 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster independent component analysis by preconditioning with Hessian approximations
Sep 08, 2017
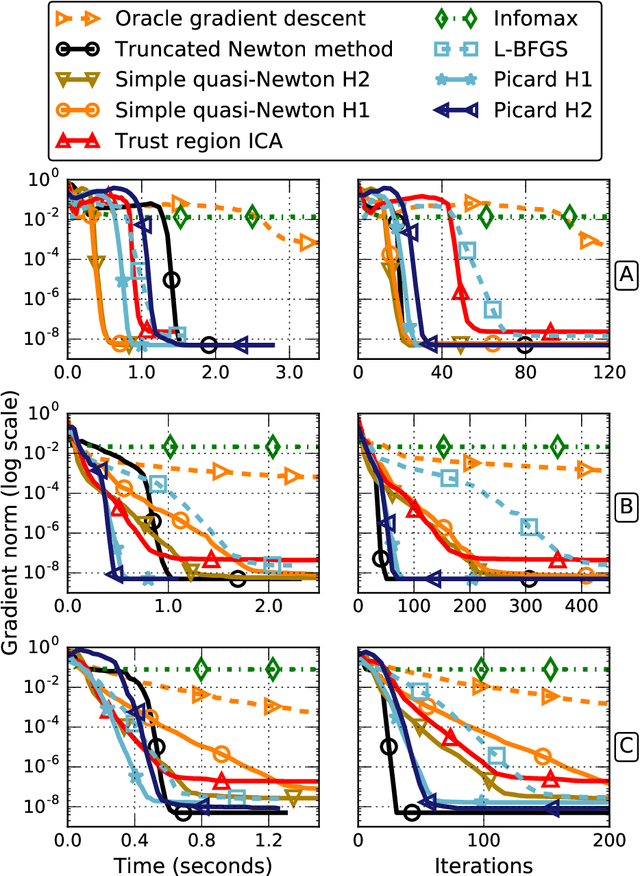
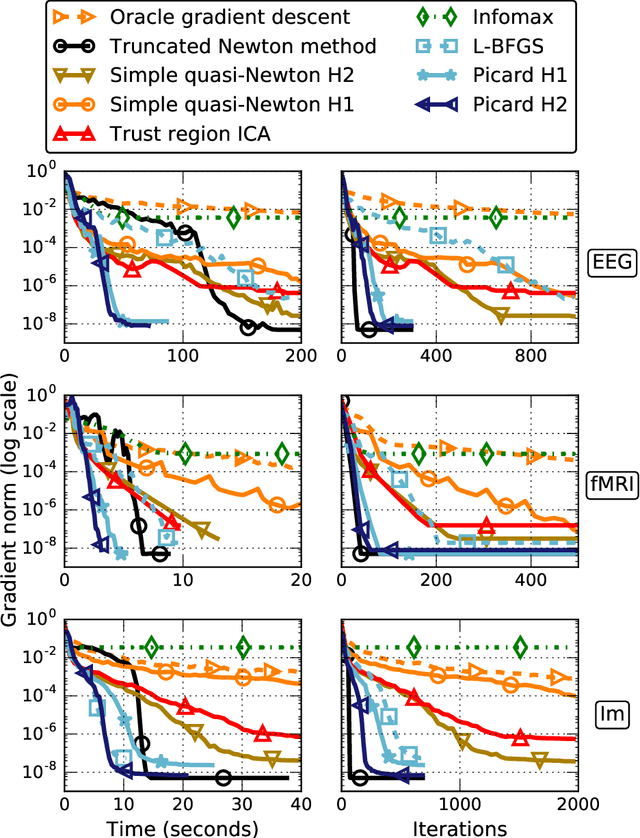
Independent Component Analysis (ICA) is a technique for unsupervised exploration of multi-channel data that is widely used in observational sciences. In its classic form, ICA relies on modeling the data as linear mixtures of non-Gaussian independent sources. The maximization of the corresponding likelihood is a challenging problem if it has to be completed quickly and accurately on large sets of real data. We introduce the Preconditioned ICA for Real Data (Picard) algorithm, which is a relative L-BFGS algorithm preconditioned with sparse Hessian approximations. Extensive numerical comparisons to several algorithms of the same class demonstrate the superior performance of the proposed technique, especially on real data, for which the ICA model does not necessarily hold.
