 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage, Caste, and Context: Demographic Disparities in AI-Generated Explanations Across Indian and American STEM Educational Systems
Jan 20, 2026The popularization of AI chatbot usage globally has created opportunities for research into their benefits and drawbacks, especially for students using AI assistants for coursework support. This paper asks: how do LLMs perceive the intellectual capabilities of student profiles from intersecting marginalized identities across different cultural contexts? We conduct one of the first large-scale intersectional analyses on LLM explanation quality for Indian and American undergraduate profiles preparing for engineering entrance examinations. By constructing profiles combining multiple demographic dimensions including caste, medium of instruction, and school boards in India, and race, HBCU attendance, and school type in America, alongside universal factors like income and college tier, we examine how quality varies across these factors. We observe biases providing lower-quality outputs to profiles with marginalized backgrounds in both contexts. LLMs such as Qwen2.5-32B-Instruct and GPT-4o demonstrate granular understandings of context-specific discrimination, systematically providing simpler explanations to Hindi/Regional-medium students in India and HBCU profiles in America, treating these as proxies for lower capability. Even when marginalized profiles attain social mobility by getting accepted into elite institutions, they still receive more simplistic explanations, showing how demographic information is inextricably linked to LLM biases. Different models (Qwen2.5-32B-Instruct, GPT-4o, GPT-4o-mini, GPT-OSS 20B) embed similar biases against historically marginalized populations in both contexts, preventing profiles from switching between AI assistants for better results. Our findings have strong implications for AI incorporation into global engineering education.
Generative Interventions for Causal Learning
Dec 22, 2020
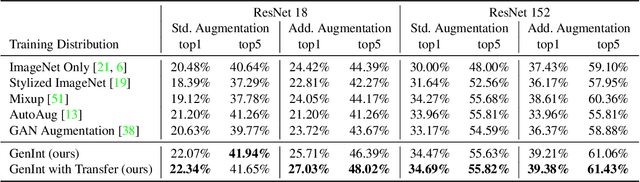

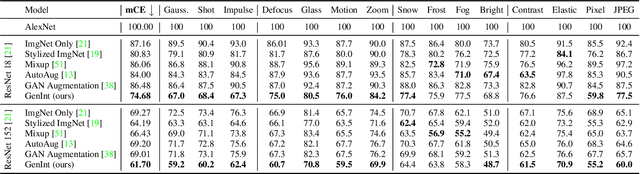
We introduce a framework for learning robust visual representations that generalize to new viewpoints, backgrounds, and scene contexts. Discriminative models often learn naturally occurring spurious correlations, which cause them to fail on images outside of the training distribution. In this paper, we show that we can steer generative models to manufacture interventions on features caused by confounding factors. Experiments, visualizations, and theoretical results show this method learns robust representations more consistent with the underlying causal relationships. Our approach improves performance on multiple datasets demanding out-of-distribution generalization, and we demonstrate state-of-the-art performance generalizing from ImageNet to ObjectNet dataset.
Multitask Learning Strengthens Adversarial Robustness
Jul 14, 2020


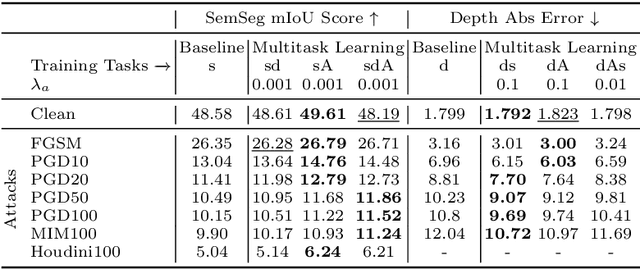
Although deep networks achieve strong accuracy on a range of computer vision benchmarks, they remain vulnerable to adversarial attacks, where imperceptible input perturbations fool the network. We present both theoretical and empirical analyses that connect the adversarial robustness of a model to the number of tasks that it is trained on. Experiments on two datasets show that attack difficulty increases as the number of target tasks increase. Moreover, our results suggest that when models are trained on multiple tasks at once, they become more robust to adversarial attacks on individual tasks. While adversarial defense remains an open challenge, our results suggest that deep networks are vulnerable partly because they are trained on too few tasks.