 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pham's algorithm for joint diagonalization
Nov 28, 2018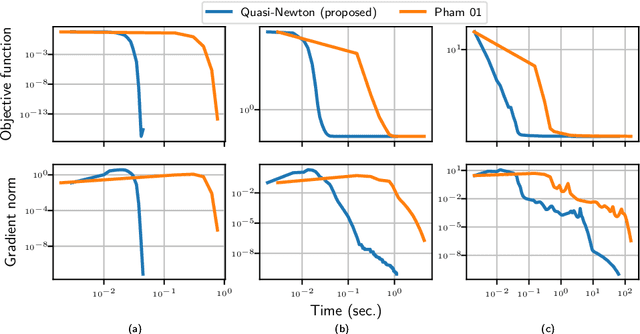
The approximate joint diagonalization of a set of matrices consists in finding a basis in which these matrices are as diagonal as possible. This problem naturally appears in several statistical learning tasks such as blind signal separation. We consider the diagonalization criterion studied in a seminal paper by Pham (2001), and propose a new quasi-Newton method for its optimization. Through numerical experiments on simulated and real datasets, we show that the proposed method outper-forms Pham's algorithm. An open source Python package is released.
Accelerating likelihood optimization for ICA on real signals
Jun 25, 2018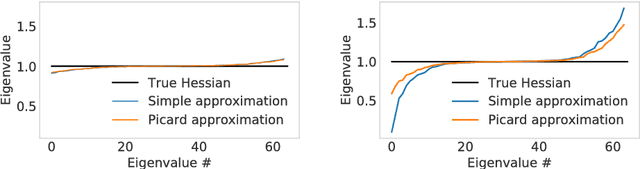
We study optimization methods for solving the maximum likelihood formulation of independent component analysis (ICA). We consider both the the problem constrained to white signals and the unconstrained problem. The Hessian of the objective function is costly to compute, which renders Newton's method impractical for large data sets. Many algorithms proposed in the literature can be rewritten as quasi-Newton methods, for which the Hessian approximation is cheap to compute. These algorithms are very fast on simulated data where the linear mixture assumption really holds. However, on real signals, we observe that their rate of convergence can be severely impaired. In this paper, we investigate the origins of this behavior, and show that the recently proposed Preconditioned ICA for Real Data (Picard) algorithm overcomes this issue on both constrained and unconstrained problems.
EM algorithms for ICA
May 25, 2018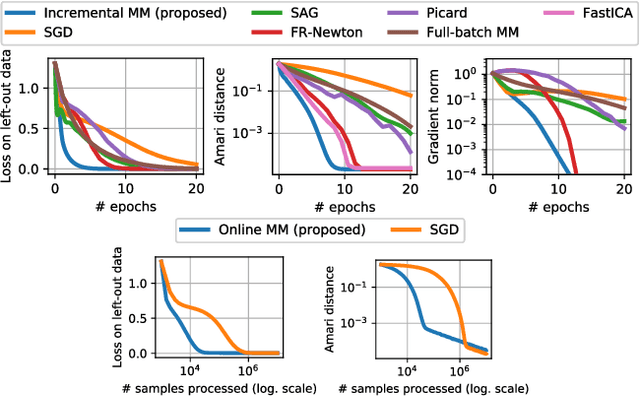
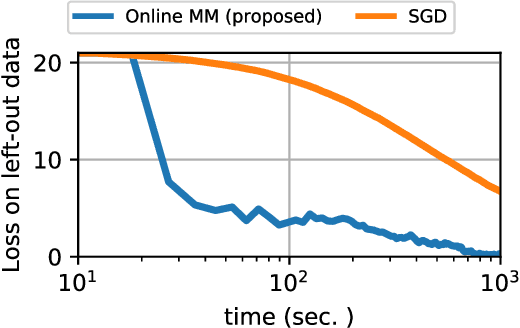
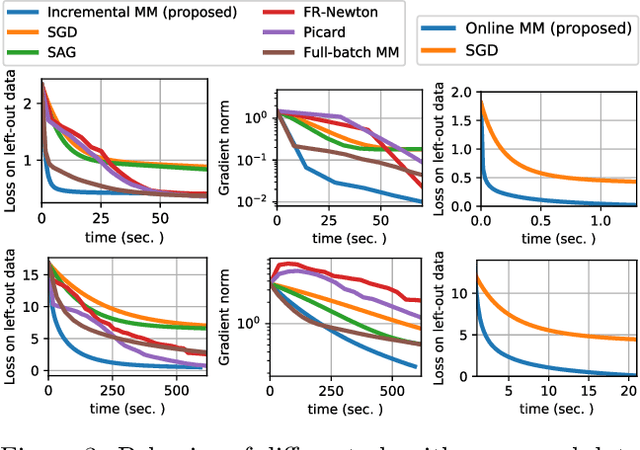
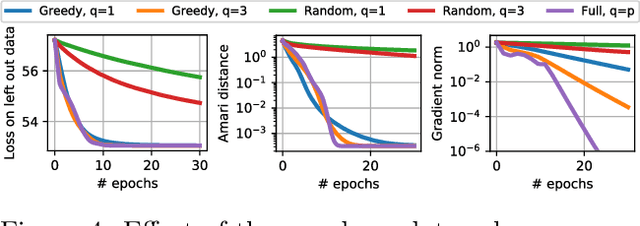
Independent component analysis (ICA) is a widely spread data exploration technique, where observed signals are assumed to be linear mixtures of independent components. From a machine learning point of view, it amounts to a matrix factorization problem under statistical independence constraints. Infomax is one of the first and most used algorithms for inference of the latent parameters. It maximizes a log-likelihood function which is non-convex and decomposes as a sum over signal samples. We introduce a new majorization-minimization framework for the optimization of the loss function. We show that this approach is equivalent to an Expectation-Maximization (EM) algorithm using Gaussian scale mixtures. Inspired by the literature around EM algorithms, we derive an online algorithm for the streaming setting, and an incremental algorithm for the finite-sum setting. These algorithms do not rely on any critical hyper-parameter like a step size, nor do they require a line-search technique. The finite-sum algorithm also enjoys the precious guarantee of decreasing the loss function at each iteration. Experiments show that they outperform the state-of-the-art on large scale problems, where one iteration of a full-batch algorithm is a computational burden.
