 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect and Locate: A Face Anti-Manipulation Approach with Semantic and Noise-level Supervision
Jul 13, 2021
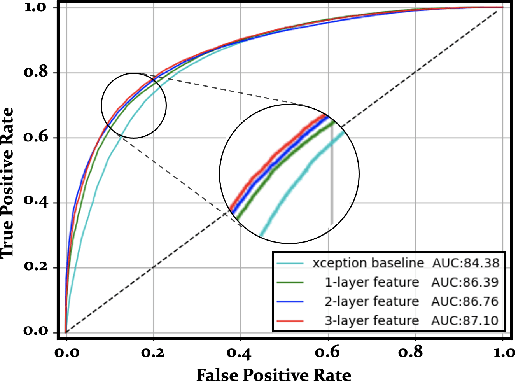
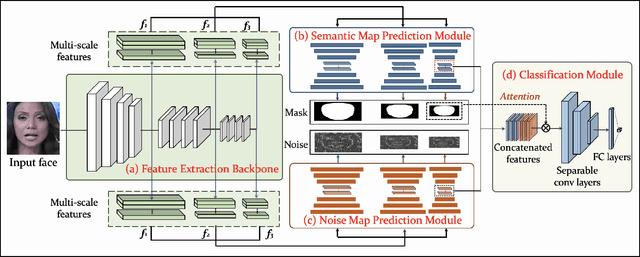
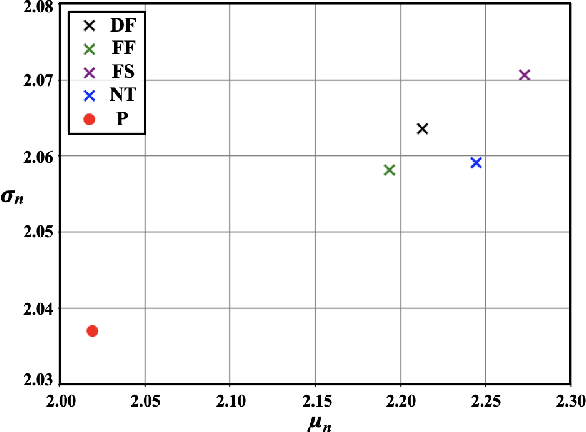
The technological advancements of deep learning have enabled sophisticated face manipulation schemes, raising severe trust issues and security concerns in modern society. Generally speaking, detecting manipulated faces and locating the potentially altered regions are challenging tasks. Herein, we propose a conceptually simple but effective method to efficiently detect forged faces in an image while simultaneously locating the manipulated regions. The proposed scheme relies on a segmentation map that delivers meaningful high-level semantic information clues about the image. Furthermore, a noise map is estimated, playing a complementary role in capturing low-level clues and subsequently empowering decision-making. Finally, the features from these two modules are combined to distinguish fake faces. Extensive experiments show that the proposed model achieves state-of-the-art detection accuracy and remarkable localization performance.
Benchmarking Scientific Image Forgery Detectors
May 26, 2021The scientific image integrity area presents a challenging research bottleneck, the lack of available datasets to design and evaluate forensic techniques. Its data sensitivity creates a legal hurdle that prevents one to rely on real tampered cases to build any sort of accessible forensic benchmark. To mitigate this bottleneck, we present an extendable open-source library that reproduces the most common image forgery operations reported by the research integrity community: duplication, retouching, and cleaning. Using this library and realistic scientific images, we create a large scientific forgery image benchmark (39,423 images) with an enriched ground-truth. In addition, concerned about the high number of retracted papers due to image duplication, this work evaluates the state-of-the-art copy-move detection methods in the proposed dataset, using a new metric that asserts consistent match detection between the source and the copied region. The dataset and source-code will be freely available upon acceptance of the paper.
