 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Structured Representations into Pretrained Vision & Language Models Using Scene Graphs
May 10, 2023



Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, recent studies have shown that even the best VL models struggle to capture aspects of scene understanding, such as object attributes, relationships, and action states. In contrast, obtaining structured annotations, e.g., scene graphs (SGs) that could improve these models is time-consuming, costly, and tedious, and thus cannot be used on a large scale. Here we ask, can small datasets containing SG annotations provide sufficient information for enhancing structured understanding of VL models? We show that it is indeed possible to improve VL models using such data by utilizing a specialized model architecture and a new training paradigm. Our approach captures structure-related information for both the visual and textual encoders by directly supervising both components when learning from SG labels. We use scene graph supervision to generate fine-grained captions based on various graph augmentations highlighting different compositional aspects of the scene, and to predict SG information using an open vocabulary approach by adding special ``Adaptive SG tokens'' to the visual encoder. Moreover, we design a new adaptation technique tailored specifically to the SG tokens that allows better learning of the graph prediction task while still maintaining zero-shot capabilities. Our model shows strong performance improvements on the Winoground and VL-checklist datasets with only a mild degradation in zero-shot performance.
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Apr 28, 2023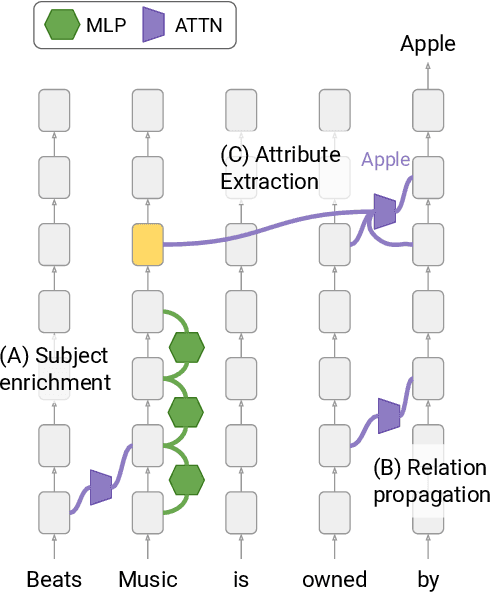

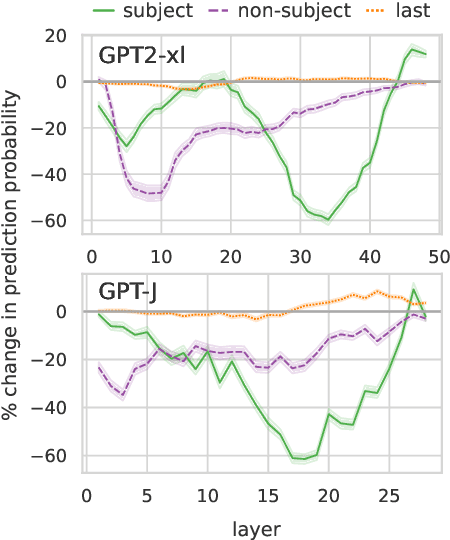
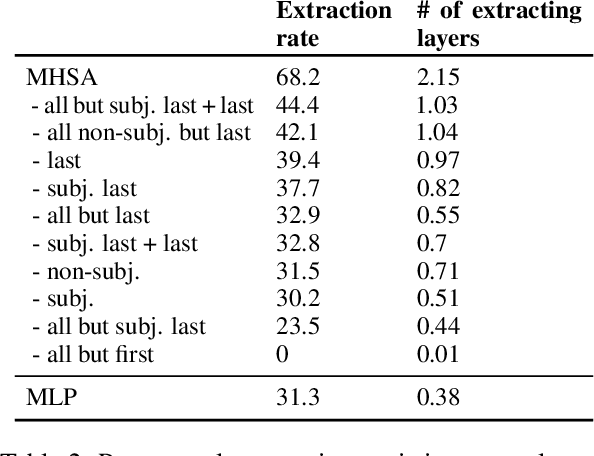
Transformer-based language models (LMs) are known to capture factual knowledge in their parameters. While previous work looked into where factual associations are stored, only little is known about how they are retrieved internally during inference. We investigate this question through the lens of information flow. Given a subject-relation query, we study how the model aggregates information about the subject and relation to predict the correct attribute. With interventions on attention edges, we first identify two critical points where information propagates to the prediction: one from the relation positions followed by another from the subject positions. Next, by analyzing the information at these points, we unveil a three-step internal mechanism for attribute extraction. First, the representation at the last-subject position goes through an enrichment process, driven by the early MLP sublayers, to encode many subject-related attributes. Second, information from the relation propagates to the prediction. Third, the prediction representation "queries" the enriched subject to extract the attribute. Perhaps surprisingly, this extraction is typically done via attention heads, which often encode subject-attribute mappings in their parameters. Overall, our findings introduce a comprehensive view of how factual associations are stored and extracted internally in LMs, facilitating future research on knowledge localization and editing.
Crawling the Internal Knowledge-Base of Language Models
Jan 30, 2023



