 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of self-supervised pre-training for speech recognition
Nov 10, 2019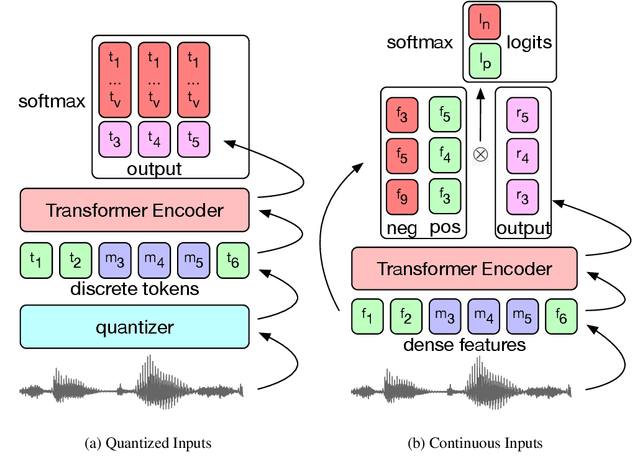
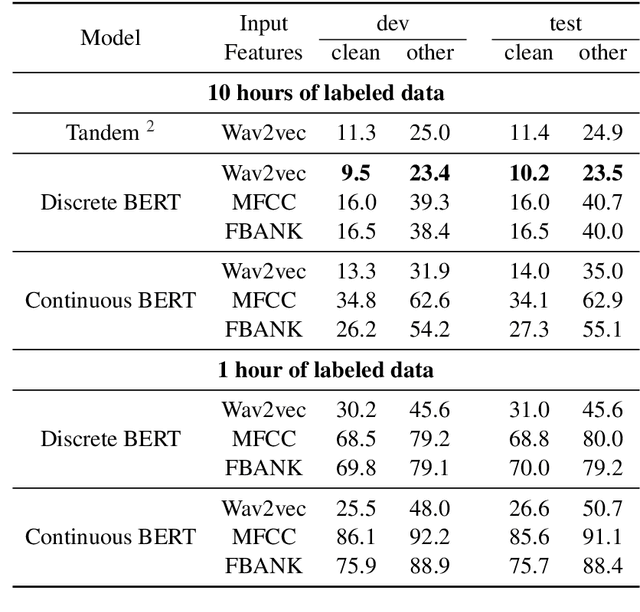
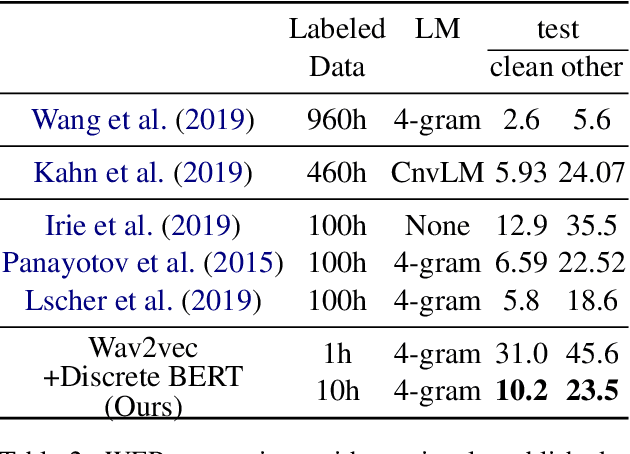
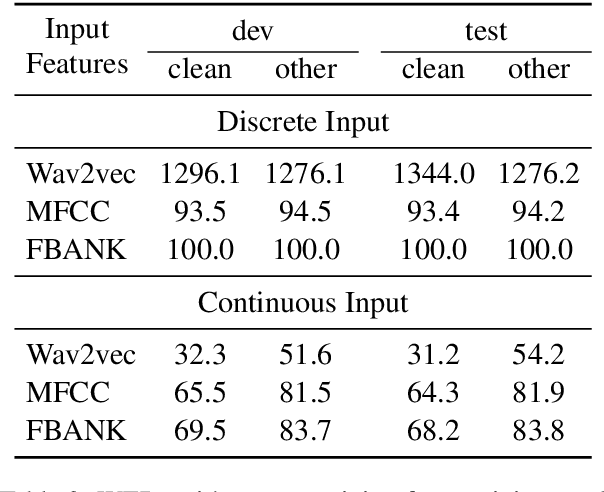
We present pre-training approaches for self-supervised representation learning of speech data. A BERT, masked language model, loss on discrete features is compared with an InfoNCE-based constrastive loss on continuous speech features. The pre-trained models are then fine-tuned with a Connectionist Temporal Classification (CTC) loss to predict target character sequences. To study impact of stacking multiple feature learning modules trained using different self-supervised loss functions, we test the discrete and continuous BERT pre-training approaches on spectral features and on learned acoustic representations, showing synergitic behaviour between acoustically motivated and masked language model loss functions. In low-resource conditions using only 10 hours of labeled data, we achieve Word Error Rates (WER) of 10.2\% and 23.5\% on the standard test "clean" and "other" benchmarks of the Librispeech dataset, which is almost on bar with previously published work that uses 10 times more labeled data. Moreover, compared to previous work that uses two models in tandem, by using one model for both BERT pre-trainining and fine-tuning, our model provides an average relative WER reduction of 9%.
vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
Oct 12, 2019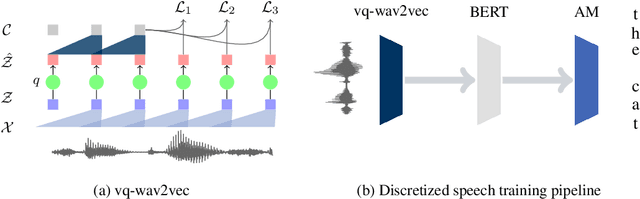
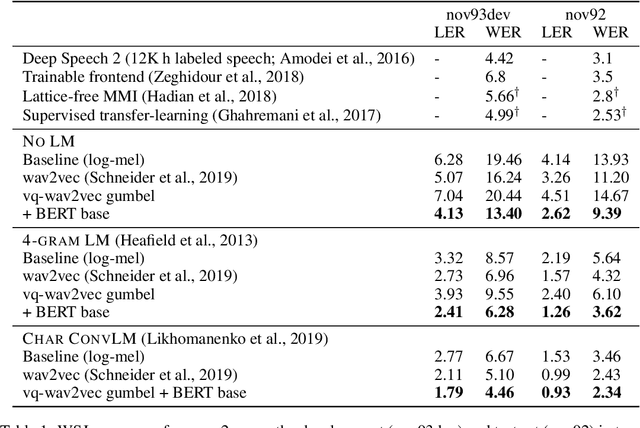
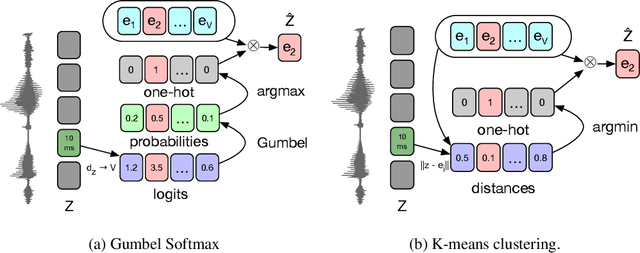
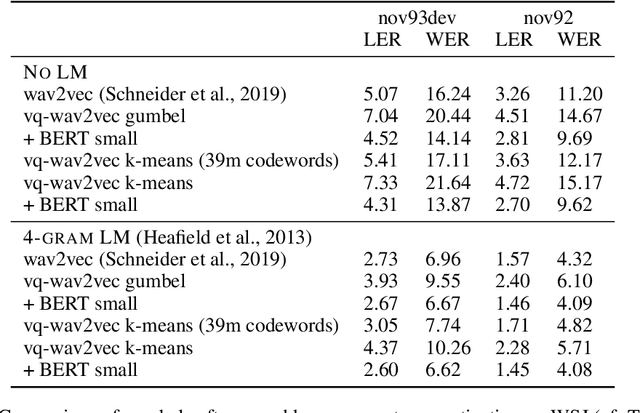
We propose vq-wav2vec to learn discrete representations of audio segments through a wav2vec-style self-supervised context prediction task. The algorithm uses either a gumbel softmax or online k-means clustering to quantize the dense representations. Discretization enables the direct application of algorithms from the NLP community which require discrete inputs. Experiments show that BERT pre-training achieves a new state of the art on TIMIT phoneme classification and WSJ speech recognition.
