 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-policy Evaluation in Infinite-Horizon Reinforcement Learning with Latent Confounders
Jul 27, 2020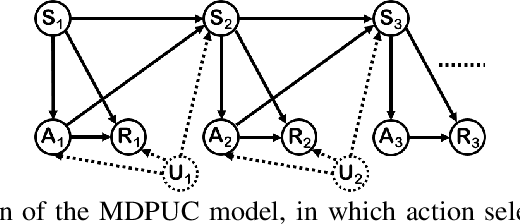
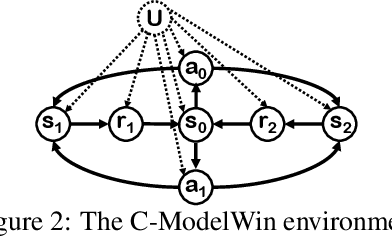

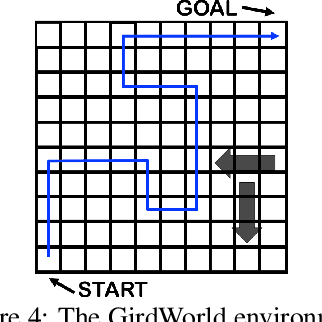
Off-policy evaluation (OPE) in reinforcement learning is an important problem in settings where experimentation is limited, such as education and healthcare. But, in these very same settings, observed actions are often confounded by unobserved variables making OPE even more difficult. We study an OPE problem in an infinite-horizon, ergodic Markov decision process with unobserved confounders, where states and actions can act as proxies for the unobserved confounders. We show how, given only a latent variable model for states and actions, policy value can be identified from off-policy data. Our method involves two stages. In the first, we show how to use proxies to estimate stationary distribution ratios, extending recent work on breaking the curse of horizon to the confounded setting. In the second, we show optimal balancing can be combined with such learned ratios to obtain policy value while avoiding direct modeling of reward functions. We establish theoretical guarantees of consistency, and benchmark our method empirically.
Black-box Off-policy Estimation for Infinite-Horizon Reinforcement Learning
Mar 24, 2020



Off-policy estimation for long-horizon problems is important in many real-life applications such as healthcare and robotics, where high-fidelity simulators may not be available and on-policy evaluation is expensive or impossible. Recently, \cite{liu18breaking} proposed an approach that avoids the \emph{curse of horizon} suffered by typical importance-sampling-based methods. While showing promising results, this approach is limited in practice as it requires data be drawn from the \emph{stationary distribution} of a \emph{known} behavior policy. In this work, we propose a novel approach that eliminates such limitations. In particular, we formulate the problem as solving for the fixed point of a certain operator. Using tools from Reproducing Kernel Hilbert Spaces (RKHSs), we develop a new estimator that computes importance ratios of stationary distributions, without knowledge of how the off-policy data are collected. We analyze its asymptotic consistency and finite-sample generalization. Experiments on benchmarks verify the effectiveness of our approach.
Unsupervised Learning with Stein's Unbiased Risk Estimator
May 26, 2018
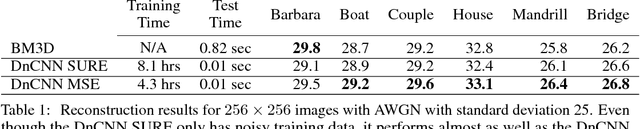

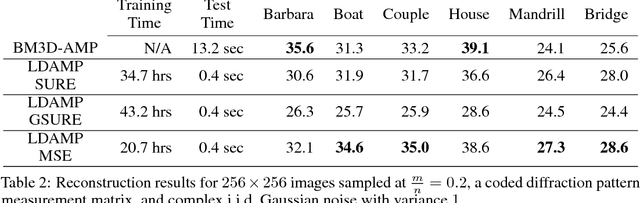
Learning from unlabeled and noisy data is one of the grand challenges of machine learning. As such, it has seen a flurry of research with new ideas proposed continuously. In this work, we revisit a classical idea: Stein's Unbiased Risk Estimator (SURE). We show that, in the context of image recovery, SURE and its generalizations can be used to train convolutional neural networks (CNNs) for a range of image denoising and recovery problems {\em without any ground truth data.} Specifically, our goal is to reconstruct an image $x$ from a {\em noisy} linear transformation (measurement) of the image. We consider two scenarios: one where no additional data is available and one where we have measurements of other images that are drawn from the same noisy distribution as $x$, but have no access to the clean images. Such is the case, for instance, in the context of medical imaging, microscopy, and astronomy, where noise-less ground truth data is rarely available. We show that in this situation, SURE can be used to estimate the mean-squared-error loss associated with an estimate of $x$. Using this estimate of the loss, we train networks to perform denoising and compressed sensing recovery. In addition, we also use the SURE framework to partially explain and improve upon an intriguing results presented by Ulyanov et al. in "Deep Image Prior": that a network initialized with random weights and fit to a single noisy image can effectively denoise that image.