Language models are trained on large volumes of text, and as a result their parameters might contain a significant body of factual knowledge. Any downstream task performed by these models implicitly builds on these facts, and thus it is highly desirable to have means for representing this body of knowledge in an interpretable way. However, there is currently no mechanism for such a representation. Here, we propose to address this goal by extracting a knowledge-graph of facts from a given language model. We describe a procedure for ``crawling'' the internal knowledge-base of a language model. Specifically, given a seed entity, we expand a knowledge-graph around it. The crawling procedure is decomposed into sub-tasks, realized through specially designed prompts that control for both precision (i.e., that no wrong facts are generated) and recall (i.e., the number of facts generated). We evaluate our approach on graphs crawled starting from dozens of seed entities, and show it yields high precision graphs (82-92%), while emitting a reasonable number of facts per entity.
What Are You Token About? Dense Retrieval as Distributions Over the Vocabulary
Dec 20, 2022



Dual encoders are now the dominant architecture for dense retrieval. Yet, we have little understanding of how they represent text, and why this leads to good performance. In this work, we shed light on this question via distributions over the vocabulary. We propose to interpret the vector representations produced by dual encoders by projecting them into the model's vocabulary space. We show that the resulting distributions over vocabulary tokens are intuitive and contain rich semantic information. We find that this view can explain some of the failure cases of dense retrievers. For example, the inability of models to handle tail entities can be explained via a tendency of the token distributions to forget some of the tokens of those entities. We leverage this insight and propose a simple way to enrich query and passage representations with lexical information at inference time, and show that this significantly improves performance compared to the original model in out-of-domain settings.
PromptonomyViT: Multi-Task Prompt Learning Improves Video Transformers using Synthetic Scene Data
Dec 08, 2022



Action recognition models have achieved impressive results by incorporating scene-level annotations, such as objects, their relations, 3D structure, and more. However, obtaining annotations of scene structure for videos requires a significant amount of effort to gather and annotate, making these methods expensive to train. In contrast, synthetic datasets generated by graphics engines provide powerful alternatives for generating scene-level annotations across multiple tasks. In this work, we propose an approach to leverage synthetic scene data for improving video understanding. We present a multi-task prompt learning approach for video transformers, where a shared video transformer backbone is enhanced by a small set of specialized parameters for each task. Specifically, we add a set of ``task prompts'', each corresponding to a different task, and let each prompt predict task-related annotations. This design allows the model to capture information shared among synthetic scene tasks as well as information shared between synthetic scene tasks and a real video downstream task throughout the entire network. We refer to this approach as ``Promptonomy'', since the prompts model a task-related structure. We propose the PromptonomyViT model (PViT), a video transformer that incorporates various types of scene-level information from synthetic data using the ``Promptonomy'' approach. PViT shows strong performance improvements on multiple video understanding tasks and datasets.
Text-Only Training for Image Captioning using Noise-Injected CLIP
Nov 01, 2022We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
Learning Low Dimensional State Spaces with Overparameterized Recurrent Neural Network
Oct 25, 2022Overparameterization in deep learning typically refers to settings where a trained Neural Network (NN) has representational capacity to fit the training data in many ways, some of which generalize well, while others do not. In the case of Recurrent Neural Networks (RNNs), there exists an additional layer of overparameterization, in the sense that a model may exhibit many solutions that generalize well for sequence lengths seen in training, some of which extrapolate to longer sequences, while others do not. Numerous works studied the tendency of Gradient Descent (GD) to fit overparameterized NNs with solutions that generalize well. On the other hand, its tendency to fit overparameterized RNNs with solutions that extrapolate has been discovered only lately, and is far less understood. In this paper, we analyze the extrapolation properties of GD when applied to overparameterized linear RNNs. In contrast to recent arguments suggesting an implicit bias towards short-term memory, we provide theoretical evidence for learning low dimensional state spaces, which can also model long-term memory. Our result relies on a dynamical characterization which shows that GD (with small step size and near-zero initialization) strives to maintain a certain form of balancedness, as well as on tools developed in the context of the moment problem from statistics (recovery of a probability distribution from its moments). Experiments corroborate our theory, demonstrating extrapolation via learning low dimensional state spaces with both linear and non-linear RNNs
Visual Prompting via Image Inpainting
Sep 01, 2022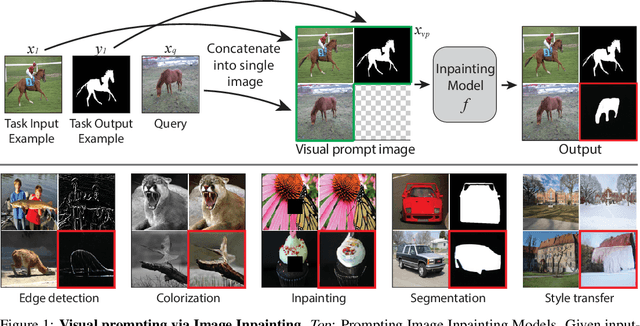
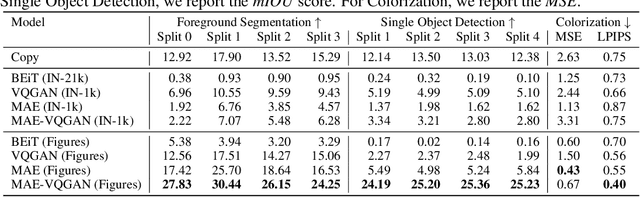
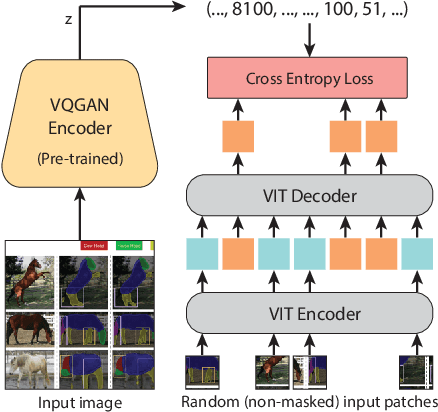
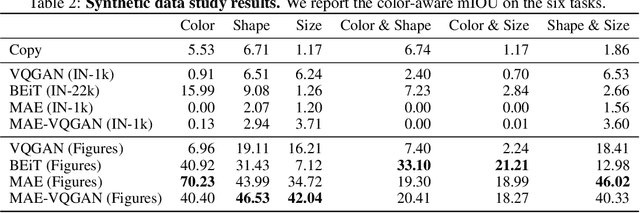
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Graph Trees with Attention
Jul 06, 2022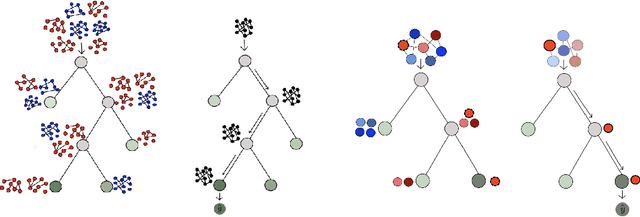

