 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripJudge: A Relevance Judgement Test Collection for TripClick Health Retrieval
Aug 14, 2022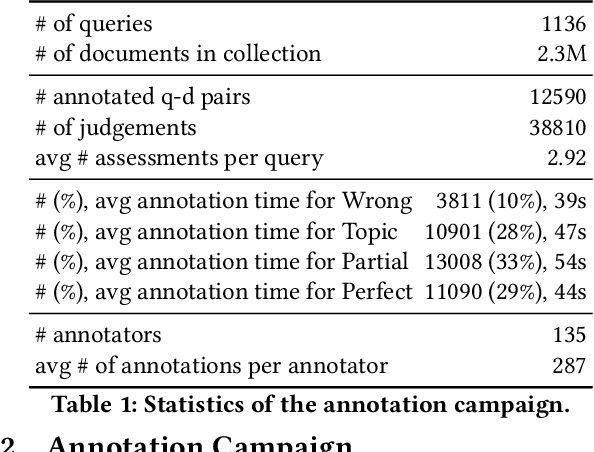
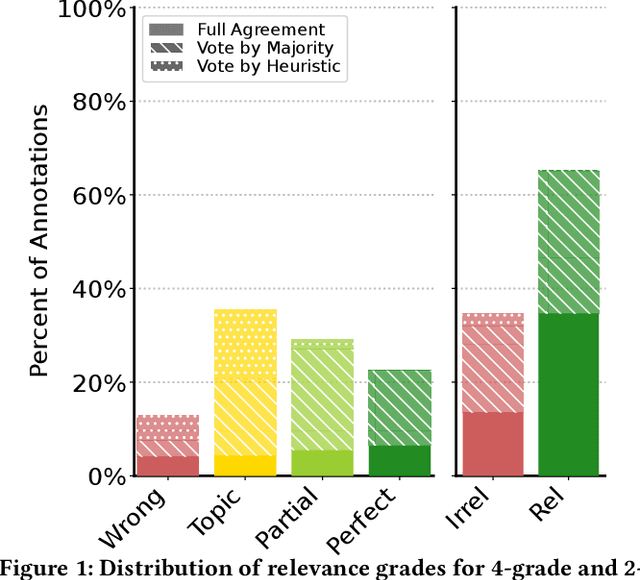
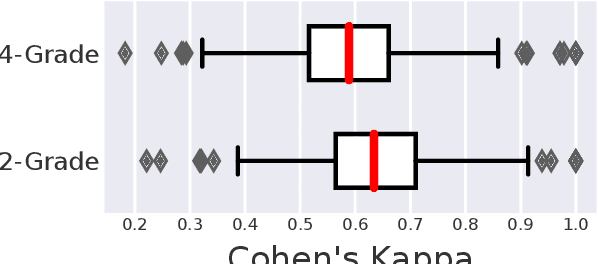
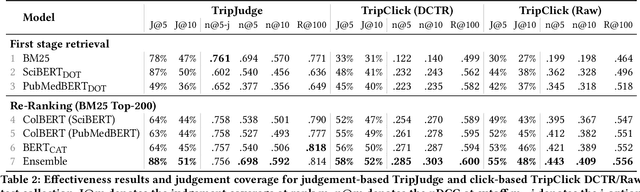
Robust test collections are crucial for Information Retrieval research. Recently there is a growing interest in evaluating retrieval systems for domain-specific retrieval tasks, however these tasks often lack a reliable test collection with human-annotated relevance assessments following the Cranfield paradigm. In the medical domain, the TripClick collection was recently proposed, which contains click log data from the Trip search engine and includes two click-based test sets. However the clicks are biased to the retrieval model used, which remains unknown, and a previous study shows that the test sets have a low judgement coverage for the Top-10 results of lexical and neural retrieval models. In this paper we present the novel, relevance judgement test collection TripJudge for TripClick health retrieval. We collect relevance judgements in an annotation campaign and ensure the quality and reusability of TripJudge by a variety of ranking methods for pool creation, by multiple judgements per query-document pair and by an at least moderate inter-annotator agreement. We compare system evaluation with TripJudge and TripClick and find that that click and judgement-based evaluation can lead to substantially different system rankings.
