail to explain "what" the model looks for (e.g., what is important to classify a bird image to a Scott Oriole?). Existing part-prototype networks leverage part-prototypes (e.g., characteristic Scott Oriole's wing and head) to answer both "where" and "what", but often under-perform their black box counterparts in the accuracy. Therefore, a natural question is: can one construct a network that answers both "where" and "what" in a post-hoc manner to guarantee the model's performance? To this end, we propose the first post-hoc part-prototype network via decomposing the classification head of a trained model into a set of interpretable part-prototypes. Concretely, we propose an unsupervised prototype discovery and refining strategy to obtain prototypes that can precisely reconstruct the classification head, yet being interpretable. Besides guaranteeing the performance, we show that our network offers more faithful explanations qualitatively and yields even better part-prototypes quantitatively than prior part-prototype networks.
Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions
Apr 27, 2023



Breast cancer has reached the highest incidence rate worldwide among all malignancies since 2020. Breast imaging plays a significant role in early diagnosis and intervention to improve the outcome of breast cancer patients. In the past decade, deep learning has shown remarkable progress in breast cancer imaging analysis, holding great promise in interpreting the rich information and complex context of breast imaging modalities. Considering the rapid improvement in the deep learning technology and the increasing severity of breast cancer, it is critical to summarize past progress and identify future challenges to be addressed. In this paper, we provide an extensive survey of deep learning-based breast cancer imaging research, covering studies on mammogram, ultrasound, magnetic resonance imaging, and digital pathology images over the past decade. The major deep learning methods, publicly available datasets, and applications on imaging-based screening, diagnosis, treatment response prediction, and prognosis are described in detail. Drawn from the findings of this survey, we present a comprehensive discussion of the challenges and potential avenues for future research in deep learning-based breast cancer imaging.
Explicitly Modeled Attention Maps for Image Classification
Jun 14, 2020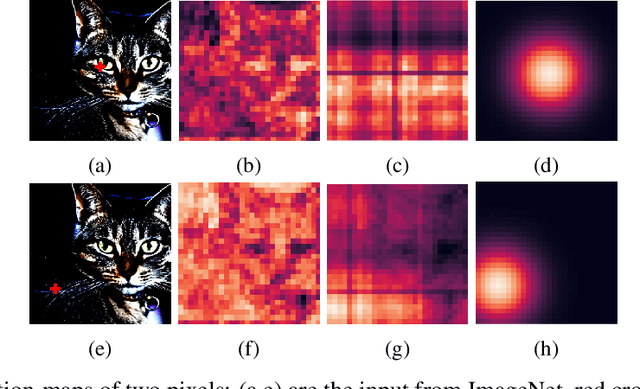

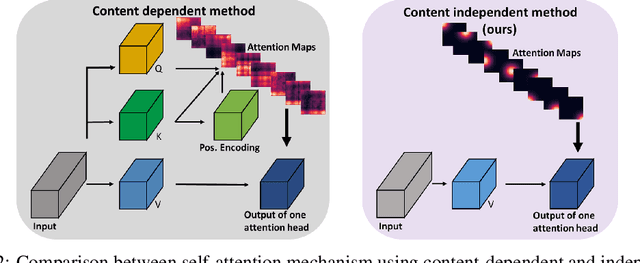
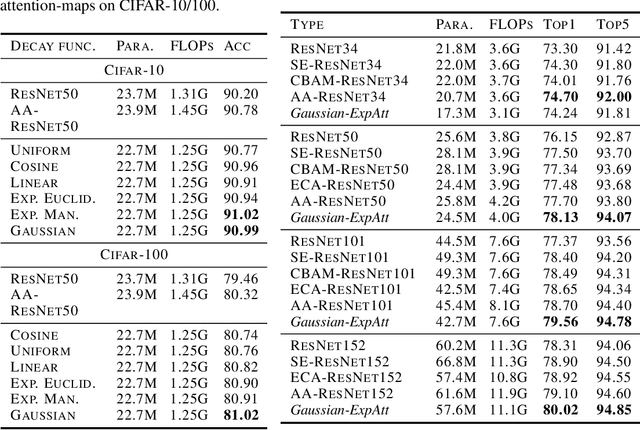
Self-attention networks have shown remarkable progress in computer vision tasks such as image classification. The main benefit of the self-attention mechanism is the ability to capture long-range feature interactions in attention-maps. However, the computation of attention-maps requires a learnable key, query, and positional encoding, whose usage is often not intuitive and computationally expensive. To mitigate this problem, we propose a novel self-attention module with explicitly modeled attention-maps using only a single learnable parameter for low computational overhead. The design of explicitly modeled attention-maps using geometric prior is based on the observation that the spatial context for a given pixel within an image is mostly dominated by its neighbors, while more distant pixels have a minor contribution. Concretely, the attention-maps are parametrized via simple functions (e.g., Gaussian kernel) with a learnable radius, which is modeled independently of the input content. Our evaluation shows that our method achieves an accuracy improvement of up to 2.2% over the ResNet-baselines in ImageNet ILSVRC and outperforms other self-attention methods such as AA-ResNet152 (Bello et al., 2019) in accuracy by 0.9% with 6.4% fewer parameters and 6.7% fewer GFLOPs.