On the Consistency of Ordinal Regression Methods
Jul 21, 2017
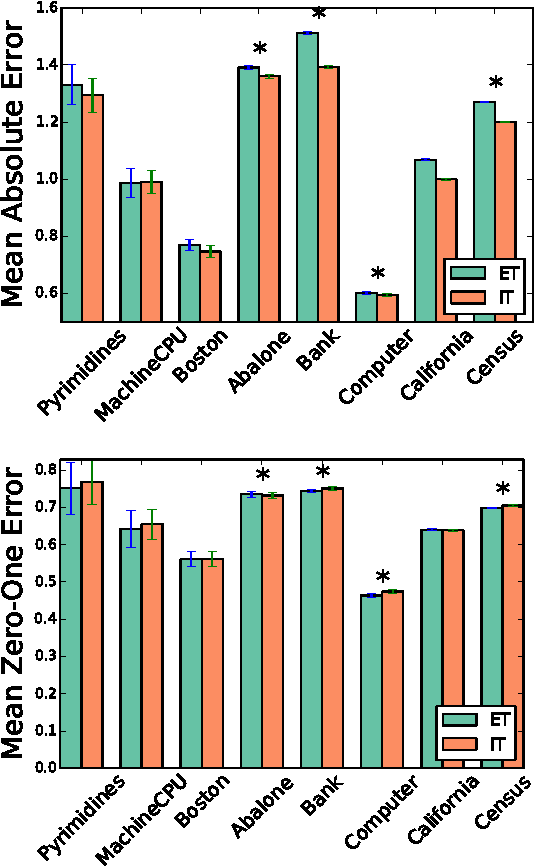
Many of the ordinal regression models that have been proposed in the literature can be seen as methods that minimize a convex surrogate of the zero-one, absolute, or squared loss functions. A key property that allows to study the statistical implications of such approximations is that of Fisher consistency. Fisher consistency is a desirable property for surrogate loss functions and implies that in the population setting, i.e., if the probability distribution that generates the data were available, then optimization of the surrogate would yield the best possible model. In this paper we will characterize the Fisher consistency of a rich family of surrogate loss functions used in the context of ordinal regression, including support vector ordinal regression, ORBoosting and least absolute deviation. We will see that, for a family of surrogate loss functions that subsumes support vector ordinal regression and ORBoosting, consistency can be fully characterized by the derivative of a real-valued function at zero, as happens for convex margin-based surrogates in binary classification. We also derive excess risk bounds for a surrogate of the absolute error that generalize existing risk bounds for binary classification. Finally, our analysis suggests a novel surrogate of the squared error loss. We compare this novel surrogate with competing approaches on 9 different datasets. Our method shows to be highly competitive in practice, outperforming the least squares loss on 7 out of 9 datasets.