Unsupervised and self-adaptative techniques for cross-domain person re-identification
Mar 26, 2021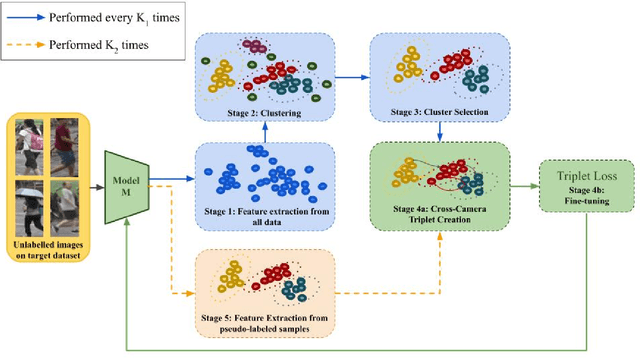
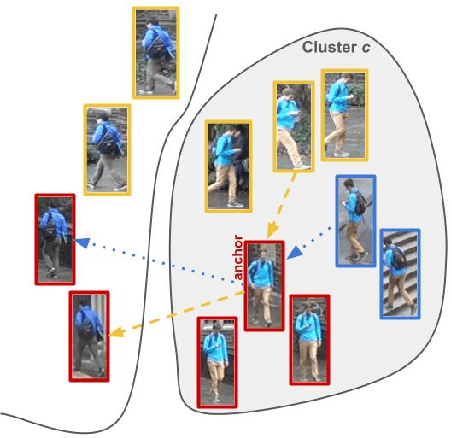
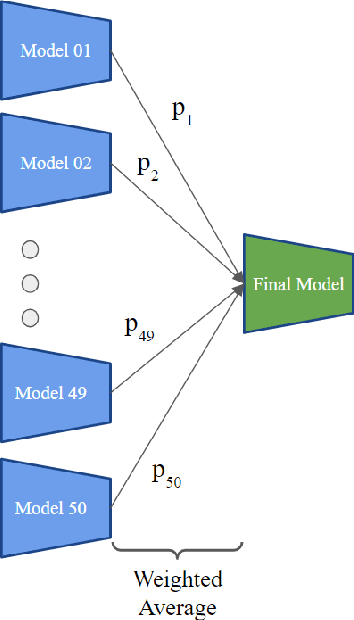
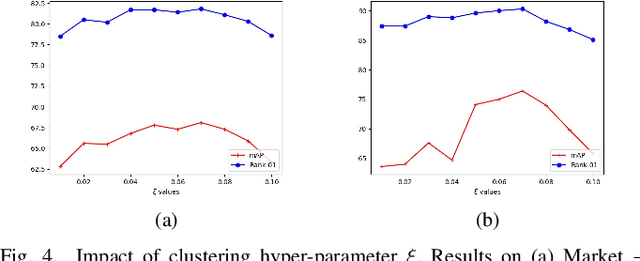
Person Re-Identification (ReID) across non-overlapping cameras is a challenging task and, for this reason, most works in the prior art rely on supervised feature learning from a labeled dataset to match the same person in different views. However, it demands the time-consuming task of labeling the acquired data, prohibiting its fast deployment, specially in forensic scenarios. Unsupervised Domain Adaptation (UDA) emerges as a promising alternative, as it performs feature-learning adaptation from a model trained on a source to a target domain without identity-label annotation. However, most UDA-based algorithms rely upon a complex loss function with several hyper-parameters, which hinders the generalization to different scenarios. Moreover, as UDA depends on the translation between domains, it is important to select the most reliable data from the unseen domain, thus avoiding error propagation caused by noisy examples on the target data -- an often overlooked problem. In this sense, we propose a novel UDA-based ReID method that optimizes a simple loss function with only one hyper-parameter and that takes advantage of triplets of samples created by a new offline strategy based on the diversity of cameras within a cluster. This new strategy adapts the model and also regularizes it, avoiding overfitting on the target domain. We also introduce a new self-ensembling strategy, in which weights from different iterations are aggregated to create a final model combining knowledge from distinct moments of the adaptation. For evaluation, we consider three well-known deep learning architectures and combine them for final decision-making. The proposed method does not use person re-ranking nor any label on the target domain, and outperforms the state of the art, with a much simpler setup, on the Market to Duke, the challenging Market1501 to MSMT17, and Duke to MSMT17 adaptation scenarios.
