 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring different approaches to customize language models for domain-specific text-to-code generation
Mar 17, 2026Large language models (LLMs) have demonstrated strong capabilities in generating executable code from natural language descriptions. However, general-purpose models often struggle in specialized programming contexts where domain-specific libraries, APIs, or conventions must be used. Customizing smaller open-source models offers a cost-effective alternative to relying on large proprietary systems. In this work, we investigate how smaller language models can be adapted for domain-specific code generation using synthetic datasets. We construct datasets of programming exercises across three domains within the Python ecosystem: general Python programming, Scikit-learn machine learning workflows, and OpenCV-based computer vision tasks. Using these datasets, we evaluate three customization strategies: few-shot prompting, retrieval-augmented generation (RAG), and parameter-efficient fine-tuning using Low-Rank Adaptation (LoRA). Performance is evaluated using both benchmark-based metrics and similarity-based metrics that measure alignment with domain-specific code. Our results show that prompting-based approaches such as few-shot learning and RAG can improve domain relevance in a cost-effective manner, although their impact on benchmark accuracy is limited. In contrast, LoRA-based fine-tuning consistently achieves higher accuracy and stronger domain alignment across most tasks. These findings highlight practical trade-offs between flexibility, computational cost, and performance when adapting smaller language models for specialized programming tasks.
Content-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
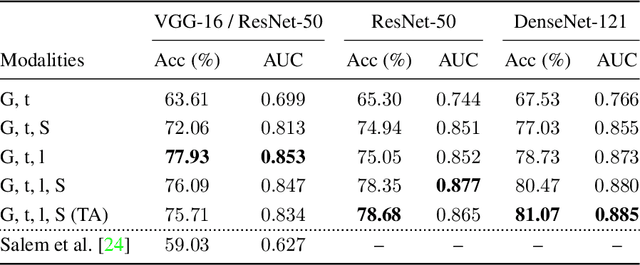


Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.