Learned D-AMP: Principled Neural Network based Compressive Image Recovery
Nov 06, 2017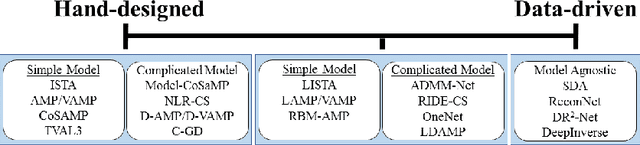
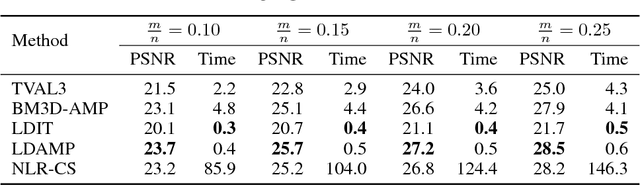
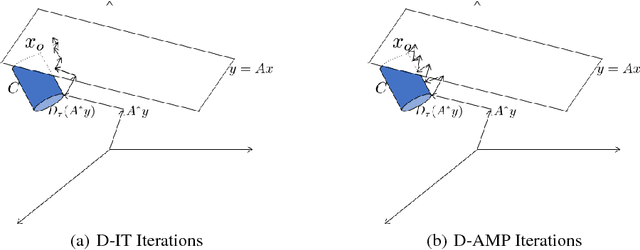
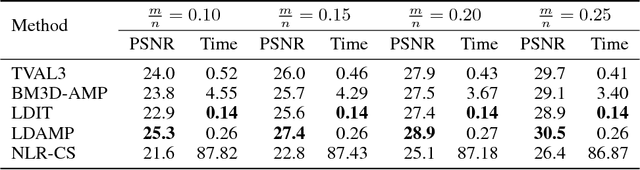
Compressive image recovery is a challenging problem that requires fast and accurate algorithms. Recently, neural networks have been applied to this problem with promising results. By exploiting massively parallel GPU processing architectures and oodles of training data, they can run orders of magnitude faster than existing techniques. However, these methods are largely unprincipled black boxes that are difficult to train and often-times specific to a single measurement matrix. It was recently demonstrated that iterative sparse-signal-recovery algorithms can be "unrolled" to form interpretable deep networks. Taking inspiration from this work, we develop a novel neural network architecture that mimics the behavior of the denoising-based approximate message passing (D-AMP) algorithm. We call this new network Learned D-AMP (LDAMP). The LDAMP network is easy to train, can be applied to a variety of different measurement matrices, and comes with a state-evolution heuristic that accurately predicts its performance. Most importantly, it outperforms the state-of-the-art BM3D-AMP and NLR-CS algorithms in terms of both accuracy and run time. At high resolutions, and when used with sensing matrices that have fast implementations, LDAMP runs over $50\times$ faster than BM3D-AMP and hundreds of times faster than NLR-CS.