Are We There Yet? A Decision Framework for Replacing Term Based Retrieval with Dense Retrieval Systems
Jun 26, 2022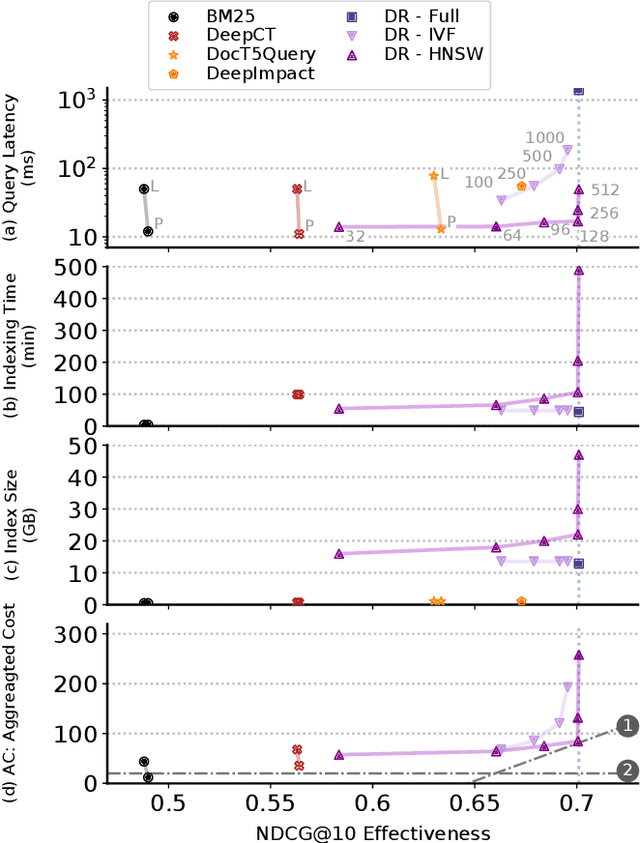
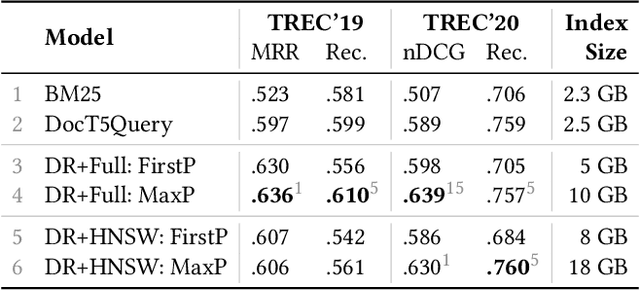
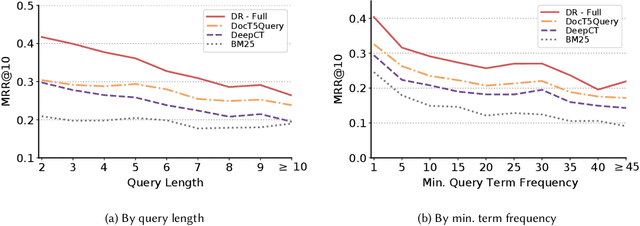
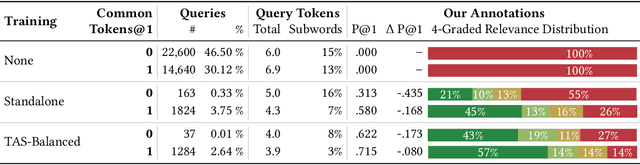
Recently, several dense retrieval (DR) models have demonstrated competitive performance to term-based retrieval that are ubiquitous in search systems. In contrast to term-based matching, DR projects queries and documents into a dense vector space and retrieves results via (approximate) nearest neighbor search. Deploying a new system, such as DR, inevitably involves tradeoffs in aspects of its performance. Established retrieval systems running at scale are usually well understood in terms of effectiveness and costs, such as query latency, indexing throughput, or storage requirements. In this work, we propose a framework with a set of criteria that go beyond simple effectiveness measures to thoroughly compare two retrieval systems with the explicit goal of assessing the readiness of one system to replace the other. This includes careful tradeoff considerations between effectiveness and various cost factors. Furthermore, we describe guardrail criteria, since even a system that is better on average may have systematic failures on a minority of queries. The guardrails check for failures on certain query characteristics and novel failure types that are only possible in dense retrieval systems. We demonstrate our decision framework on a Web ranking scenario. In that scenario, state-of-the-art DR models have surprisingly strong results, not only on average performance but passing an extensive set of guardrail tests, showing robustness on different query characteristics, lexical matching, generalization, and number of regressions. It is impossible to predict whether DR will become ubiquitous in the future, but one way this is possible is through repeated applications of decision processes such as the one presented here.