* Journal of Machine Learning Research 18 (2017)
Learning the Morphology of Brain Signals Using Alpha-Stable Convolutional Sparse Coding
Jun 14, 2017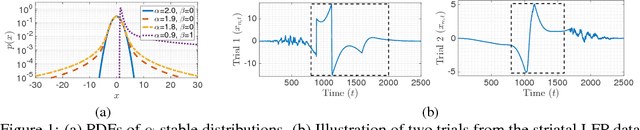
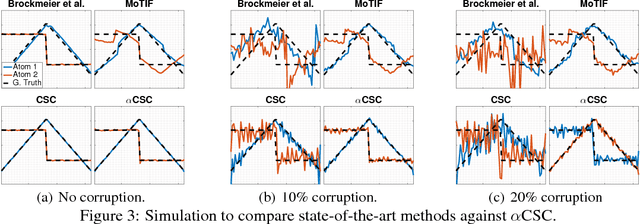
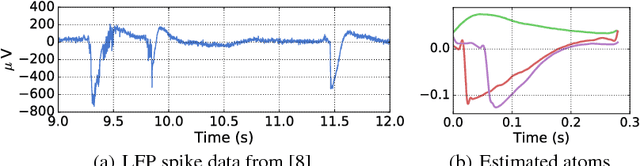
Neural time-series data contain a wide variety of prototypical signal waveforms (atoms) that are of significant importance in clinical and cognitive research. One of the goals for analyzing such data is hence to extract such 'shift-invariant' atoms. Even though some success has been reported with existing algorithms, they are limited in applicability due to their heuristic nature. Moreover, they are often vulnerable to artifacts and impulsive noise, which are typically present in raw neural recordings. In this study, we address these issues and propose a novel probabilistic convolutional sparse coding (CSC) model for learning shift-invariant atoms from raw neural signals containing potentially severe artifacts. In the core of our model, which we call $\alpha$CSC, lies a family of heavy-tailed distributions called $\alpha$-stable distributions. We develop a novel, computationally efficient Monte Carlo expectation-maximization algorithm for inference. The maximization step boils down to a weighted CSC problem, for which we develop a computationally efficient optimization algorithm. Our results show that the proposed algorithm achieves state-of-the-art convergence speeds. Besides, $\alpha$CSC is significantly more robust to artifacts when compared to three competing algorithms: it can extract spike bursts, oscillations, and even reveal more subtle phenomena such as cross-frequency coupling when applied to noisy neural time series.
Machine learning for classification and quantification of monoclonal antibody preparations for cancer therapy
May 31, 2017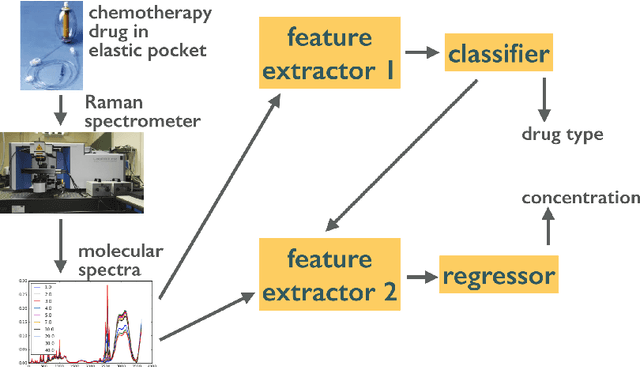

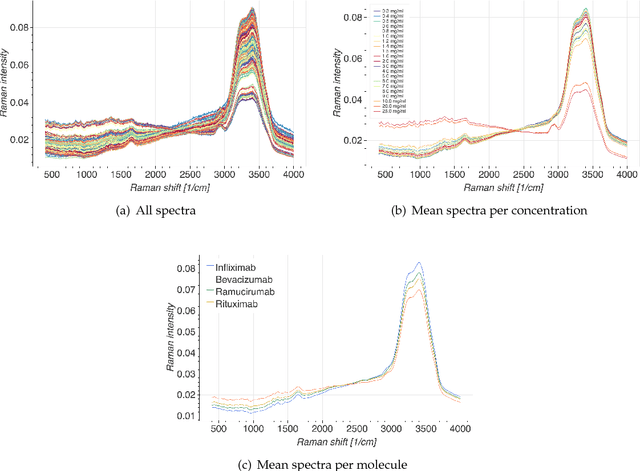
Monoclonal antibodies constitute one of the most important strategies to treat patients suffering from cancers such as hematological malignancies and solid tumors. In order to guarantee the quality of those preparations prepared at hospital, quality control has to be developed. The aim of this study was to explore a noninvasive, nondestructive, and rapid analytical method to ensure the quality of the final preparation without causing any delay in the process. We analyzed four mAbs (Inlfiximab, Bevacizumab, Ramucirumab and Rituximab) diluted at therapeutic concentration in chloride sodium 0.9% using Raman spectroscopy. To reduce the prediction errors obtained with traditional chemometric data analysis, we explored a data-driven approach using statistical machine learning methods where preprocessing and predictive models are jointly optimized. We prepared a data analytics workflow and submitted the problem to a collaborative data challenge platform called Rapid Analytics and Model Prototyping (RAMP). This allowed to use solutions from about 300 data scientists during five days of collaborative work. The prediction of the four mAbs samples was considerably improved with a misclassification rate and the mean error rate of 0.8% and 4%, respectively.