DeepCodec: Adaptive Sensing and Recovery via Deep Convolutional Neural Networks
Jul 11, 2017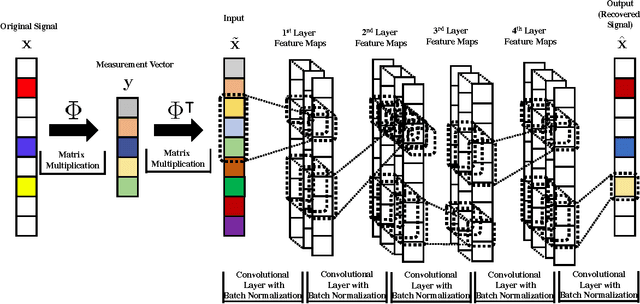
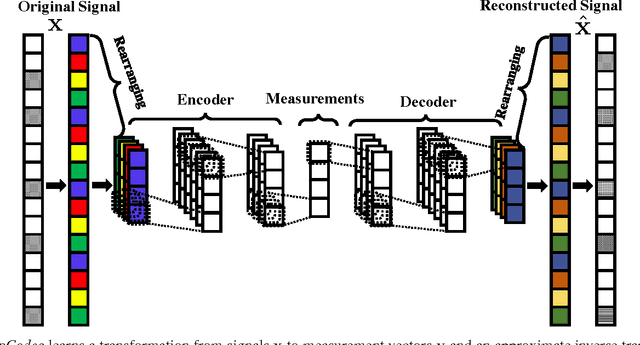
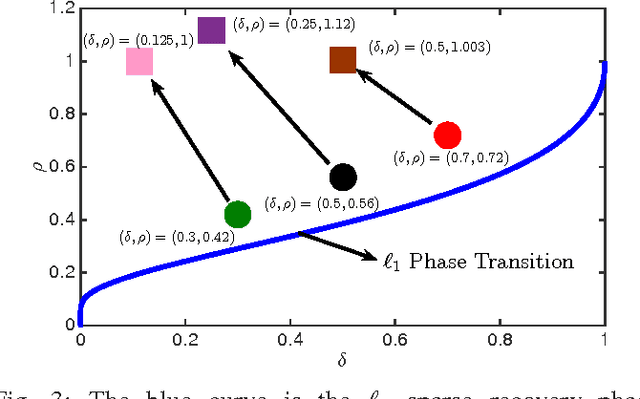
In this paper we develop a novel computational sensing framework for sensing and recovering structured signals. When trained on a set of representative signals, our framework learns to take undersampled measurements and recover signals from them using a deep convolutional neural network. In other words, it learns a transformation from the original signals to a near-optimal number of undersampled measurements and the inverse transformation from measurements to signals. This is in contrast to traditional compressive sensing (CS) systems that use random linear measurements and convex optimization or iterative algorithms for signal recovery. We compare our new framework with $\ell_1$-minimization from the phase transition point of view and demonstrate that it outperforms $\ell_1$-minimization in the regions of phase transition plot where $\ell_1$-minimization cannot recover the exact solution. In addition, we experimentally demonstrate how learning measurements enhances the overall recovery performance, speeds up training of recovery framework, and leads to having fewer parameters to learn.