Facebook FAIR's WMT19 News Translation Task Submission
Jul 15, 2019
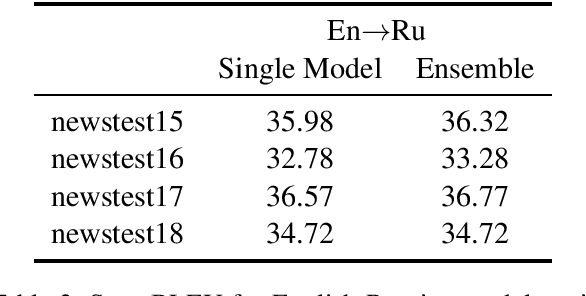
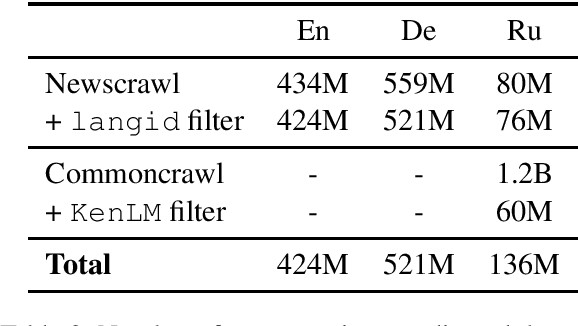
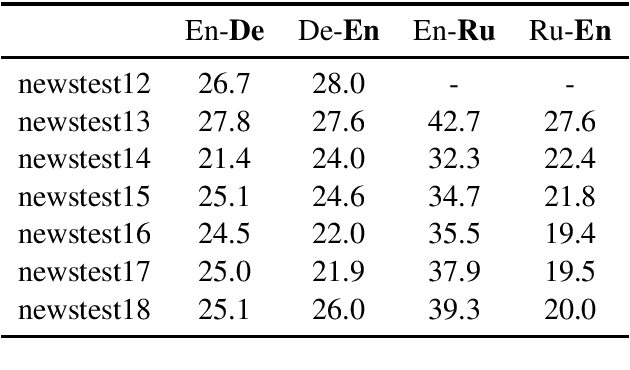
This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes, as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations. This system improves upon our WMT'18 submission by 4.5 BLEU points.
wav2vec: Unsupervised Pre-training for Speech Recognition
May 24, 2019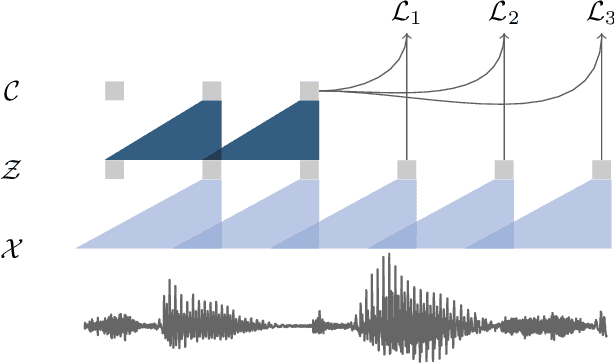
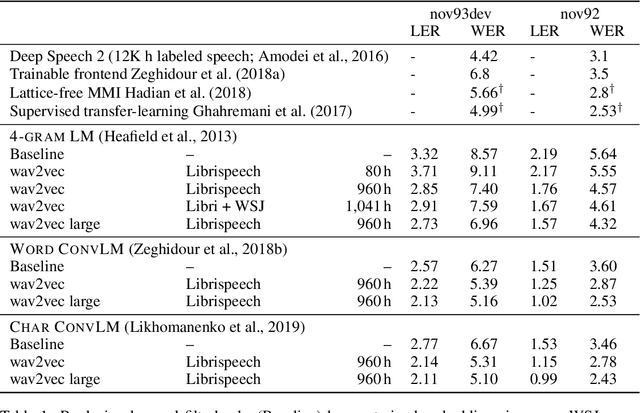
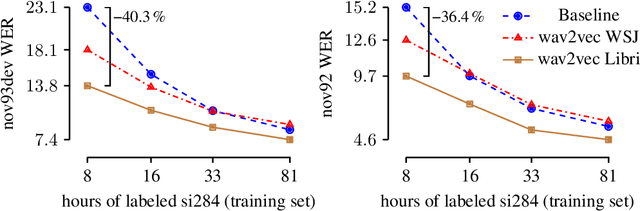
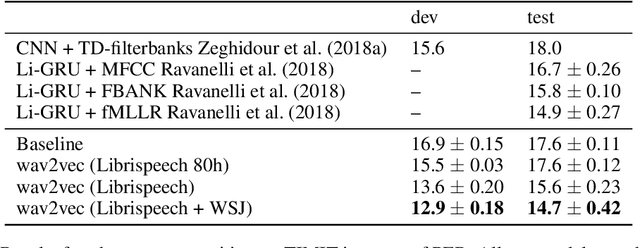
We explore unsupervised pre-training for speech recognition by learning representations of raw audio. wav2vec is trained on large amounts of unlabeled audio data and the resulting representations are then used to improve acoustic model training. We pre-train a simple multi-layer convolutional neural network optimized via a noise contrastive binary classification task. Our experiments on WSJ reduce WER of a strong character-based log-mel filterbank baseline by up to 32% when only a few hours of transcribed data is available. Our approach