Introducing Neural Bag of Whole-Words with ColBERTer: Contextualized Late Interactions using Enhanced Reduction
Mar 24, 2022
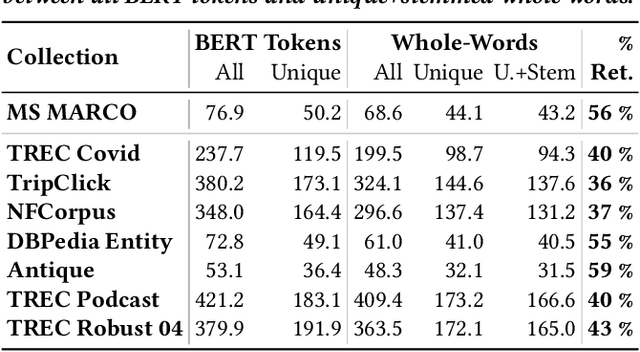
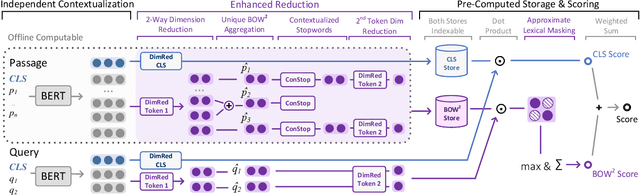
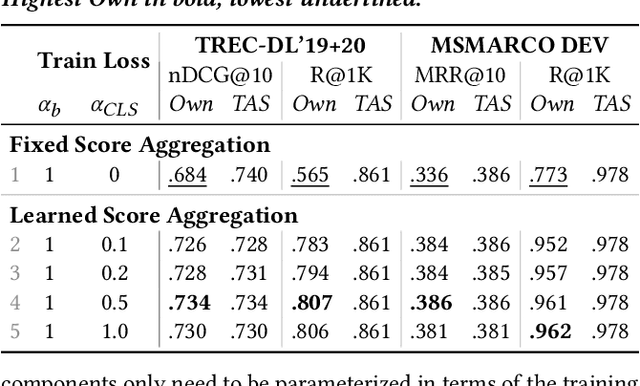
Recent progress in neural information retrieval has demonstrated large gains in effectiveness, while often sacrificing the efficiency and interpretability of the neural model compared to classical approaches. This paper proposes ColBERTer, a neural retrieval model using contextualized late interaction (ColBERT) with enhanced reduction. Along the effectiveness Pareto frontier, ColBERTer's reductions dramatically lower ColBERT's storage requirements while simultaneously improving the interpretability of its token-matching scores. To this end, ColBERTer fuses single-vector retrieval, multi-vector refinement, and optional lexical matching components into one model. For its multi-vector component, ColBERTer reduces the number of stored vectors per document by learning unique whole-word representations for the terms in each document and learning to identify and remove word representations that are not essential to effective scoring. We employ an explicit multi-task, multi-stage training to facilitate using very small vector dimensions. Results on the MS MARCO and TREC-DL collection show that ColBERTer can reduce the storage footprint by up to 2.5x, while maintaining effectiveness. With just one dimension per token in its smallest setting, ColBERTer achieves index storage parity with the plaintext size, with very strong effectiveness results. Finally, we demonstrate ColBERTer's robustness on seven high-quality out-of-domain collections, yielding statistically significant gains over traditional retrieval baselines.