Learning to Invert: Signal Recovery via Deep Convolutional Networks
Jan 14, 2017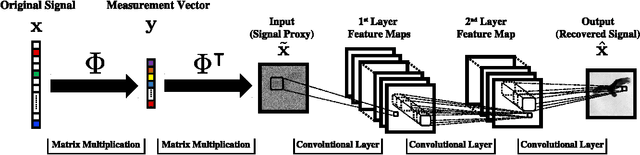
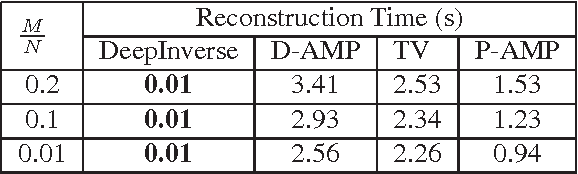
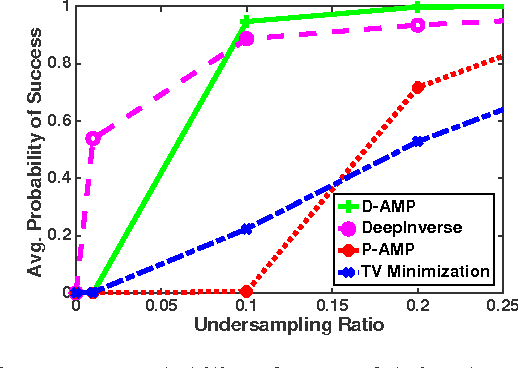

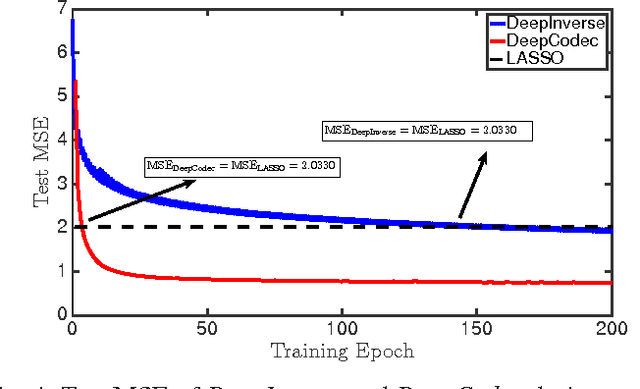
The promise of compressive sensing (CS) has been offset by two significant challenges. First, real-world data is not exactly sparse in a fixed basis. Second, current high-performance recovery algorithms are slow to converge, which limits CS to either non-real-time applications or scenarios where massive back-end computing is available. In this paper, we attack both of these challenges head-on by developing a new signal recovery framework we call {\em DeepInverse} that learns the inverse transformation from measurement vectors to signals using a {\em deep convolutional network}. When trained on a set of representative images, the network learns both a representation for the signals (addressing challenge one) and an inverse map approximating a greedy or convex recovery algorithm (addressing challenge two). Our experiments indicate that the DeepInverse network closely approximates the solution produced by state-of-the-art CS recovery algorithms yet is hundreds of times faster in run time. The tradeoff for the ultrafast run time is a computationally intensive, off-line training procedure typical to deep networks. However, the training needs to be completed only once, which makes the approach attractive for a host of sparse recovery problems.
Consistent Parameter Estimation for LASSO and Approximate Message Passing
Nov 04, 2015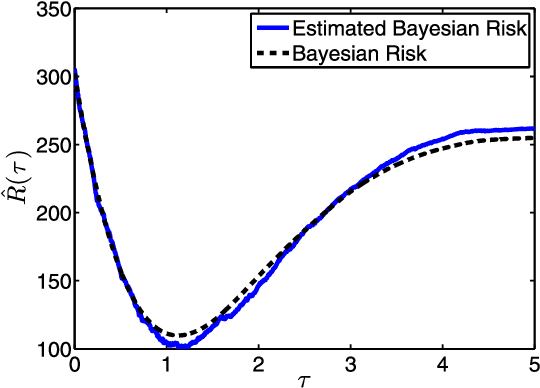
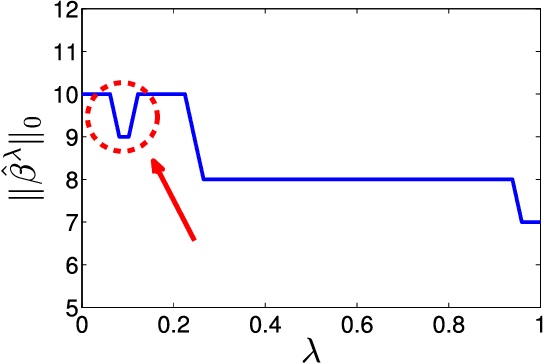
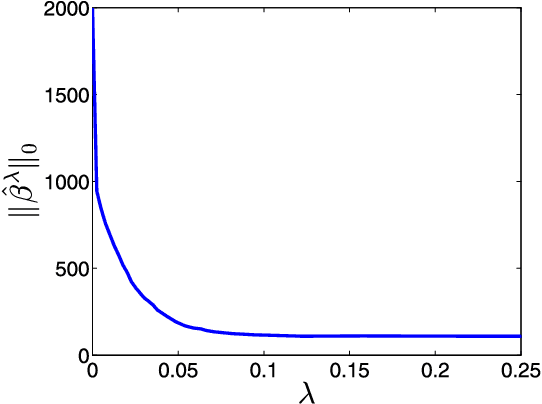