achieves 2.43% WER on the nov92 test set. This outperforms Deep Speech 2, the best reported character-based system in the literature while using three orders of magnitude less labeled training data.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019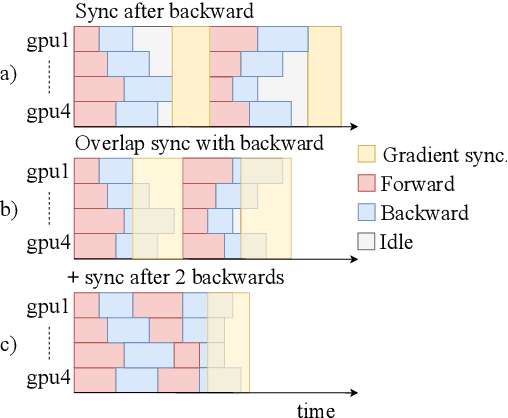

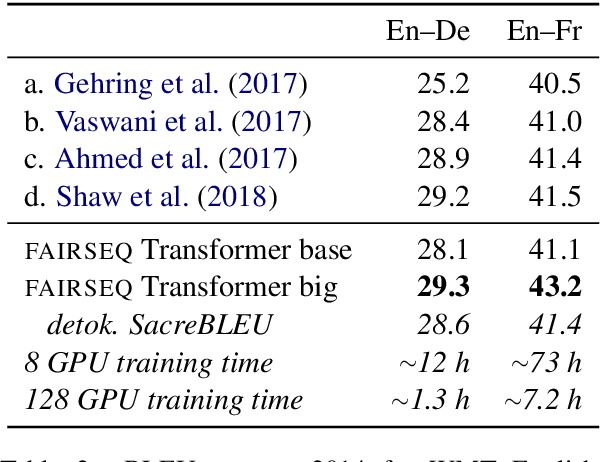
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Pre-trained Language Model Representations for Language Generation
Apr 01, 2019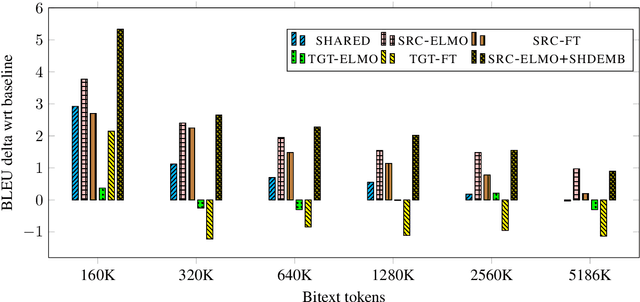
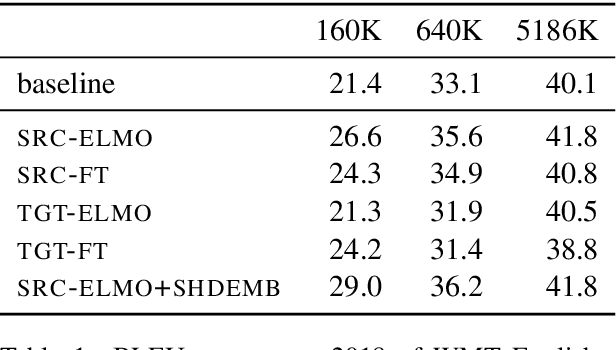

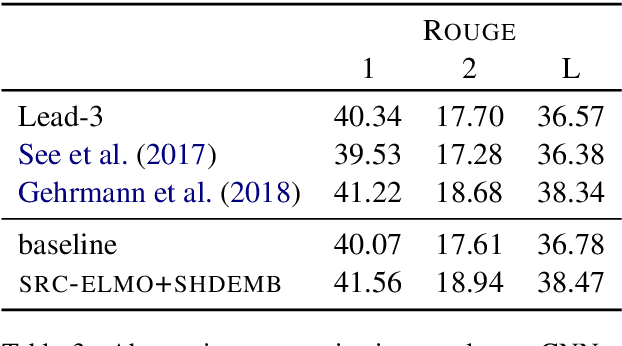
Pre-trained language model representations have been successful in a wide range of language understanding tasks. In this paper, we examine different strategies to integrate pre-trained representations into sequence to sequence models and apply it to neural machine translation and abstractive summarization. We find that pre-trained representations are most effective when added to the encoder network which slows inference by only 14%. Our experiments in machine translation show gains of up to 5.3 BLEU in a simulated resource-poor setup. While returns diminish with