Content-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
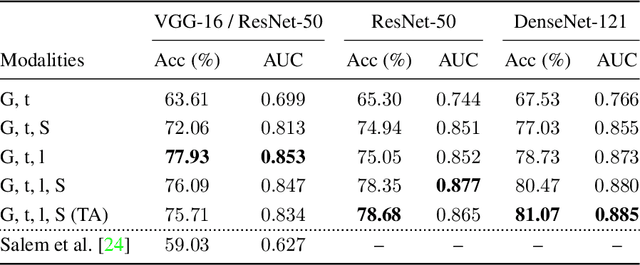


Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.
Survey on Reliable Deep Learning-Based Person Re-Identification Models: Are We There Yet?
Apr 30, 2020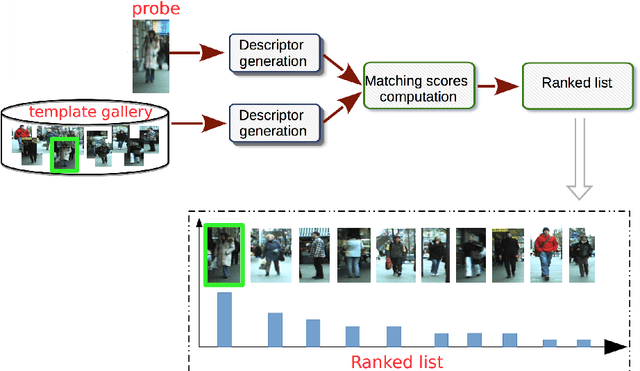
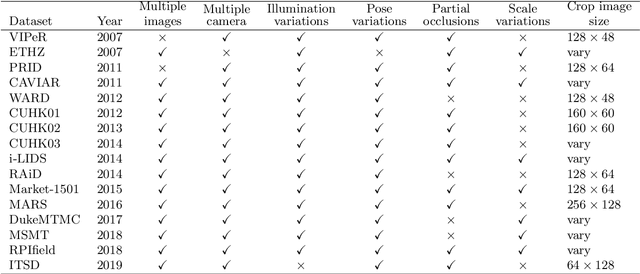
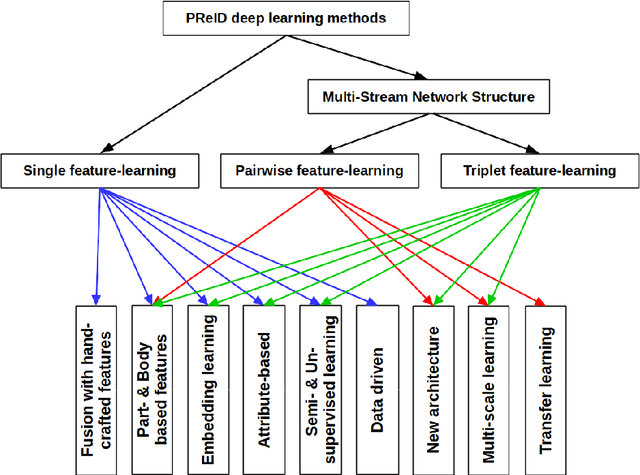
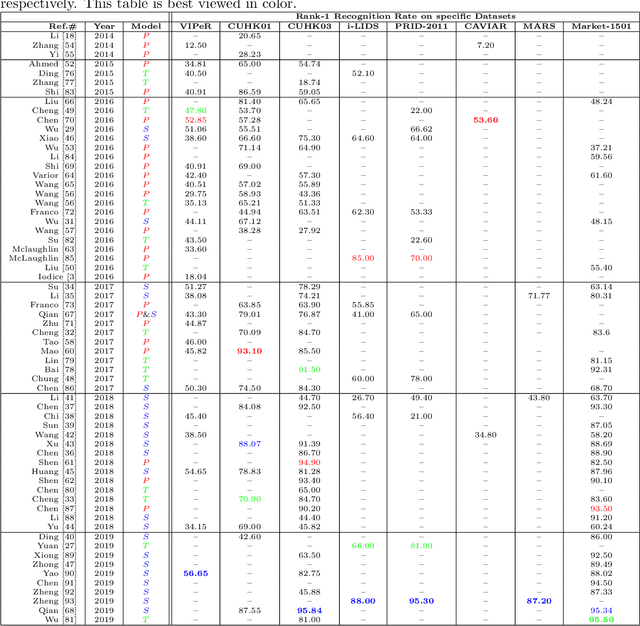
Intelligent video-surveillance (IVS) is currently an active research field in computer vision and machine learning and provides useful tools for surveillance operators and forensic video investigators. Person re-identification (PReID) is one of the most critical problems in IVS, and it consists of recognizing whether or not an individual has already been observed over a camera in a network. Solutions to PReID have myriad applications including retrieval of video-sequences showing an individual of interest or even pedestrian tracking over multiple camera views. Different techniques have been proposed to increase the performance of PReID in the literature, and more recently researchers utilized deep neural networks (DNNs) given their compelling performance on similar vision problems and fast execution at test time. Given the importance and wide range of applications of re-identification solutions, our objective herein is to discuss the work carried out in the area and come up with a survey of state-of-the-art DNN models being used for this task. We present descriptions of each model along with their evaluation on a set of benchmark datasets. Finally, we show a detailed comparison among these models, which are followed by some discussions on their limitations that can work as guidelines for future research.