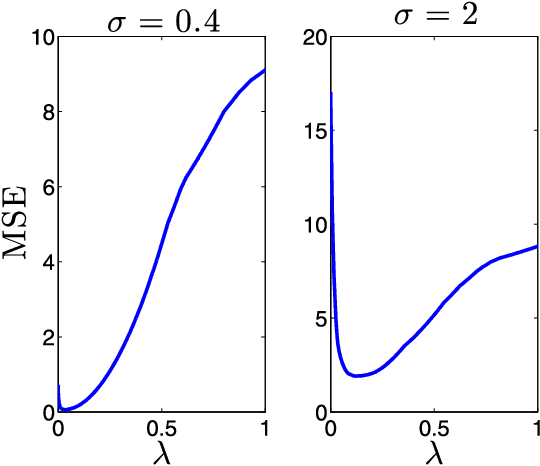
We consider the problem of recovering a vector $\beta_o \in \mathbb{R}^p$ from $n$ random and noisy linear observations $y= X\beta_o + w$, where $X$ is the measurement matrix and $w$ is noise. The LASSO estimate is given by the solution to the optimization problem $\hat{\beta}_{\lambda} = \arg \min_{\beta} \frac{1}{2} \|y-X\beta\|_2^2 + \lambda \| \beta \|_1$. Among the iterative algorithms that have been proposed for solving this optimization problem, approximate message passing (AMP) has attracted attention for its fast convergence. Despite significant progress in the theoretical analysis of the estimates of LASSO and AMP, little is known about their behavior as a function of the regularization parameter $\lambda$, or the thereshold parameters $\tau^t$. For instance the following basic questions have not yet been studied in the literature: (i) How does the size of the active set $\|\hat{\beta}^\lambda\|_0/p$ behave as a function of $\lambda$? (ii) How does the mean square error $\|\hat{\beta}_{\lambda} - \beta_o\|_2^2/p$ behave as a function of $\lambda$? (iii) How does $\|\beta^t - \beta_o \|_2^2/p$ behave as a function of $\tau^1, \ldots, \tau^{t-1}$? Answering these questions will help in addressing practical challenges regarding the optimal tuning of $\lambda$ or $\tau^1, \tau^2, \ldots$. This paper answers these questions in the asymptotic setting and shows how these results can be employed in deriving simple and theoretically optimal approaches for tuning the parameters $\tau^1, \ldots, \tau^t$ for AMP or $\lambda$ for LASSO. It also explores the connection between the optimal tuning of the parameters of AMP and the optimal tuning of LASSO.
