 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interplay Between Fine-tuning and Composition in Transformers
Jun 01, 2021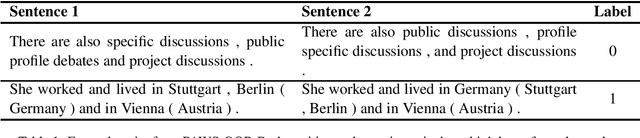
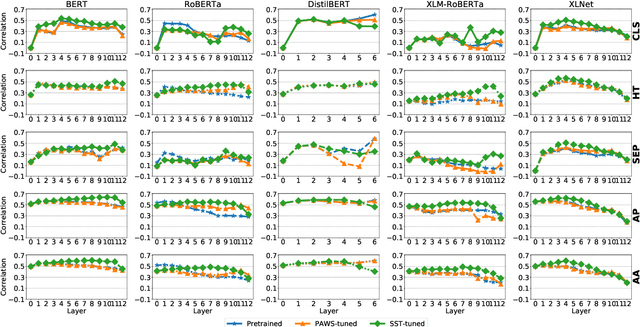
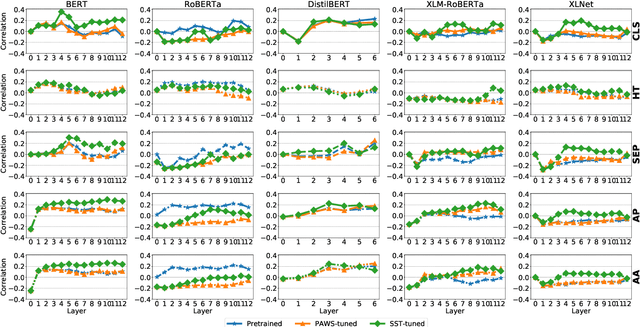
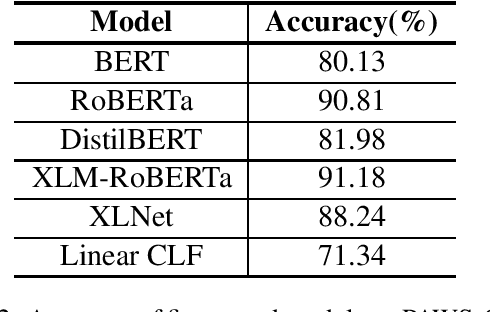
Pre-trained transformer language models have shown remarkable performance on a variety of NLP tasks. However, recent research has suggested that phrase-level representations in these models reflect heavy influences of lexical content, but lack evidence of sophisticated, compositional phrase information. Here we investigate the impact of fine-tuning on the capacity of contextualized embeddings to capture phrase meaning information beyond lexical content. Specifically, we fine-tune models on an adversarial paraphrase classification task with high lexical overlap, and on a sentiment classification task. After fine-tuning, we analyze phrasal representations in controlled settings following prior work. We find that fine-tuning largely fails to benefit compositionality in these representations, though training on sentiment yields a small, localized benefit for certain models. In follow-up analyses, we identify confounding cues in the paraphrase dataset that may explain the lack of composition benefits from that task, and we discuss potential factors underlying the localized benefits from sentiment training.
Do language models learn typicality judgments from text?