more labeled data, we still observe improvements when millions of sentence-pairs are available. Finally, on abstractive summarization we achieve a new state of the art on the full text version of CNN/DailyMail.
Cloze-driven Pretraining of Self-attention Networks
Mar 19, 2019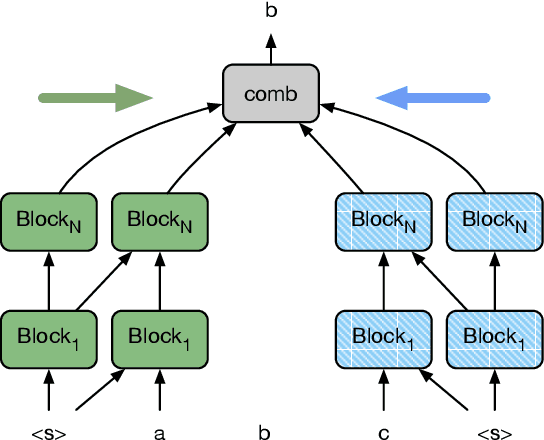
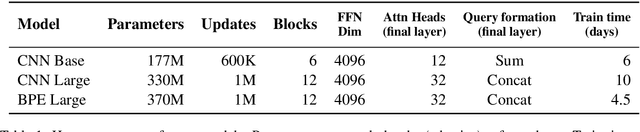
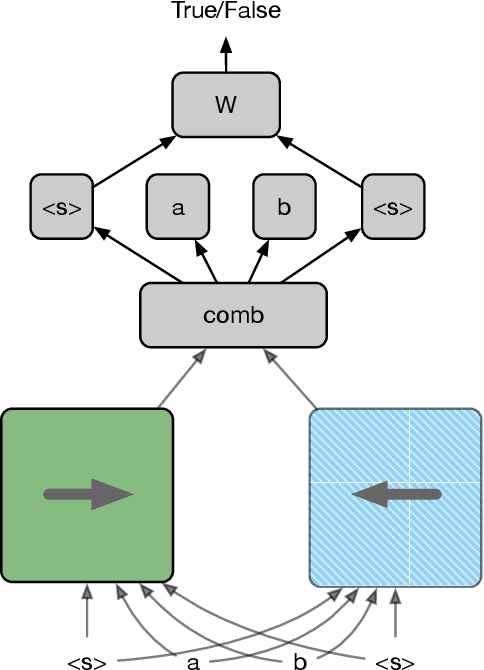
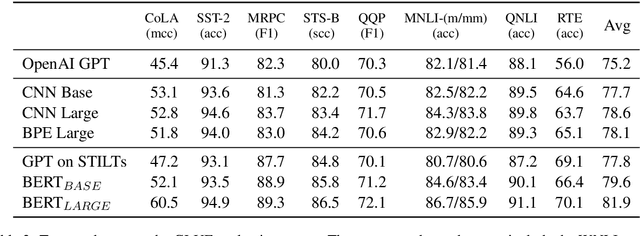
We present a new approach for pretraining a bi-directional transformer model that provides significant performance gains across a variety of language understanding problems. Our model solves a cloze-style word reconstruction task, where each word is ablated and must be predicted given the rest of the text. Experiments demonstrate large performance gains on GLUE and new state of the art results on NER as well as constituency parsing benchmarks, consistent with the concurrently introduced BERT model. We also present a detailed analysis of a number of factors that contribute to effective pretraining, including data domain and size, model capacity, and variations on the cloze objective.