Identifying the root cause of cable network problems with machine learning
Mar 15, 2022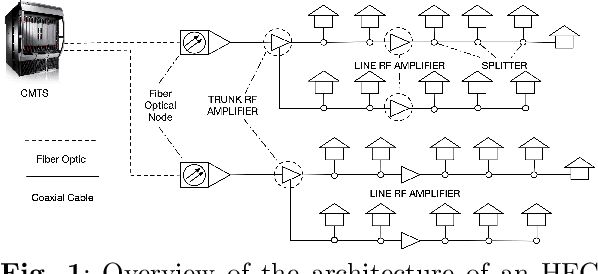
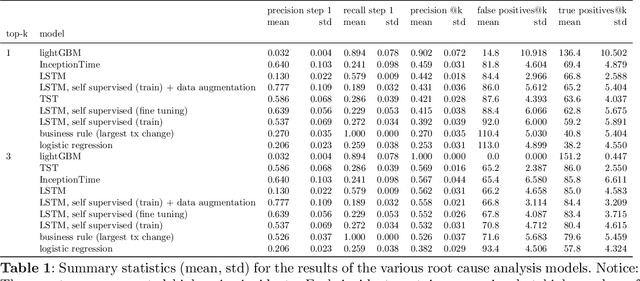
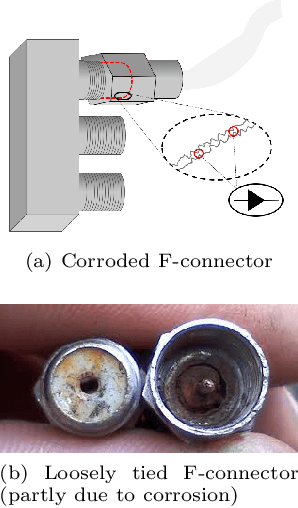
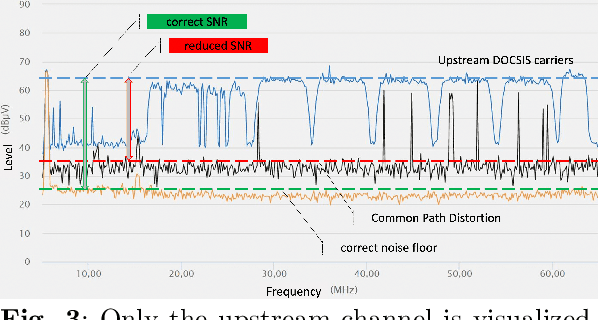
Good quality network connectivity is ever more important. For hybrid fiber coaxial (HFC) networks, searching for upstream high noise in the past was cumbersome and time-consuming. Even with machine learning due to the heterogeneity of the network and its topological structure, the task remains challenging. We present the automation of a simple business rule (largest change of a specific value) and compare its performance with state-of-the-art machine-learning methods and conclude that the precision@1 can be improved by 2.3 times. As it is best when a fault does not occur in the first place, we secondly evaluate multiple approaches to forecast network faults, which would allow performing predictive maintenance on the network.
Automation of Citation Screening for Systematic Literature Reviews using Neural Networks: A Replicability Study
Jan 19, 2022
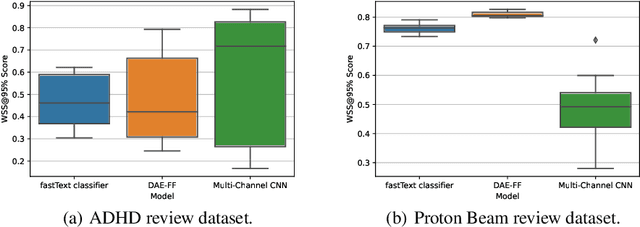
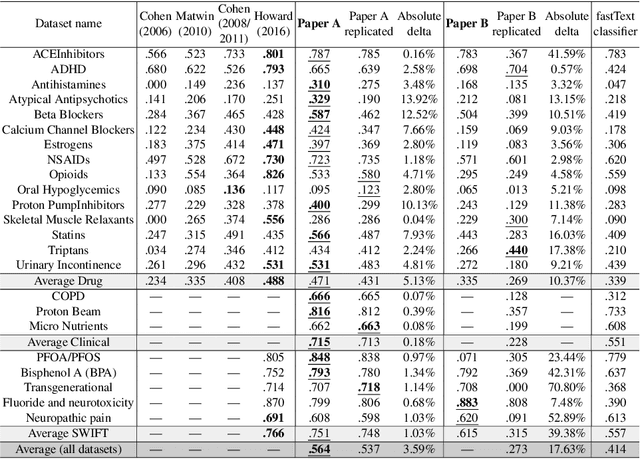
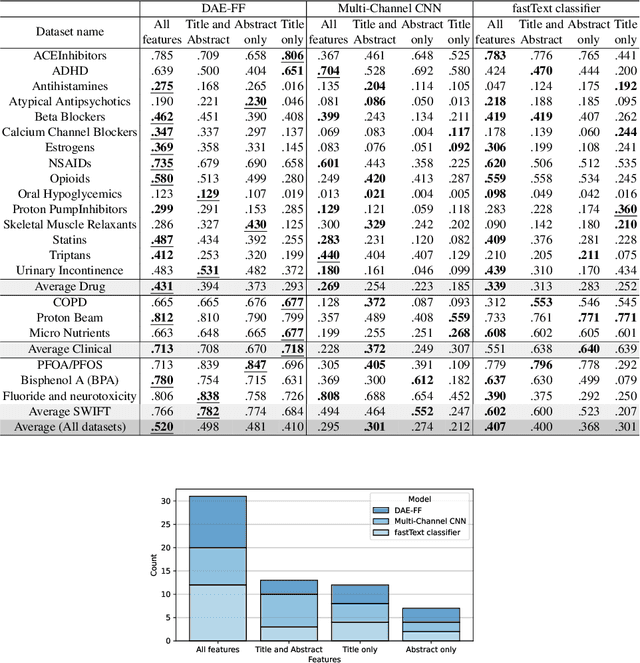
In the process of Systematic Literature Review, citation screening is estimated to be one of the most time-consuming steps. Multiple approaches to automate it using various machine learning techniques have been proposed. The first research papers that apply deep neural networks to this problem were published in the last two years. In this work, we conduct a replicability study of the first two deep learning papers for citation screening and evaluate their performance on 23 publicly available