 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of self-supervised pre-training for speech recognition
Paper and Code
Nov 10, 2019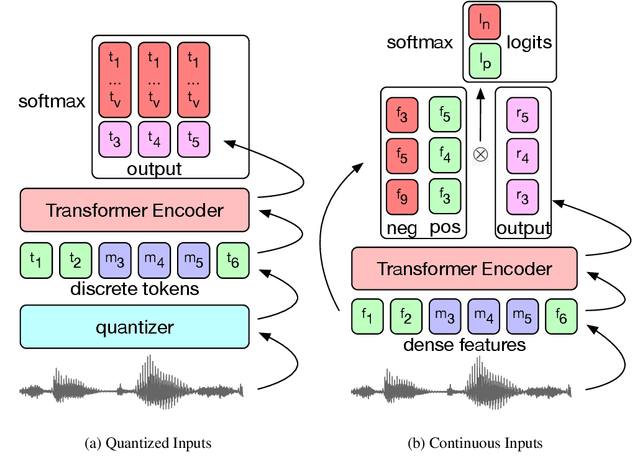
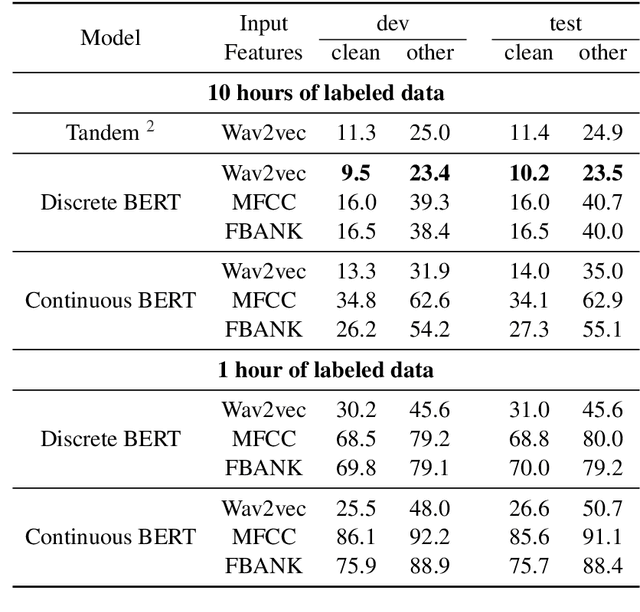
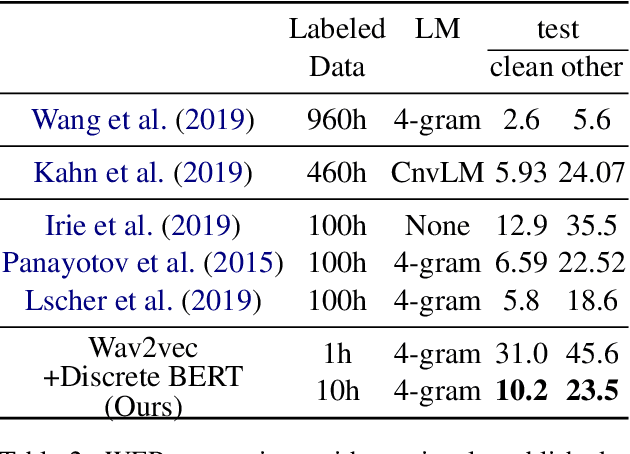
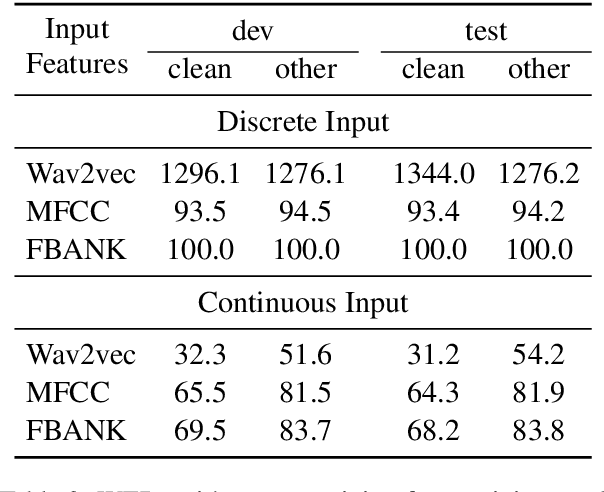
We present pre-training approaches for self-supervised representation learning of speech data. A BERT, masked language model, loss on discrete features is compared with an InfoNCE-based constrastive loss on continuous speech features. The pre-trained models are then fine-tuned with a Connectionist Temporal Classification (CTC) loss to predict target character sequences. To study impact of stacking multiple feature learning modules trained using different self-supervised loss functions, we test the discrete and continuous BERT pre-training approaches on spectral features and on learned acoustic representations, showing synergitic behaviour between acoustically motivated and masked language model loss functions. In low-resource conditions using only 10 hours of labeled data, we achieve Word Error Rates (WER) of 10.2\% and 23.5\% on the standard test "clean" and "other" benchmarks of the Librispeech dataset, which is almost on bar with previously published work that uses 10 times more labeled data. Moreover, compared to previous work that uses two models in tandem, by using one model for both BERT pre-trainining and fine-tuning, our model provides an average relative WER reduction of 9%.