Pay Less Attention with Lightweight and Dynamic Convolutions
Jan 29, 2019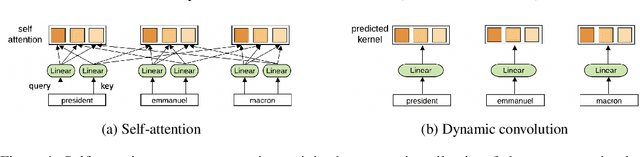
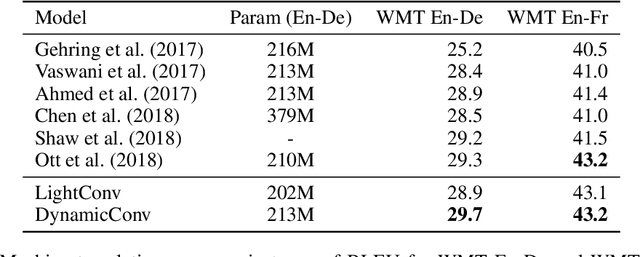
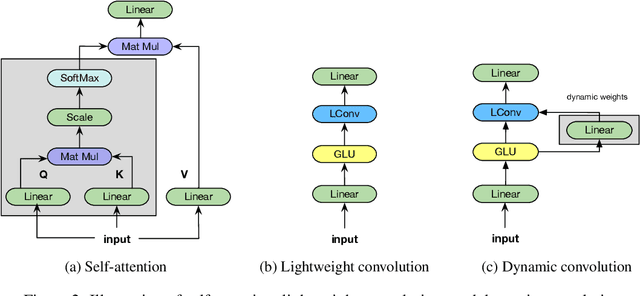
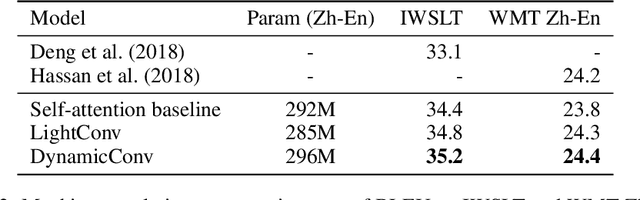
Self-attention is a useful mechanism to build generative models for language and images. It determines the importance of context elements by comparing each element to the current time step. In this paper, we show that a very lightweight convolution can perform competitively to the best reported self-attention results. Next, we introduce dynamic convolutions which are simpler and more efficient than self-attention. We predict separate convolution kernels based solely on the current time-step in order to determine the importance of context elements. The number of operations required by this approach scales linearly in the input length, whereas self-attention is quadratic. Experiments on large-scale machine translation, language modeling and abstractive summarization show that dynamic convolutions improve over strong self-attention models. On the WMT'14 English-German test set dynamic convolutions achieve a new state of the art of 29.7 BLEU.