datasets. While we succeeded in replicating the results of one of the papers, we were unable to replicate the results of the other. We summarise the challenges involved in the replication, including difficulties in obtaining the datasets to match the experimental setup of the original papers and problems with executing the original source code. Motivated by this experience, we subsequently present a simpler model based on averaging word embeddings that outperforms one of the models on 18 out of 23 datasets and is, on average, 72 times faster than the second replicated approach. Finally, we measure the training time and the invariance of the models when exposed to a variety of input features and random initialisations, demonstrating differences in the robustness of these approaches.
PARM: A Paragraph Aggregation Retrieval Model for Dense Document-to-Document Retrieval
Jan 05, 2022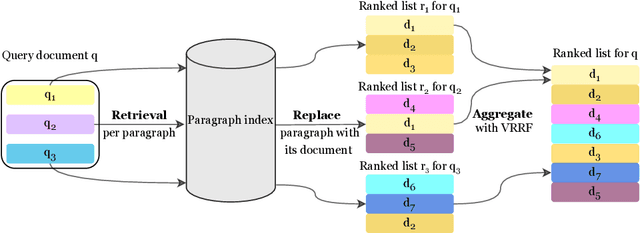
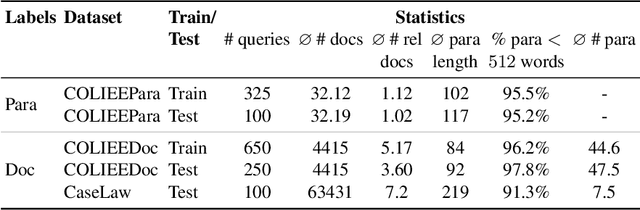
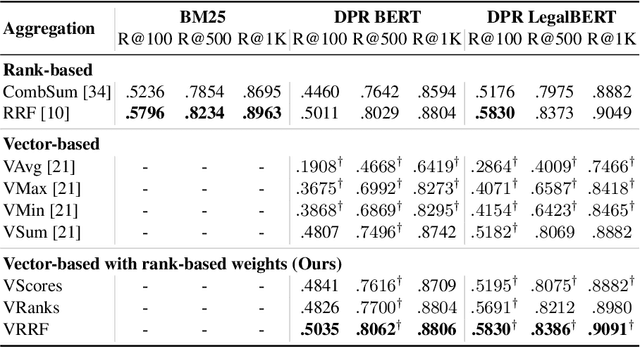
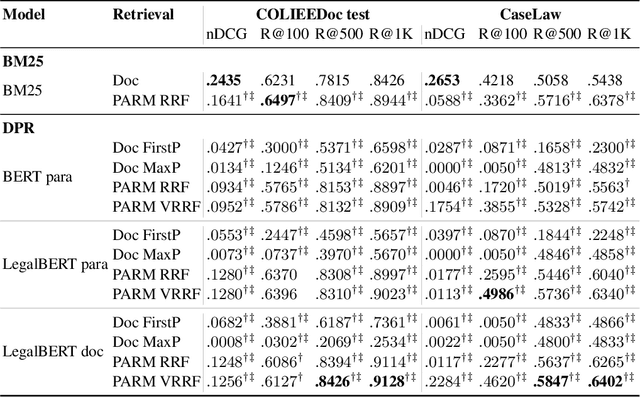
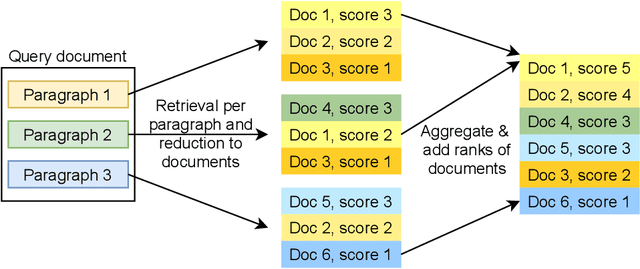
Dense passage retrieval (DPR) models show great effectiveness gains in first stage retrieval for the web domain. However in the web domain we are in a setting with large amounts of training data and a query-to-passage or a query-to-document retrieval task. We investigate in this paper dense document-to-document retrieval with limited labelled target data for training, in particular legal case retrieval. In order to use DPR models for document-to-document retrieval, we propose a Paragraph Aggregation Retrieval Model (PARM) which liberates DPR models from their limited input length. PARM retrieves documents on the