A Deep Learning Approach to Structured Signal Recovery
Aug 17, 2015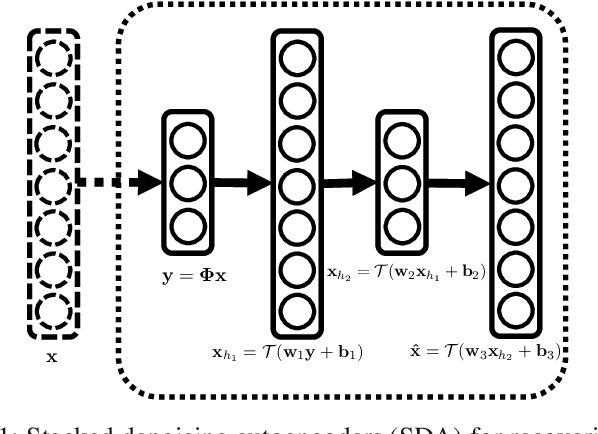
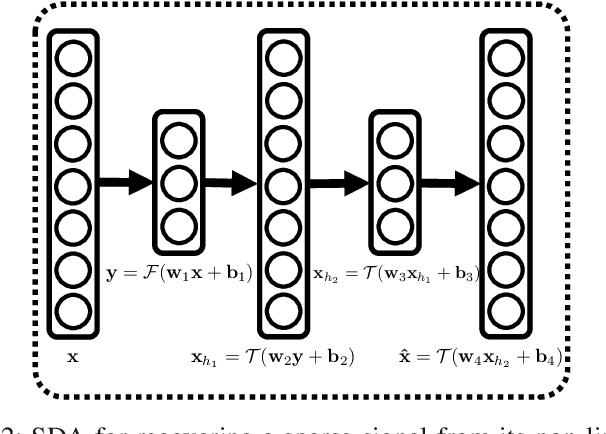

In this paper, we develop a new framework for sensing and recovering structured signals. In contrast to compressive sensing (CS) systems that employ linear measurements, sparse representations, and computationally complex convex/greedy algorithms, we introduce a deep learning framework that supports both linear and mildly nonlinear measurements, that learns a structured representation from training data, and that efficiently computes a signal estimate. In particular, we apply a stacked denoising autoencoder (SDA), as an unsupervised feature learner. SDA enables us to capture statistical dependencies between the different elements of certain signals and improve signal recovery performance as compared to the CS approach.
Parameterless Optimal Approximate Message Passing
Oct 31, 2013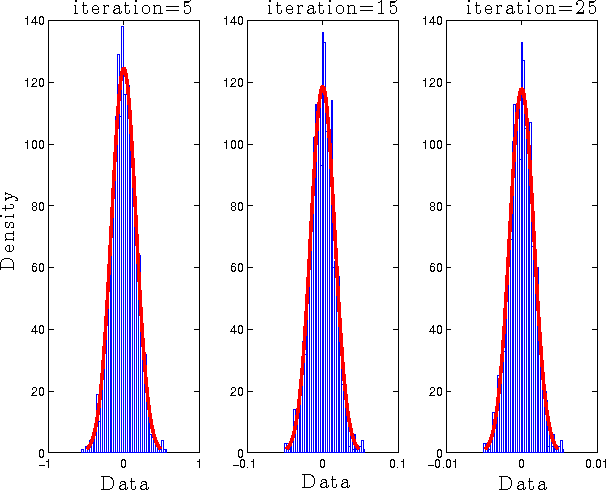
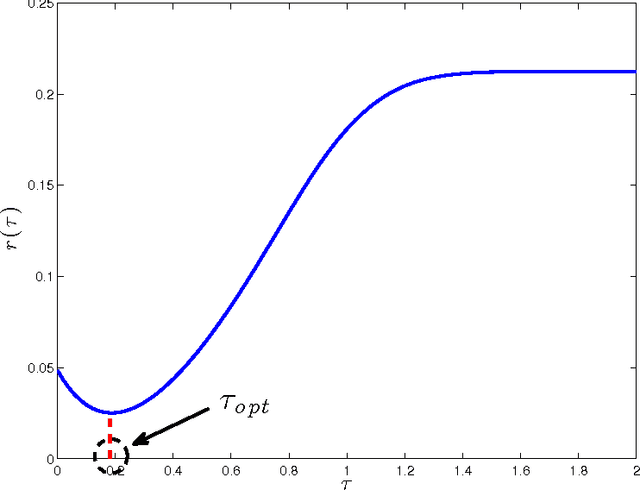
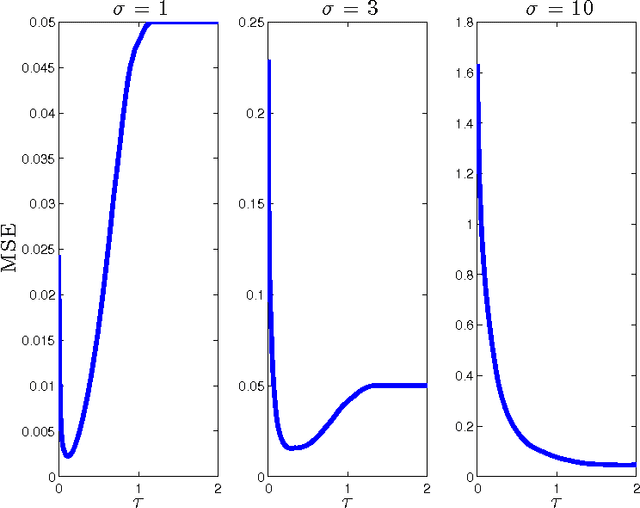
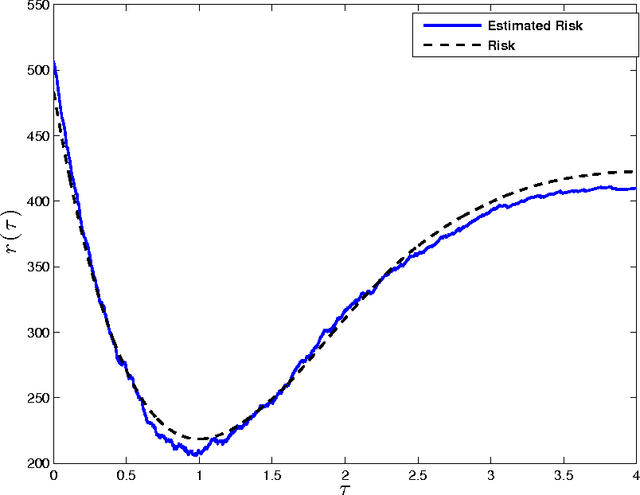