Learning Transformation-Aware Embeddings for Image Forensics
Jan 13, 2020
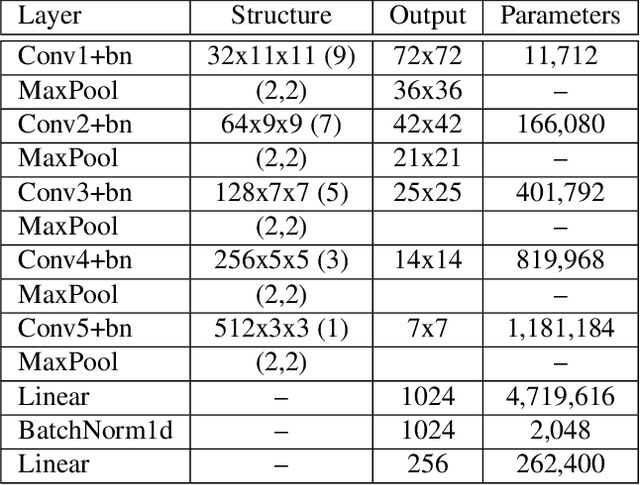

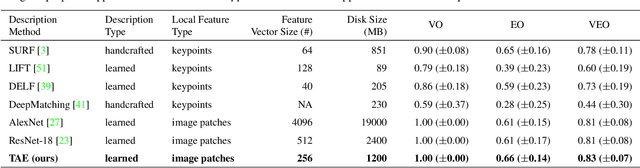
A dramatic rise in the flow of manipulated image content on the Internet has led to an aggressive response from the media forensics research community. New efforts have incorporated increased usage of techniques from computer vision and machine learning to detect and profile the space of image manipulations. This paper addresses Image Provenance Analysis, which aims at discovering relationships among different manipulated image versions that share content. One of the main sub-problems for provenance analysis that has not yet been addressed directly is the edit ordering of images that share full content or are near-duplicates. The existing large networks that generate image descriptors for tasks such as object recognition may not encode the subtle differences between these image covariates. This paper introduces a novel deep learning-based approach to provide a plausible ordering to images that have been generated from a single image through transformations. Our approach learns transformation-aware descriptors using weak supervision via composited transformations and a rank-based quadruplet loss. To establish the efficacy of the proposed approach, comparisons with state-of-the-art handcrafted and deep learning-based descriptors, and image matching approaches are made. Further experimentation validates the proposed approach in the context of image provenance analysis.