paragraph-level: for each query paragraph, relevant documents are retrieved based on their paragraphs. Then the relevant results per query paragraph are aggregated into one ranked list for the whole query document. For the aggregation we propose vector-based aggregation with reciprocal rank fusion (VRRF) weighting, which combines the advantages of rank-based aggregation and topical aggregation based on the dense embeddings. Experimental results show that VRRF outperforms rank-based aggregation strategies for dense document-to-document retrieval with PARM. We compare PARM to document-level retrieval and demonstrate higher retrieval effectiveness of PARM for lexical and dense first-stage retrieval on two different legal case retrieval collections. We investigate how to train the dense retrieval model for PARM on limited target data with labels on the paragraph or the document-level. In addition, we analyze the differences of the retrieved results of lexical and dense retrieval with PARM.
Establishing Strong Baselines for TripClick Health Retrieval
Jan 02, 2022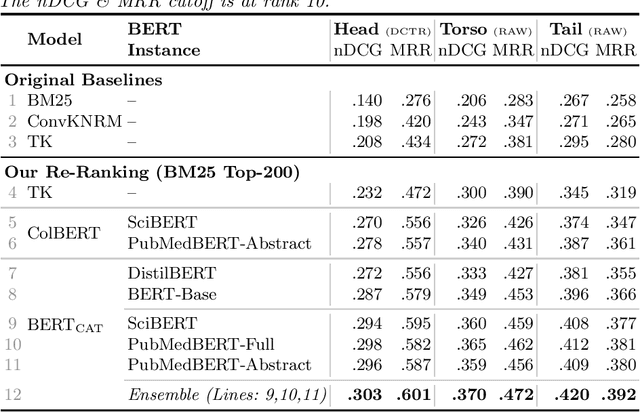
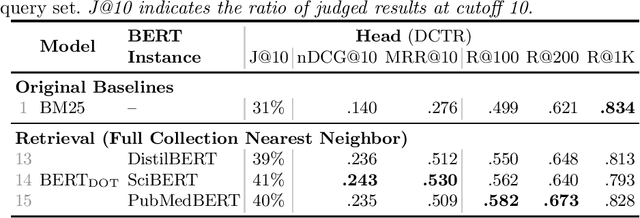
We present strong Transformer-based re-ranking and dense retrieval baselines for the recently released TripClick health ad-hoc retrieval collection. We improve the - originally too noisy - training data with a simple negative sampling policy. We achieve large gains over BM25 in the re-ranking task of TripClick, which were not achieved with the original baselines. Furthermore, we study the impact of different domain-specific pre-trained models on TripClick. Finally, we show that dense retrieval outperforms BM25 by considerable margins, even with simple training procedures.