May 06, 2021
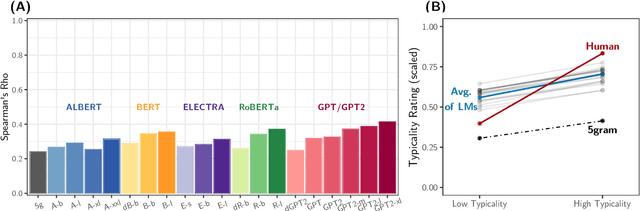

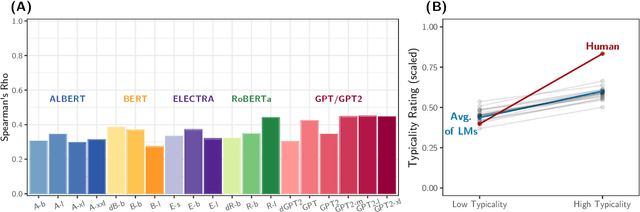
Building on research arguing for the possibility of conceptual and categorical knowledge acquisition through statistics contained in language, we evaluate predictive language models (LMs) -- informed solely by textual input -- on a prevalent phenomenon in cognitive science: typicality. Inspired by experiments that involve language processing and show robust typicality effects in humans, we propose two tests for LMs. Our first test targets whether typicality modulates LM probabilities in assigning taxonomic category memberships to items. The second test investigates sensitivities to typicality in LMs' probabilities when extending new information about items to their categories. Both tests show modest -- but not completely absent -- correspondence between LMs and humans, suggesting that text-based exposure alone is insufficient to acquire typicality knowledge.
Assessing Phrasal Representation and Composition in Transformers
Oct 14, 2020
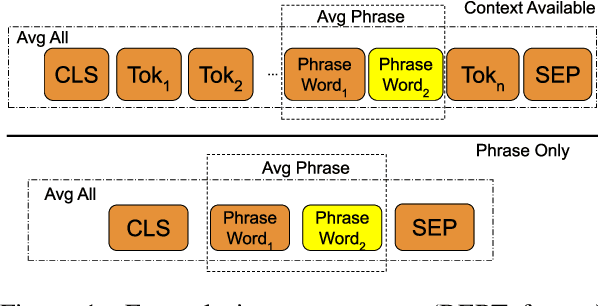

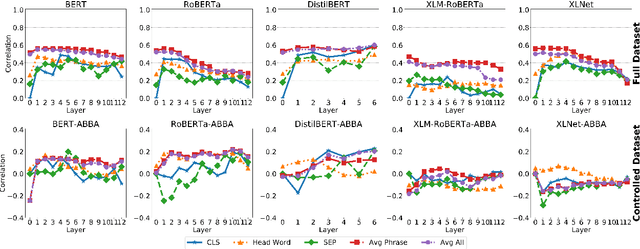
Deep transformer models have pushed performance on NLP tasks to new limits, suggesting sophisticated treatment of complex linguistic inputs, such as phrases. However, we have limited understanding of how these models handle representation of phrases, and whether this reflects sophisticated composition of phrase meaning like that done by humans. In this paper, we present systematic analysis of phrasal representations in state-of-the-art pre-trained transformers. We use tests leveraging human judgments of phrase similarity and meaning shift, and compare results before and after control of word overlap, to tease apart lexical effects versus composition effects. We find that phrase representation in these models relies heavily on word content, with little evidence of nuanced composition. We also identify variations in phrase representation quality across models, layers, and representation types, and make corresponding recommendations for usage of representations from these models.