An In-Depth Study on Open-Set Camera Model Identification
Apr 11, 2019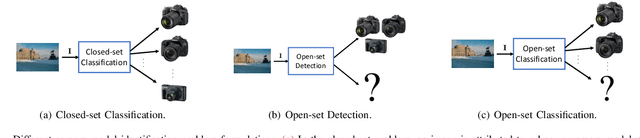
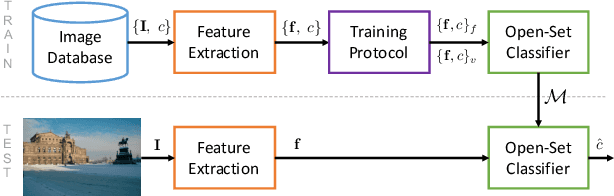
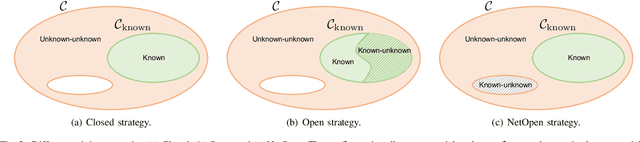
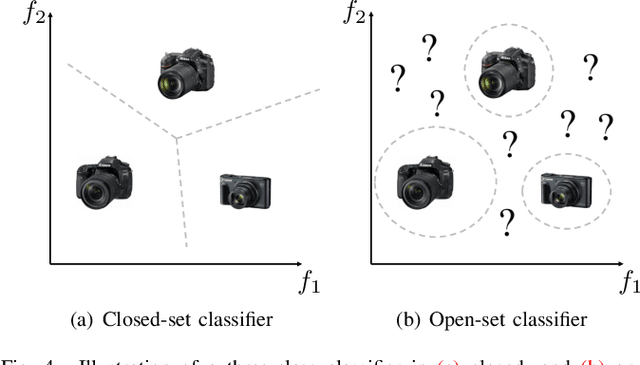
Camera model identification refers to the problem of linking a picture to the camera model used to shoot it. As this might be an enabling factor in different forensic applications to single out possible suspects (e.g., detecting the author of child abuse or terrorist propaganda material), many accurate camera model attribution methods have been developed in the literature. One of their main drawbacks, however, is the typical closed-set assumption of the problem. This means that an investigated photograph is always assigned to one camera model within a set of known ones present during investigation, i.e., training time, and the fact that the picture can come from a completely unrelated camera model during actual testing is usually ignored. Under realistic conditions, it is not possible to assume that every picture under analysis belongs to one of the available camera models. To deal with this issue, in this paper, we present the first in-depth study on the possibility of solving the camera model identification problem in open-set scenarios. Given a photograph, we aim at detecting whether it comes from one of the known camera models of interest or from an unknown device. We compare different feature extraction algorithms and classifiers specially targeting open-set recognition. We also evaluate possible open-set training protocols that can be applied along with any open-set classifier. More specifically, we evaluate one training protocol targeted for open-set classifiers with deep features. We observe that a simpler version of those training protocols works with similar results to the one that requires extra data, which can be useful in many applications in which deep features are employed. Thorough testing on independent datasets shows that it is possible to leverage a recently proposed convolutional neural network as feature extractor paired with a properly trained open-set classifier...
Needle in a Haystack: A Framework for Seeking Small Objects in Big Datasets
Apr 10, 2019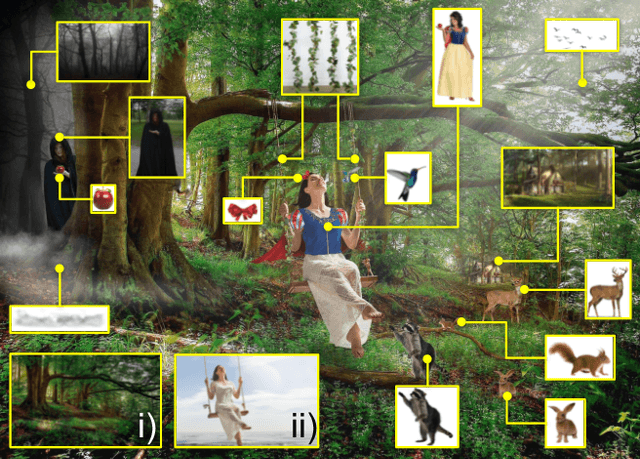
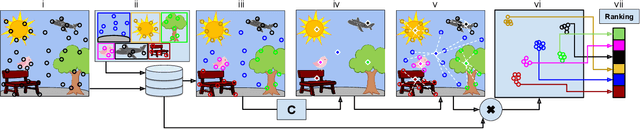
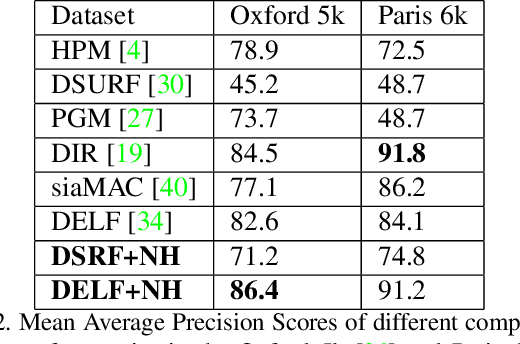