A Time-Optimized Content Creation Workflow for Remote Teaching
Oct 13, 2021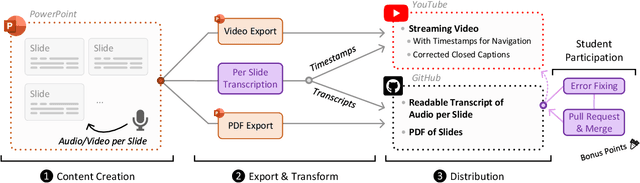
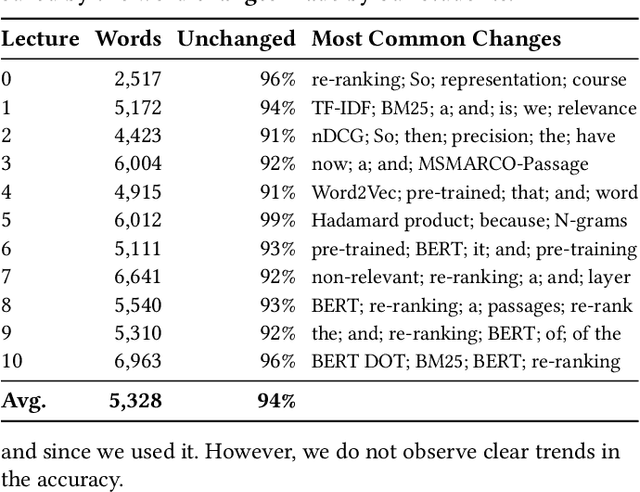
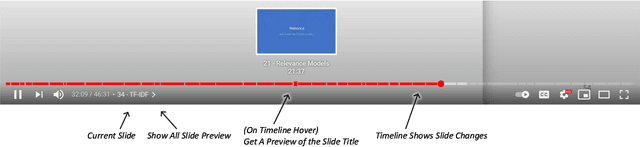

We describe our workflow to create an engaging remote learning experience for a university course, while minimizing the post-production time of the educators. We make use of ubiquitous and commonly free services and platforms, so that our workflow is inclusive for all educators and provides polished experiences for students. Our learning materials provide for each lecture: 1) a recorded video, uploaded on YouTube, with exact slide timestamp indices, which enables an enhanced navigation UI; and 2) a high-quality flow-text automated transcript of the narration with proper punctuation and capitalization, improved with a student participation workflow on GitHub. All these results could be created by hand in a time consuming and costly way. However, this would generally exceed the time available for creating course materials. Our main contribution is to automate the transformation and post-production between raw narrated slides and our published materials with a custom toolchain. Furthermore, we describe our complete workflow: from content creation to transformation and distribution. Our students gave us overwhelmingly positive feedback and especially liked our use of ubiquitous platforms. The most used feature was YouTube's chapter UI enabled through our automatically generated timestamps. The majority of students, who started using the transcripts, continued to do so. Every single transcript was corrected by students, with an average word-change of 6%. We conclude with the positive feedback that our enhanced content formats are much appreciated and utilized. Important for educators is how our low overhead production workflow was sustainable throughout a busy semester.
DoSSIER@COLIEE 2021: Leveraging dense retrieval and summarization-based re-ranking for case law retrieval
Aug 09, 2021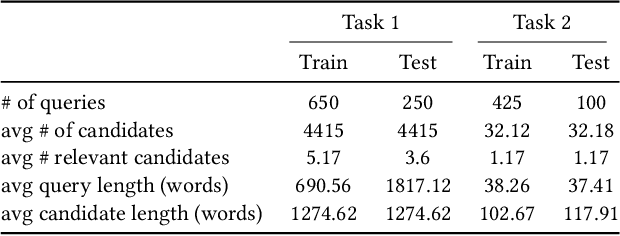
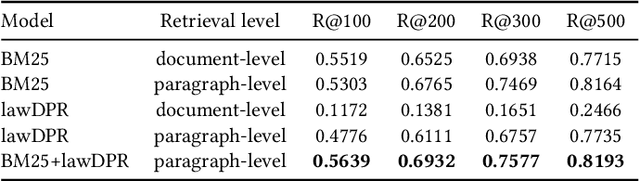
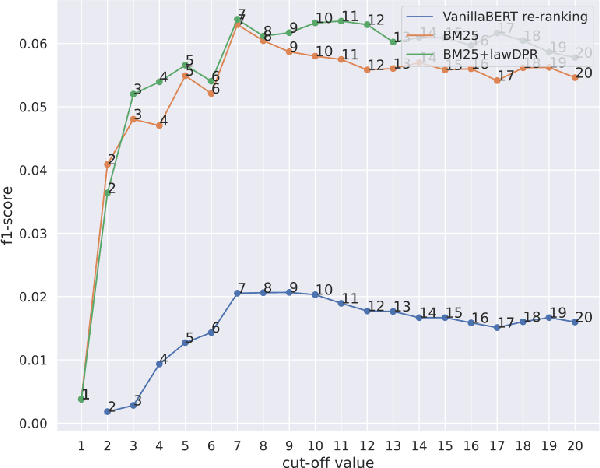
In this paper, we present our approaches for the case law retrieval and the legal case entailment task in the Competition on Legal Information Extraction/Entailment (COLIEE) 2021. As first stage retrieval methods combined with neural re-ranking methods using contextualized language models like BERT achieved great performance improvements for information retrieval in the web and news domain, we evaluate these methods for the legal domain. A distinct characteristic of legal case retrieval is that the query case and case description in the corpus tend to be long documents and therefore exceed the input length of BERT. We address this challenge by combining lexical and dense retrieval methods on the paragraph-level of the cases for the first stage retrieval. Here we demonstrate that the retrieval on the paragraph-level outperforms the retrieval on the document-level. Furthermore the experiments suggest that dense retrieval methods outperform lexical retrieval. For re-ranking we address the problem of long documents by summarizing the cases and fine-tuning a BERT-based re-ranker with the summaries. Overall, our best results were obtained with a combination of BM25 and dense passage retrieval using domain-specific embeddings.