Exploring BERT's Sensitivity to Lexical Cues using Tests from Semantic Priming
Oct 06, 2020
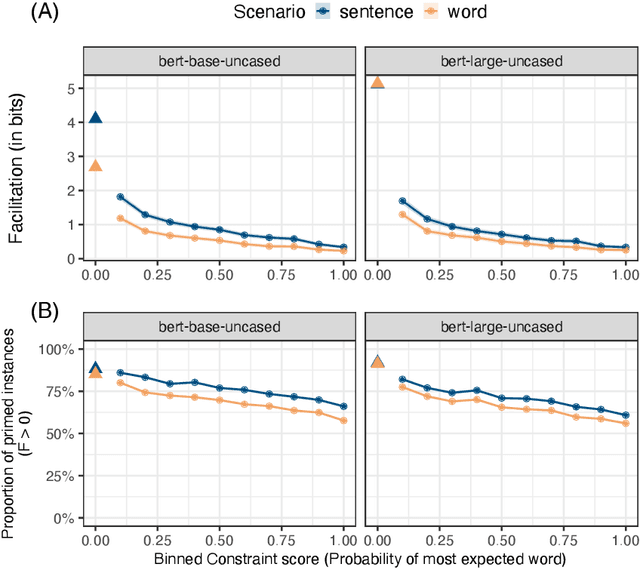
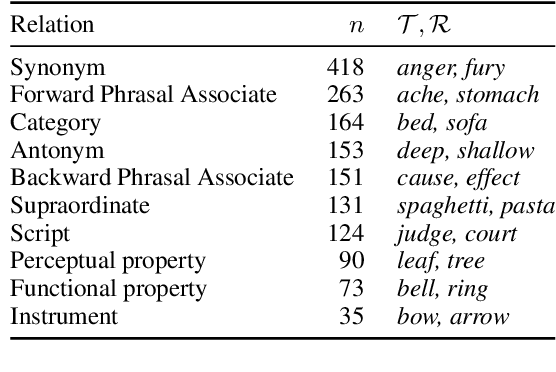
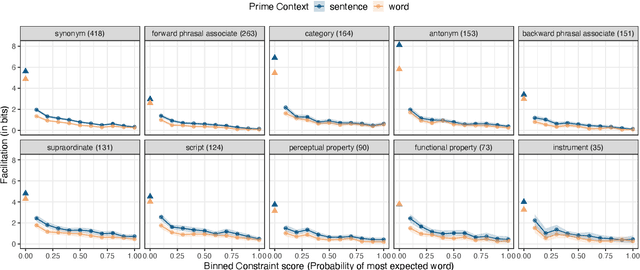
Models trained to estimate word probabilities in context have become ubiquitous in natural language processing. How do these models use lexical cues in context to inform their word probabilities? To answer this question, we present a case study analyzing the pre-trained BERT model with tests informed by semantic priming. Using English lexical stimuli that show priming in humans, we find that BERT too shows "priming," predicting a word with greater probability when the context includes a related word versus an unrelated one. This effect decreases as the amount of information provided by the context increases. Follow-up analysis shows BERT to be increasingly distracted by related prime words as context becomes more informative, assigning lower probabilities to related words. Our findings highlight the importance of considering contextual constraint effects when studying word prediction in these models, and highlight possible parallels with human processing.
Learning to Ignore: Long Document Coreference with Bounded Memory Neural Networks
Oct 06, 2020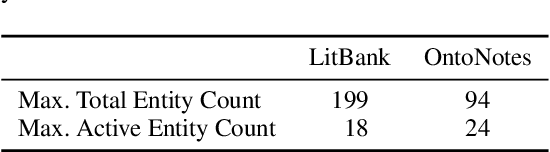
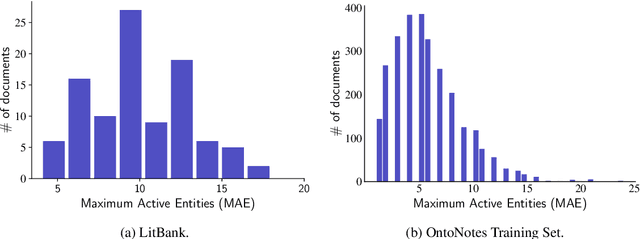
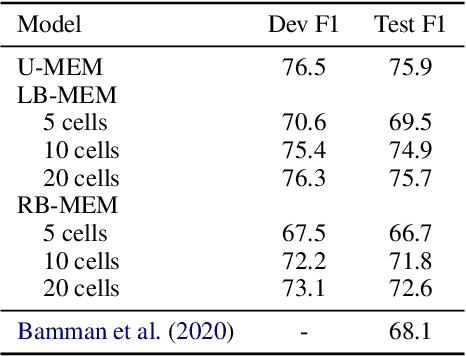
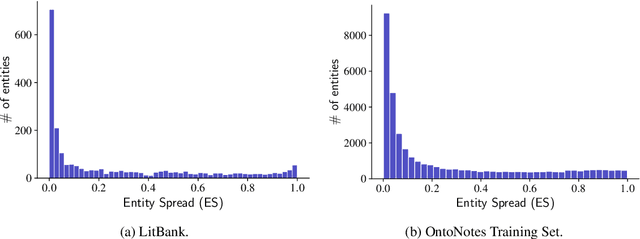
Long document coreference resolution remains a challenging task due to the large memory and runtime requirements of current models. Recent work doing incremental coreference resolution using just the global representation of entities shows practical benefits but requires keeping all entities in memory, which can be impractical for long documents. We argue that keeping all entities in memory is unnecessary, and we propose a memory-augmented neural network that tracks only a small bounded number of entities at a time, thus guaranteeing a linear runtime in length of document. We show that (a) the model remains competitive with models with high memory and computational requirements on OntoNotes and LitBank, and (b) the model learns an efficient memory management strategy easily outperforming a rule-based strategy.