Images from social media can reflect diverse viewpoints, heated arguments, and expressions of creativity --- adding new complexity to search tasks. Researchers working on Content-Based Image Retrieval (CBIR) have traditionally tuned their search algorithms to match filtered results with user search intent. However, we are now bombarded with composite images of unknown origin, authenticity, and even meaning. With such uncertainty, users may not have an initial idea of what the results of a search query should look like. For instance, hidden people, spliced objects, and subtly altered scenes can be difficult for a user to detect initially in a meme image, but may contribute significantly to its composition. We propose a new framework for image retrieval that models object-level regions using image keypoints retrieved from an image index, which are then used to accurately weight small contributing objects within the results, without the need for costly object detection steps. We call this method Needle-Haystack (NH) scoring, and it is optimized for fast matrix operations on CPUs. We show that this method not only performs comparably to state-of-the-art methods in classic CBIR problems, but also outperforms them in fine-grained object- and instance-level retrieval on the Oxford 5K, Paris 6K, Google-Landmarks, and NIST MFC2018 datasets, as well as meme-style imagery from Reddit.
FaceSpoof Buster: a Presentation Attack Detector Based on Intrinsic Image Properties and Deep Learning
Feb 07, 2019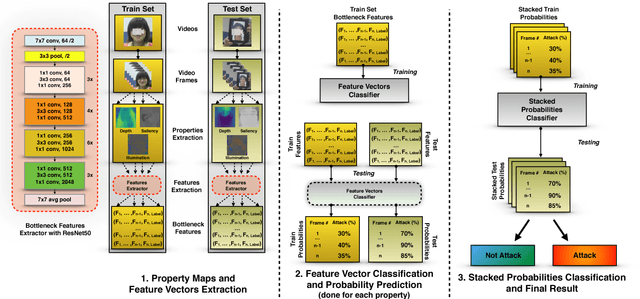
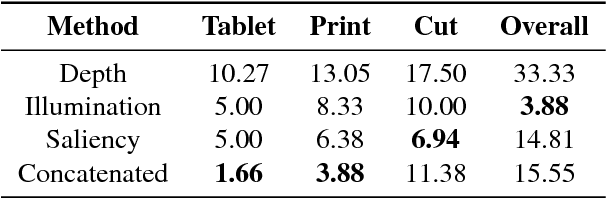
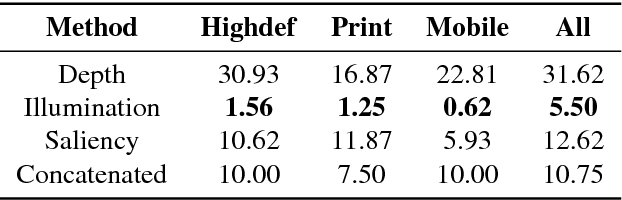
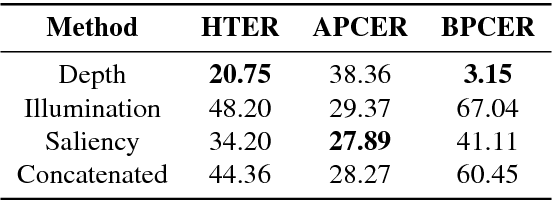
Nowadays, the adoption of face recognition for biometric authentication systems is usual, mainly because this is one of the most accessible biometric modalities. Techniques that rely on trespassing these kind of systems by using a forged biometric sample, such as a printed paper or a recorded video of a genuine access, are known as presentation attacks, but may be also referred in the literature as face spoofing. Presentation attack detection is a crucial step for preventing this kind of unauthorized accesses into restricted areas and/or devices. In this paper, we propose a novel approach which relies in a combination between intrinsic image properties and deep neural networks to detect presentation attack attempts. Our method explores depth, salience and illumination maps, associated with a pre-trained Convolutional Neural Network in order to produce robust and discriminant features. Each one of these properties are individually classified and, in the end of the process, they are combined by a meta learning classifier, which achieves outstanding results on the most popular datasets for PAD. Results show that proposed method is able to overpass state-of-the-art results in an inter-dataset protocol, which is defined as the most challenging in the literature.