Linguistically Informed Masking for Representation Learning in the Patent Domain
Jun 10, 2021
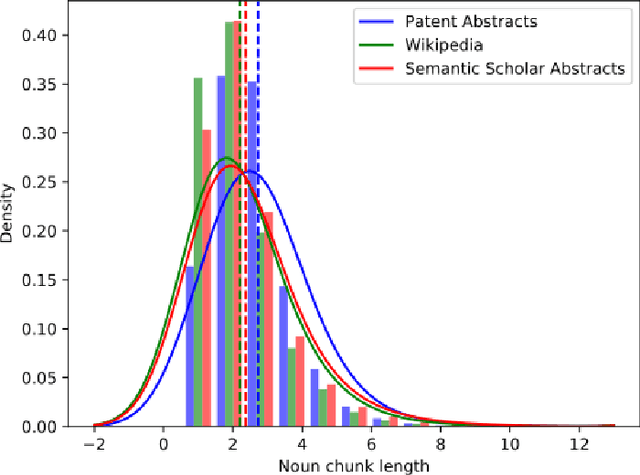
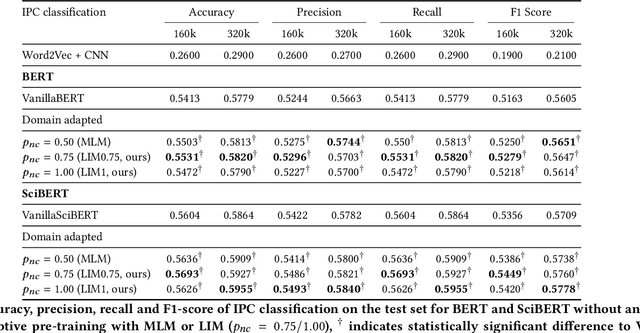
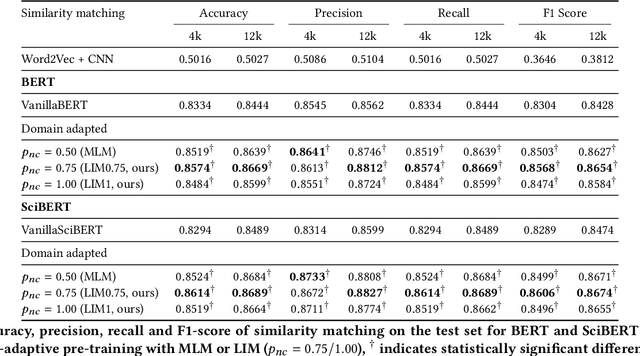
Domain-specific contextualized language models have demonstrated substantial effectiveness gains for domain-specific downstream tasks, like similarity matching, entity recognition or information retrieval. However successfully applying such models in highly specific language domains requires domain adaptation of the pre-trained models. In this paper we propose the empirically motivated Linguistically Informed Masking (LIM) method to focus domain-adaptative pre-training on the linguistic patterns of patents, which use a highly technical sublanguage. We quantify the relevant differences between patent, scientific and general-purpose language and demonstrate for two different language models (BERT and SciBERT) that domain adaptation with LIM leads to systematically improved representations by evaluating the performance of the domain-adapted representations of patent language on two independent downstream tasks, the IPC classification and similarity matching. We demonstrate the impact of balancing the learning from different information sources during domain adaptation for the patent domain. We make the source code as well as the domain-adaptive pre-trained patent language models publicly available at https://github.com/sophiaalthammer/patent-lim.