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
Aug 16, 2020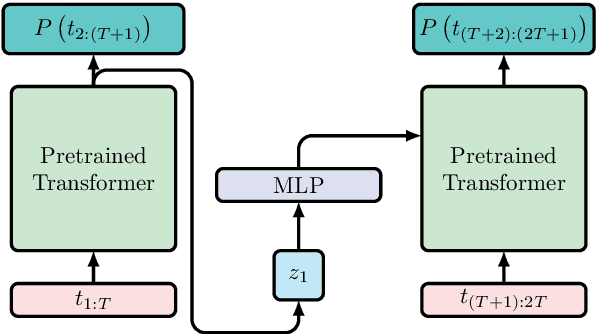
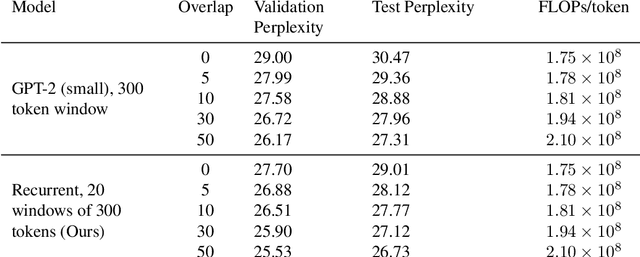
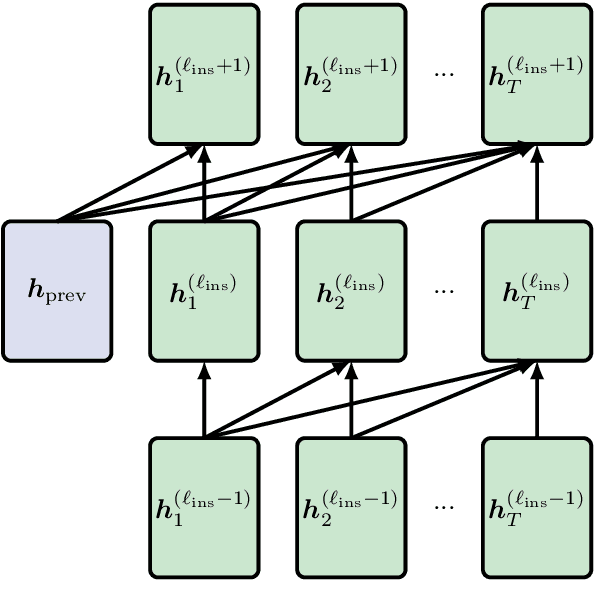
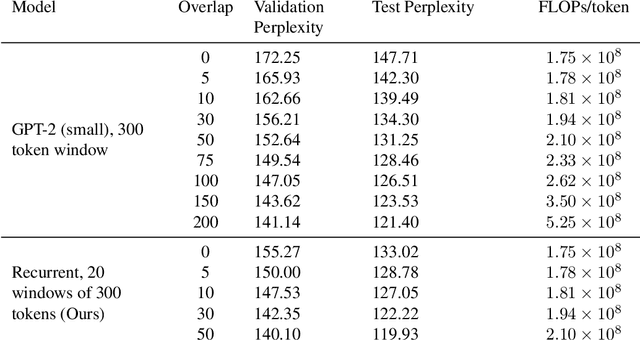
Fine-tuning a pretrained transformer for a downstream task has become a standard method in NLP in the last few years. While the results from these models are impressive, applying them can be extremely computationally expensive, as is pretraining new models with the latest architectures. We present a novel method for applying pretrained transformer language models which lowers their memory requirement both at training and inference time. An additional benefit is that our method removes the fixed context size constraint that most transformer models have, allowing for more flexible use. When applied to the GPT-2 language model, we find that our method attains better perplexity than an unmodified GPT-2 model on the PG-19 and WikiText-103 corpora, for a given amount of computation or memory.
