Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloze-driven Pretraining of Self-attention Networks
Paper and Code
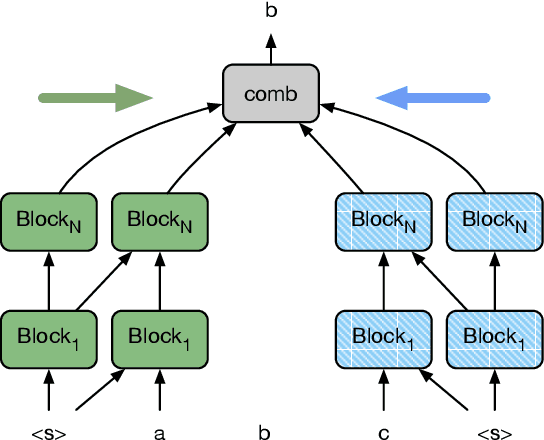
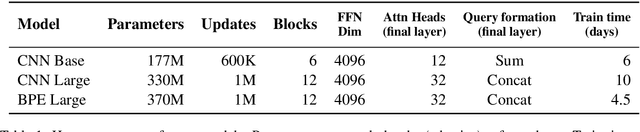
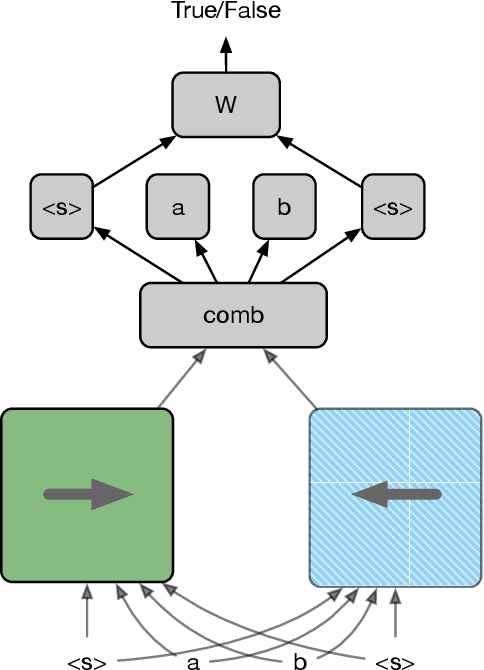
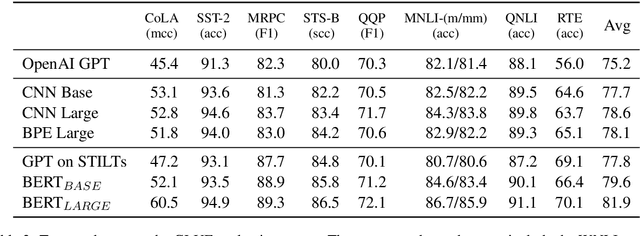
We present a new approach for pretraining a bi-directional transformer model that provides significant performance gains across a variety of language understanding problems. Our model solves a cloze-style word reconstruction task, where each word is ablated and must be predicted given the rest of the text. Experiments demonstrate large performance gains on GLUE and new state of the art results on NER as well as constituency parsing benchmarks, consistent with the concurrently introduced BERT model. We also present a detailed analysis of a number of factors that contribute to effective pretraining, including data domain and size, model capacity, and variations on the cloze objective.
View paper on