From safe screening rules to working sets for faster Lasso-type solvers
May 01, 2017
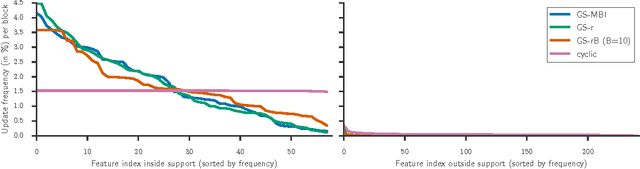
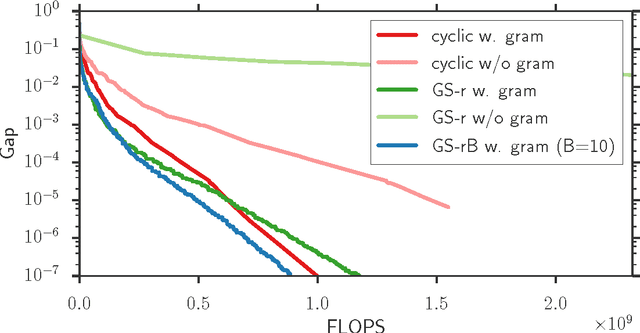
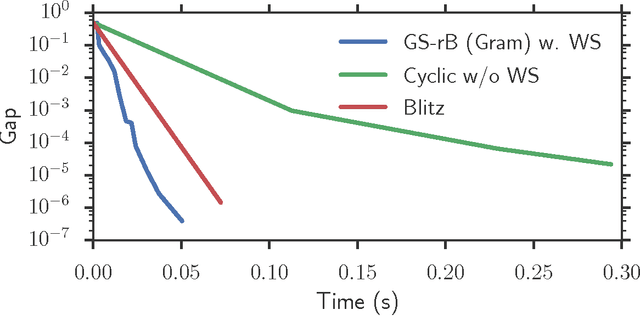
Convex sparsity-promoting regularizations are ubiquitous in modern statistical learning. By construction, they yield solutions with few non-zero coefficients, which correspond to saturated constraints in the dual optimization formulation. Working set (WS) strategies are generic optimization techniques that consist in solving simpler problems that only consider a subset of constraints, whose indices form the WS. Working set methods therefore involve two nested iterations: the outer loop corresponds to the definition of the WS and the inner loop calls a solver for the subproblems. For the Lasso estimator a WS is a set of features, while for a Group Lasso it refers to a set of groups. In practice, WS are generally small in this context so the associated feature Gram matrix can fit in memory. Here we show that the Gauss-Southwell rule (a greedy strategy for block coordinate descent techniques) leads to fast solvers in this case. Combined with a working set strategy based on an aggressive use of so-called Gap Safe screening rules, we propose a solver achieving state-of-the-art performance on sparse learning problems. Results are presented on Lasso and multi-task Lasso estimators.