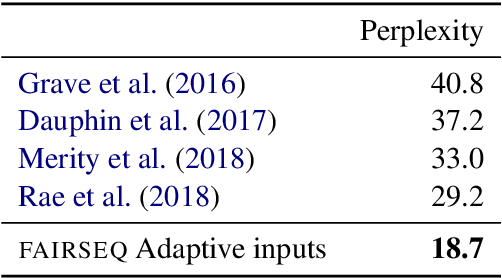
Adaptive Input Representations for Neural Language Modeling
Oct 01, 2018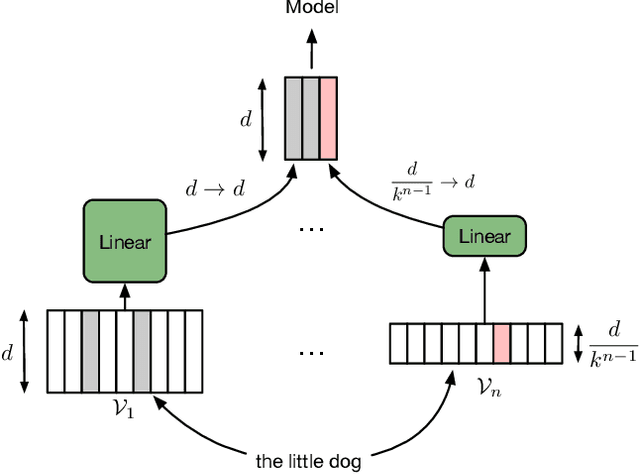
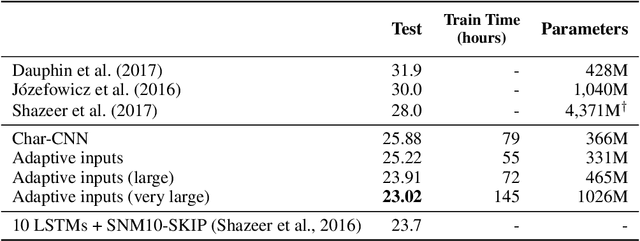
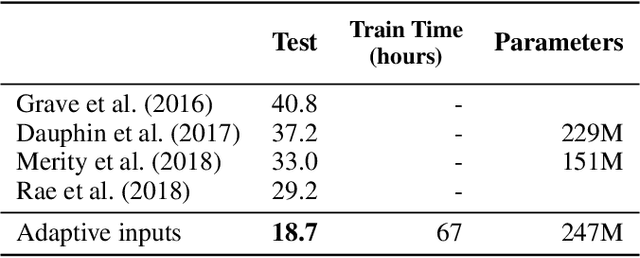
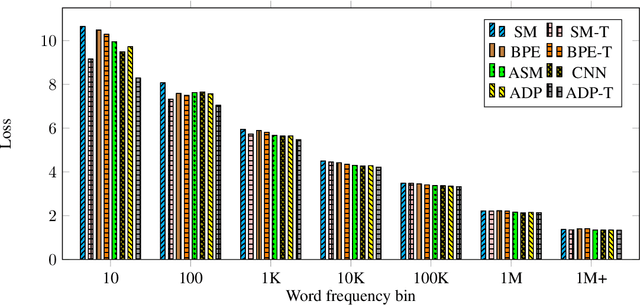
We introduce adaptive input representations for neural language modeling which extend the adaptive softmax of Grave et al. (2017) to input representations of variable capacity. There are several choices on how to factorize the input and output layers, and whether to model words, characters or sub-word units. We perform a systematic comparison of popular choices for a self-attentional architecture. Our experiments show that models equipped with adaptive embeddings are more than twice as fast to train than the popular character input CNN while having a lower number of parameters. We achieve a new state of the art on the WikiText-103 benchmark of 20.51 perplexity, improving the next best known result by 8.7 perplexity. On the Billion word benchmark, we achieve a state of the art of 24.14 perplexity.