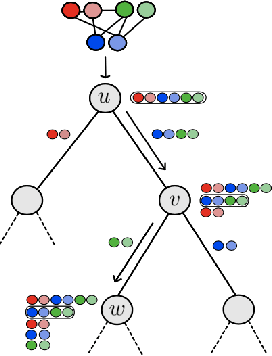
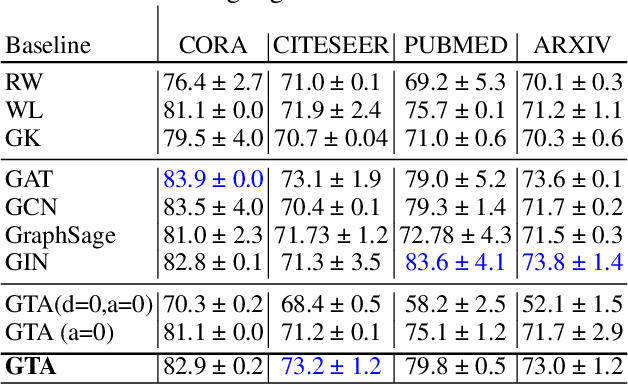
When dealing with tabular data, models based on regression and decision trees are a popular choice due to the high accuracy they provide on such tasks and their ease of application as compared to other model classes. Yet, when it comes to graph-structure data, current tree learning algorithms do not provide tools to manage the structure of the data other than relying on feature engineering. In this work we address the above gap, and introduce Graph Trees with Attention (GTA), a new family of tree-based learning algorithms that are designed to operate on graphs. GTA leverages both the graph structure and the features at the vertices and employs an attention mechanism that allows decisions to concentrate on sub-structures of the graph. We analyze GTA models and show that they are strictly more expressive than plain decision trees. We also demonstrate the benefits of GTA empirically on multiple graph and node prediction benchmarks. In these experiments, GTA always outperformed other tree-based models and often outperformed other types of graph-learning algorithms such as Graph Neural Networks (GNNs) and Graph Kernels. Finally, we also provide an explainability mechanism for GTA, and demonstrate it can provide intuitive explanations.
Structured Video Tokens @ Ego4D PNR Temporal Localization Challenge 2022
Jun 15, 2022


This technical report describes the SViT approach for the Ego4D Point of No Return (PNR) Temporal Localization Challenge. We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a "Frame-Clip Consistency" loss, which ensures the flow of structured information between images and videos. SViT obtains strong performance on the challenge test set with 0.656 absolute temporal localization error.