The iterative reweighted Mixed-Norm Estimate for spatio-temporal MEG/EEG source reconstruction
Jul 28, 2016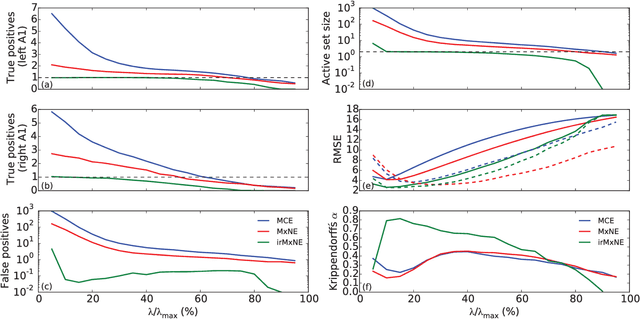
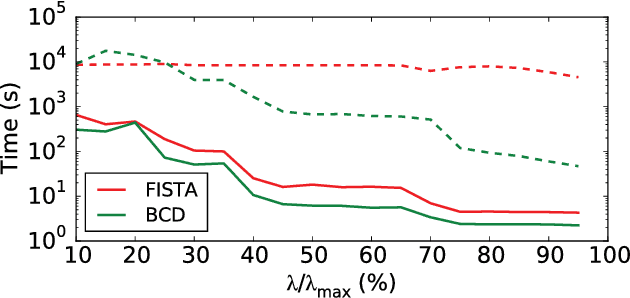
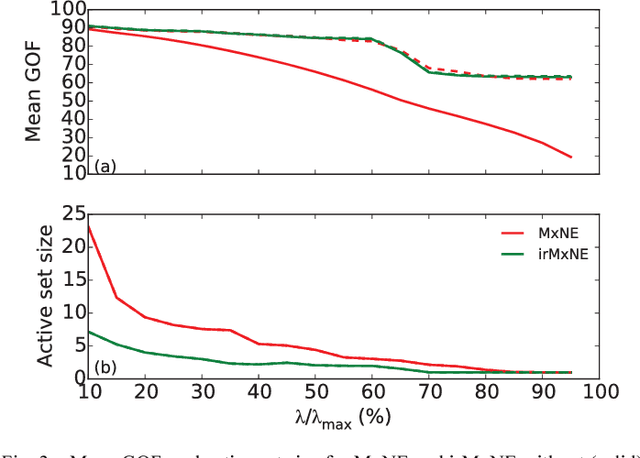
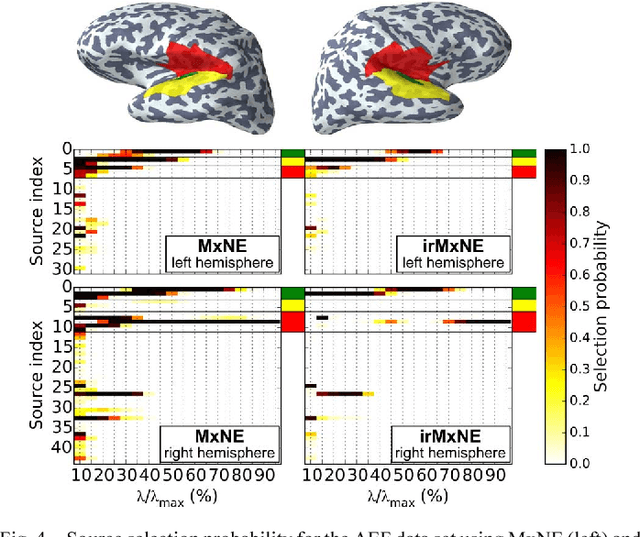
Source imaging based on magnetoencephalography (MEG) and electroencephalography (EEG) allows for the non-invasive analysis of brain activity with high temporal and good spatial resolution. As the bioelectromagnetic inverse problem is ill-posed, constraints are required. For the analysis of evoked brain activity, spatial sparsity of the neuronal activation is a common assumption. It is often taken into account using convex constraints based on the l1-norm. The resulting source estimates are however biased in amplitude and often suboptimal in terms of source selection due to high correlations in the forward model. In this work, we demonstrate that an inverse solver based on a block-separable penalty with a Frobenius norm per block and a l0.5-quasinorm over blocks addresses both of these issues. For solving the resulting non-convex optimization problem, we propose the iterative reweighted Mixed Norm Estimate (irMxNE), an optimization scheme based on iterative reweighted convex surrogate optimization problems, which are solved efficiently using a block coordinate descent scheme and an active set strategy. We compare the proposed sparse imaging method to the dSPM and the RAP-MUSIC approach based on two MEG data sets. We provide empirical evidence based on simulations and analysis of MEG data that the proposed method improves on the standard Mixed Norm Estimate (MxNE) in terms of amplitude bias, support recovery, and stability.