PeTra: A Sparsely Supervised Memory Model for People Tracking
May 06, 2020

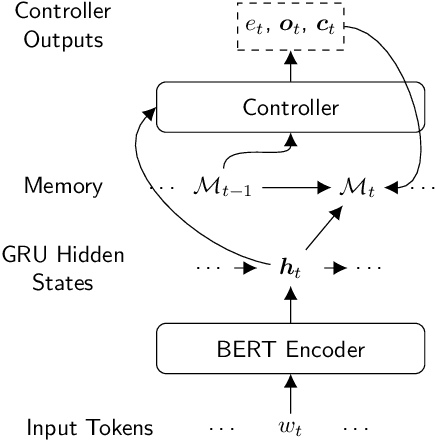
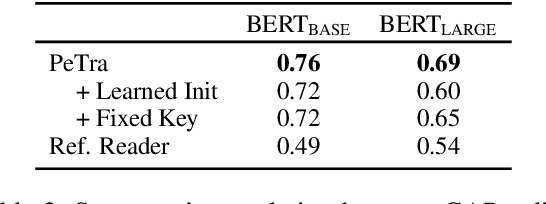
We propose PeTra, a memory-augmented neural network designed to track entities in its memory slots. PeTra is trained using sparse annotation from the GAP pronoun resolution dataset and outperforms a prior memory model on the task while using a simpler architecture. We empirically compare key modeling choices, finding that we can simplify several aspects of the design of the memory module while retaining strong performance. To measure the people tracking capability of memory models, we (a) propose a new diagnostic evaluation based on counting the number of unique entities in text, and (b) conduct a small scale human evaluation to compare evidence of people tracking in the memory logs of PeTra relative to a previous approach. PeTra is highly effective in both evaluations, demonstrating its ability to track people in its memory despite being trained with limited annotation.
Spying on your neighbors: Fine-grained probing of contextual embeddings for information about surrounding words
May 04, 2020
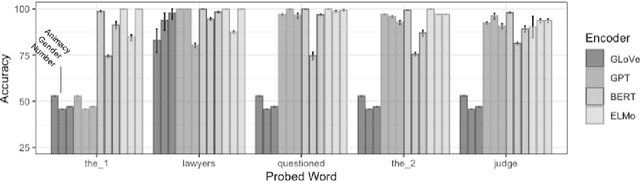

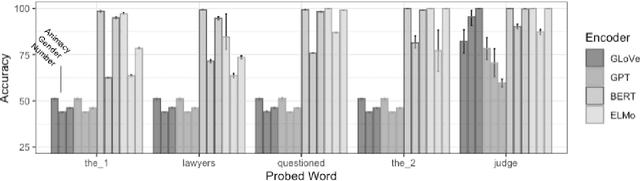
Although models using contextual word embeddings have achieved state-of-the-art results on a host of NLP tasks, little is known about exactly what information these embeddings encode about the context words that they are understood to reflect. To address this question, we introduce a suite of probing tasks that enable fine-grained testing of contextual embeddings for encoding of information about surrounding words. We apply these tasks to examine the popular BERT, ELMo and GPT contextual encoders, and find that each of our tested information types is indeed encoded as contextual information across tokens, often with near-perfect recoverability-but the encoders vary in which features they distribute to which tokens, how nuanced their distributions are, and how robust the encoding of each feature is to distance. We discuss implications of these results for how different types of models breakdown and prioritize word-level context information when constructing token embeddings.