Iterative thresholding algorithms are well-suited for high-dimensional problems in sparse recovery and compressive sensing. The performance of this class of algorithms depends heavily on the tuning of certain threshold parameters. In particular, both the final reconstruction error and the convergence rate of the algorithm crucially rely on how the threshold parameter is set at each step of the algorithm. In this paper, we propose a parameter-free approximate message passing (AMP) algorithm that sets the threshold parameter at each iteration in a fully automatic way without either having an information about the signal to be reconstructed or needing any tuning from the user. We show that the proposed method attains both the minimum reconstruction error and the highest convergence rate. Our method is based on applying the Stein unbiased risk estimate (SURE) along with a modified gradient descent to find the optimal threshold in each iteration. Motivated by the connections between AMP and LASSO, it could be employed to find the solution of the LASSO for the optimal regularization parameter. To the best of our knowledge, this is the first work concerning parameter tuning that obtains the fastest convergence rate with theoretical guarantees.
Asymptotic Analysis of LASSOs Solution Path with Implications for Approximate Message Passing
Sep 23, 2013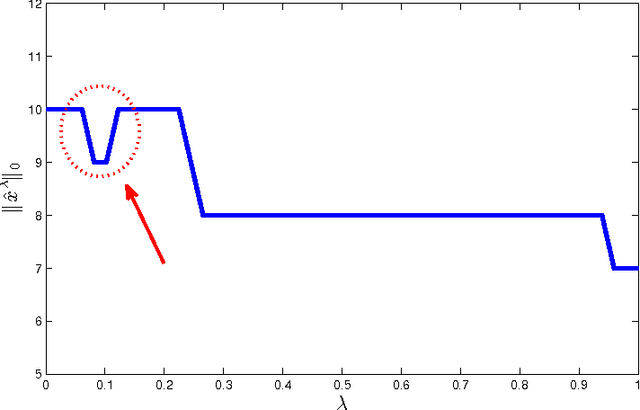
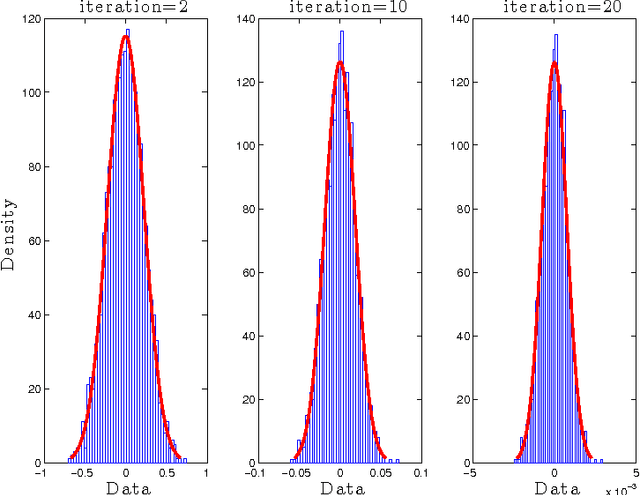