Anomaly Detection and Localisation using Mixed Graphical Models
Jul 20, 2016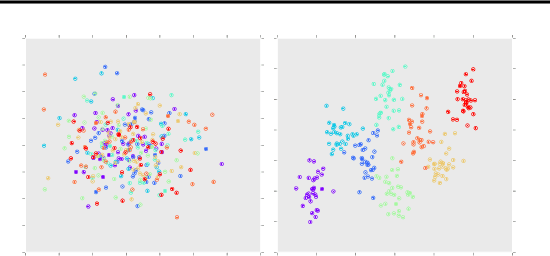
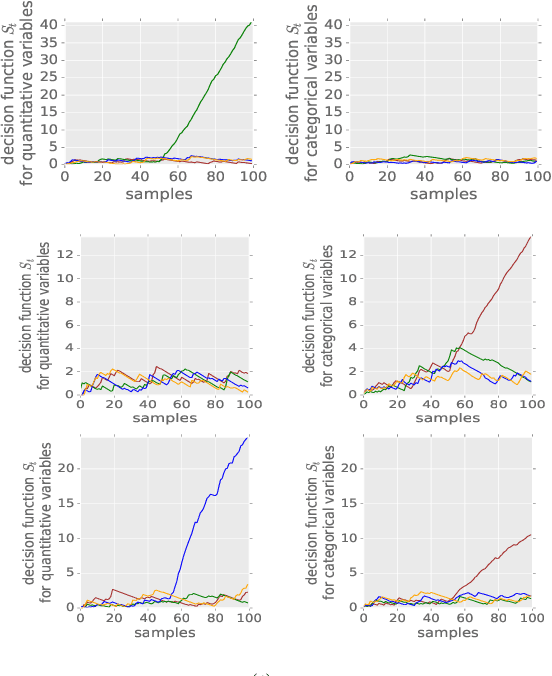
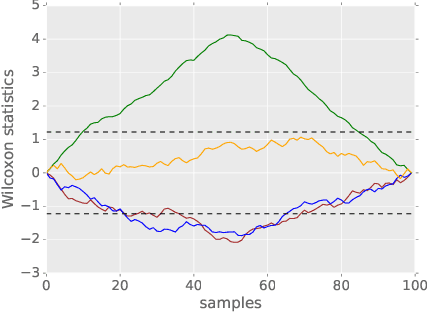
We propose a method that performs anomaly detection and localisation within heterogeneous data using a pairwise undirected mixed graphical model. The data are a mixture of categorical and quantitative variables, and the model is learned over a dataset that is supposed not to contain any anomaly. We then use the model over temporal data, potentially a data stream, using a version of the two-sided CUSUM algorithm. The proposed decision statistic is based on a conditional likelihood ratio computed for each variable given the others. Our results show that this function allows to detect anomalies variable by variable, and thus to localise the variables involved in the anomalies more precisely than univariate methods based on simple marginals.