What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models
Jul 31, 2019

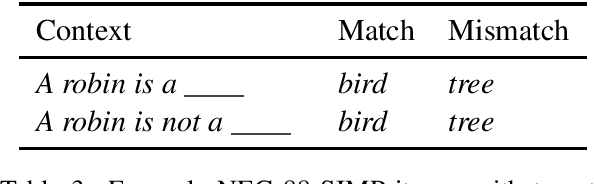
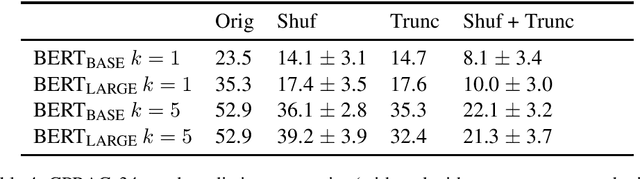
Pre-training by language modeling has become a popular and successful approach to NLP tasks, but we have yet to understand exactly what linguistic capacities these pre-training processes confer upon models. In this paper we introduce a suite of diagnostics drawn from human language experiments, which allow us to ask targeted questions about the information used by language models for generating predictions in context. As a case study, we apply these diagnostics to the popular BERT model, finding that it can generally distinguish good from bad completions involving shared category or role reversal, albeit with less sensitivity than humans, and it robustly retrieves noun hypernyms, but it struggles with challenging inferences and role-based event prediction -- and in particular, it shows clear insensitivity to the contextual impacts of negation.
Assessing Composition in Sentence Vector Representations
Sep 11, 2018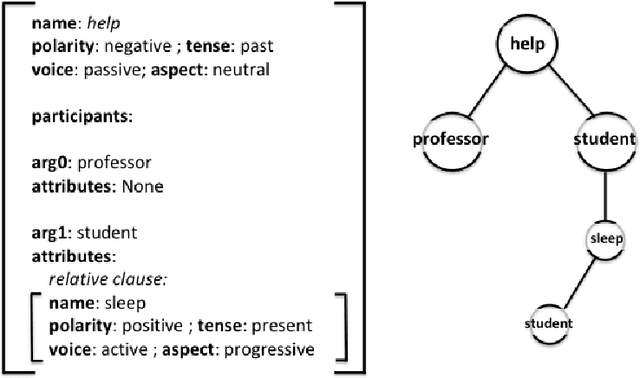

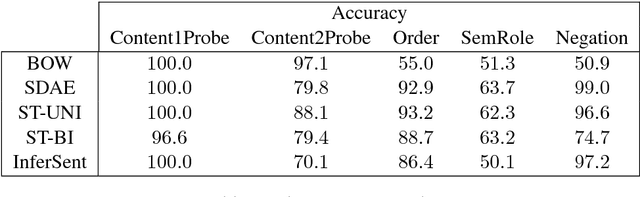
An important component of achieving language understanding is mastering the composition of sentence meaning, but an immediate challenge to solving this problem is the opacity of sentence vector representations produced by current neural sentence composition models. We present a method to address this challenge, developing tasks that directly target compositional meaning information in sentence vector representations with a high degree of precision and control. To enable the creation of these controlled tasks, we introduce a specialized sentence generation system that produces large, annotated sentence sets meeting specified syntactic, semantic and lexical constraints. We describe the details of the method and generation system, and then present results of experiments applying our method to probe for compositional information in embeddings from a number of existing sentence composition models. We find that the method is able to extract useful information about the differing capacities of these models, and we discuss the implications of our results with respect to these systems' capturing of sentence information. We make available for public use the datasets used for these experiments, as well as the generation system.
* COLING 2018