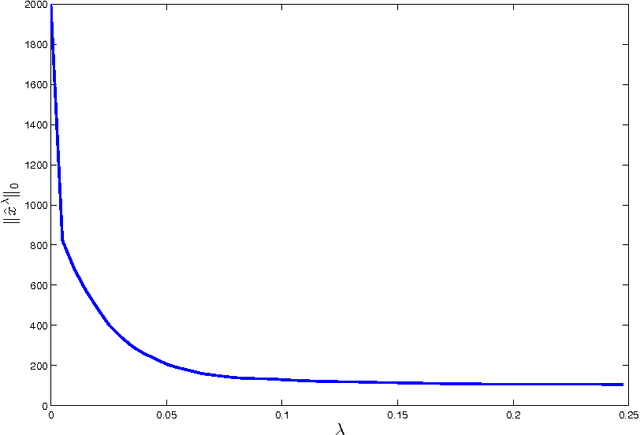
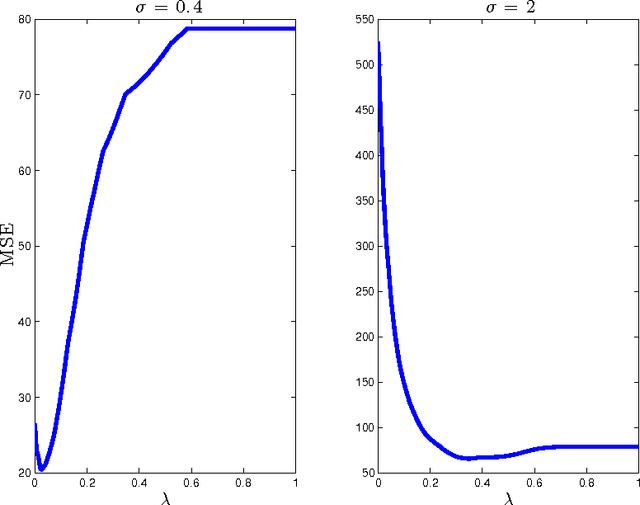
This paper concerns the performance of the LASSO (also knows as basis pursuit denoising) for recovering sparse signals from undersampled, randomized, noisy measurements. We consider the recovery of the signal $x_o \in \mathbb{R}^N$ from $n$ random and noisy linear observations $y= Ax_o + w$, where $A$ is the measurement matrix and $w$ is the noise. The LASSO estimate is given by the solution to the optimization problem $x_o$ with $\hat{x}_{\lambda} = \arg \min_x \frac{1}{2} \|y-Ax\|_2^2 + \lambda \|x\|_1$. Despite major progress in the theoretical analysis of the LASSO solution, little is known about its behavior as a function of the regularization parameter $\lambda$. In this paper we study two questions in the asymptotic setting (i.e., where $N \rightarrow \infty$, $n \rightarrow \infty$ while the ratio $n/N$ converges to a fixed number in $(0,1)$): (i) How does the size of the active set $\|\hat{x}_\lambda\|_0/N$ behave as a function of $\lambda$, and (ii) How does the mean square error $\|\hat{x}_{\lambda} - x_o\|_2^2/N$ behave as a function of $\lambda$? We then employ these results in a new, reliable algorithm for solving LASSO based on approximate message passing (AMP).