Efficient Smoothed Concomitant Lasso Estimation for High Dimensional Regression
Jun 08, 2016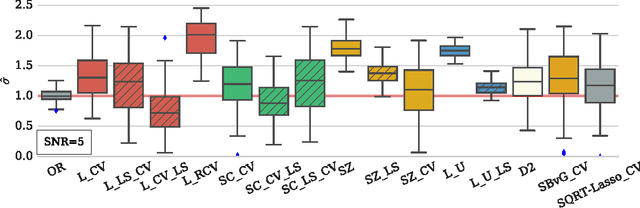
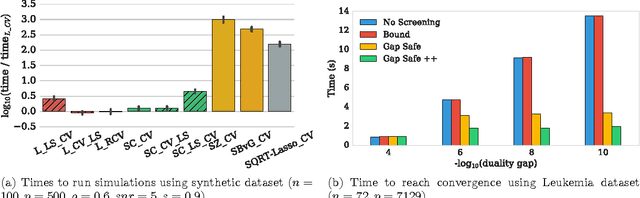
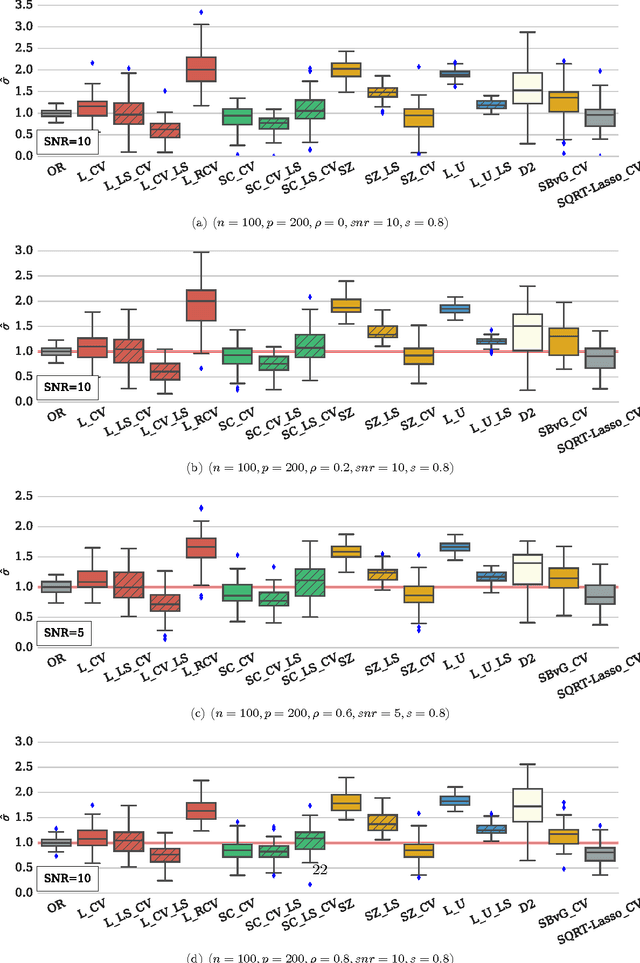
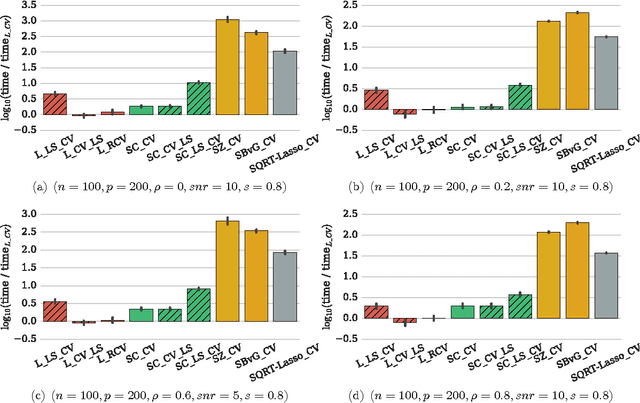
In high dimensional settings, sparse structures are crucial for efficiency, both in term of memory, computation and performance. It is customary to consider $\ell_1$ penalty to enforce sparsity in such scenarios. Sparsity enforcing methods, the Lasso being a canonical example, are popular candidates to address high dimension. For efficiency, they rely on tuning a parameter trading data fitting versus sparsity. For the Lasso theory to hold this tuning parameter should be proportional to the noise level, yet the latter is often unknown in practice. A possible remedy is to jointly optimize over the regression parameter as well as over the noise level. This has been considered under several names in the literature: Scaled-Lasso, Square-root Lasso, Concomitant Lasso estimation for instance, and could be of interest for confidence sets or uncertainty quantification. In this work, after illustrating numerical difficulties for the Smoothed Concomitant Lasso formulation, we propose a modification we coined Smoothed Concomitant Lasso, aimed at increasing numerical stability. We propose an efficient and accurate solver leading to a computational cost no more expansive than the one for the Lasso. We leverage on standard ingredients behind the success of fast Lasso solvers: a coordinate descent algorithm, combined with safe screening rules to achieve speed efficiency, by eliminating early irrelevant features.