Ensemble of Multi-View Learning Classifiers for Cross-Domain Iris Presentation Attack Detection
Nov 25, 2018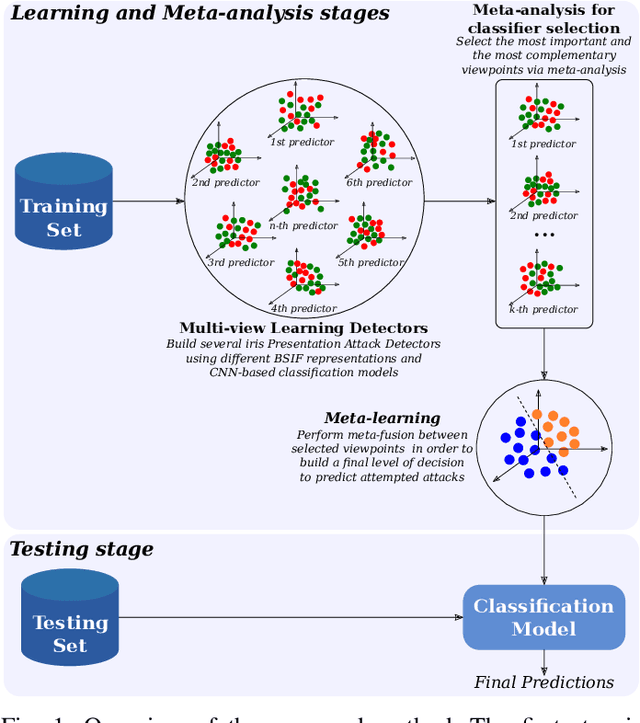
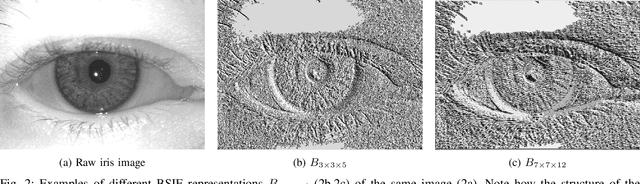
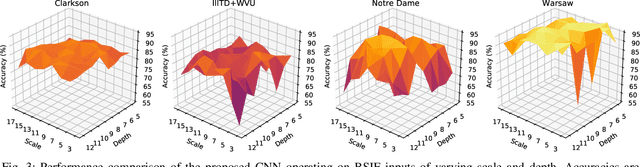
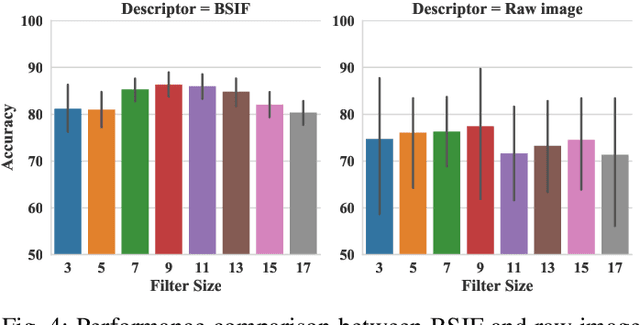
The adoption of large-scale iris recognition systems around the world has brought to light the importance of detecting presentation attack images (textured contact lenses and printouts). This work presents a new approach in iris Presentation Attack Detection (PAD), by exploring combinations of Convolutional Neural Networks (CNNs) and transformed input spaces through binarized statistical image features (BSIF). Our method combines lightweight CNNs to classify multiple BSIF views of the input image. Following explorations on complementary input spaces leading to more discriminative features to detect presentation attacks, we also propose an algorithm to select the best (and most discriminative) predictors for the task at hand.An ensemble of predictors makes use of their expected individual performances to aggregate their results into a final prediction. Results show that this technique improves on the current state of the art in iris PAD, outperforming the winner of LivDet-Iris2017 competition both for intra- and cross-dataset scenarios, and illustrating the very difficult nature of the cross-dataset scenario.