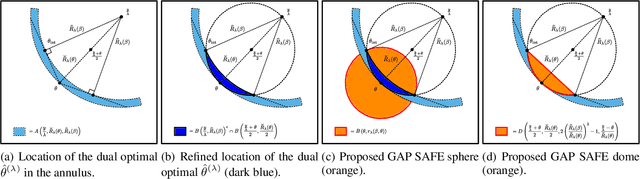
GAP Safe Screening Rules for Sparse-Group-Lasso
Feb 19, 2016


In high dimensional settings, sparse structures are crucial for efficiency, either in term of memory, computation or performance. In some contexts, it is natural to handle more refined structures than pure sparsity, such as for instance group sparsity. Sparse-Group Lasso has recently been introduced in the context of linear regression to enforce sparsity both at the feature level and at the group level. We adapt to the case of Sparse-Group Lasso recent safe screening rules that discard early in the solver irrelevant features/groups. Such rules have led to important speed-ups for a wide range of iterative methods. Thanks to dual gap computations, we provide new safe screening rules for Sparse-Group Lasso and show significant gains in term of computing time for a coordinate descent implementation.
Mind the duality gap: safer rules for the Lasso
Dec 03, 2015
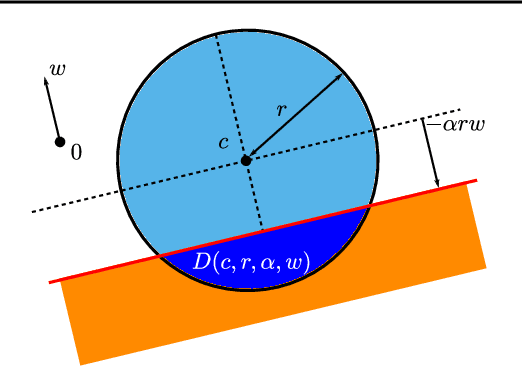
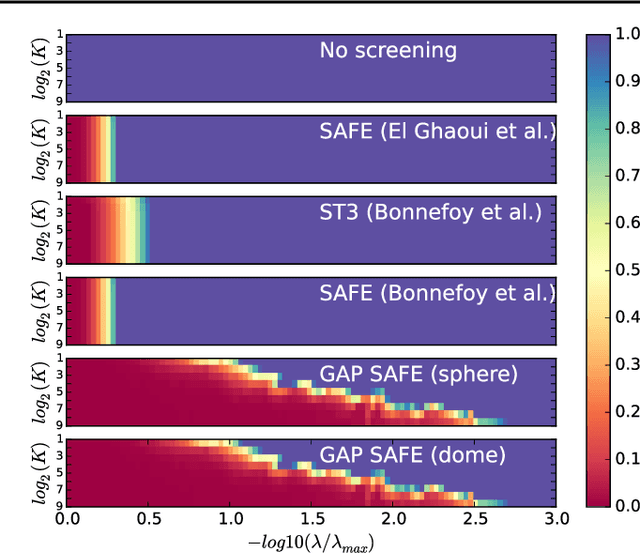
Screening rules allow to early discard irrelevant variables from the optimization in Lasso problems, or its derivatives, making solvers faster. In this paper, we propose new versions of the so-called $\textit{safe rules}$ for the Lasso. Based on duality gap considerations, our new rules create safe test regions whose diameters converge to zero, provided that one relies on a converging solver. This property helps screening out more variables, for a wider range of regularization parameter values. In addition to faster convergence, we prove that we correctly identify the active sets (supports) of the solutions in finite time. While our proposed strategy can cope with any solver, its performance is demonstrated using a coordinate descent algorithm particularly adapted to machine learning use cases. Significant computing time reductions are obtained with respect to previous safe rules.