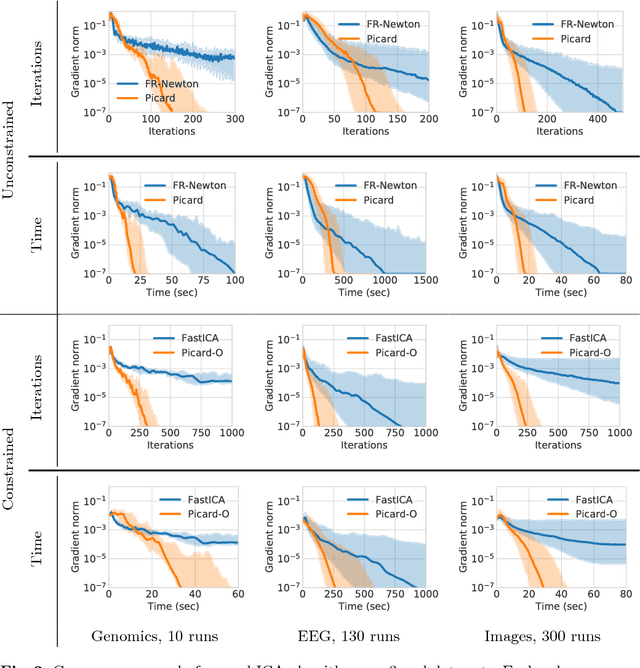
Faster ICA under orthogonal constraint
Nov 29, 2017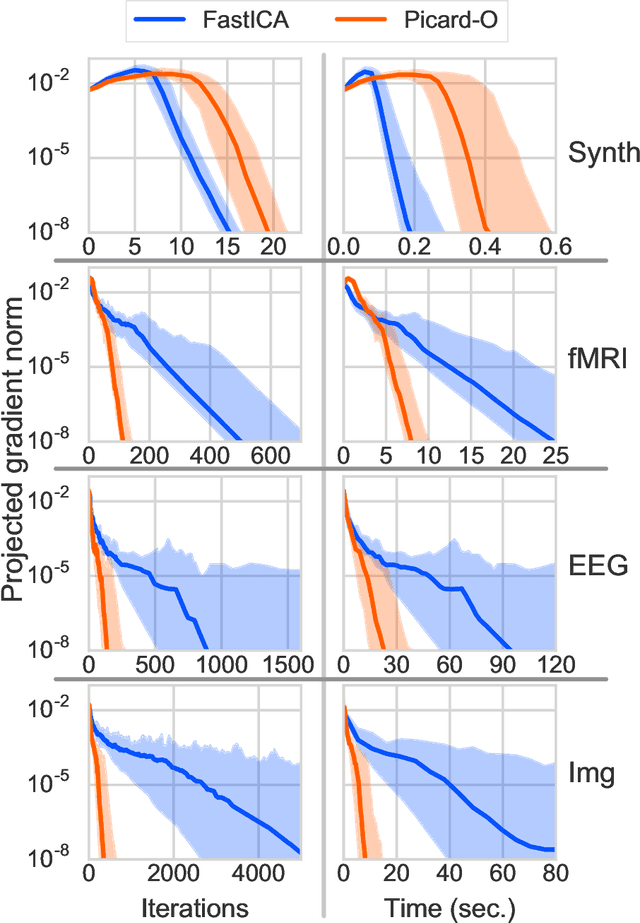
Independent Component Analysis (ICA) is a technique for unsupervised exploration of multi-channel data widely used in observational sciences. In its classical form, ICA relies on modeling the data as a linear mixture of non-Gaussian independent sources. The problem can be seen as a likelihood maximization problem. We introduce Picard-O, a preconditioned L-BFGS strategy over the set of orthogonal matrices, which can quickly separate both super- and sub-Gaussian signals. It returns the same set of sources as the widely used FastICA algorithm. Through numerical experiments, we show that our method is faster and more robust than FastICA on real data.
Faster independent component analysis by preconditioning with Hessian approximations
Sep 08, 2017
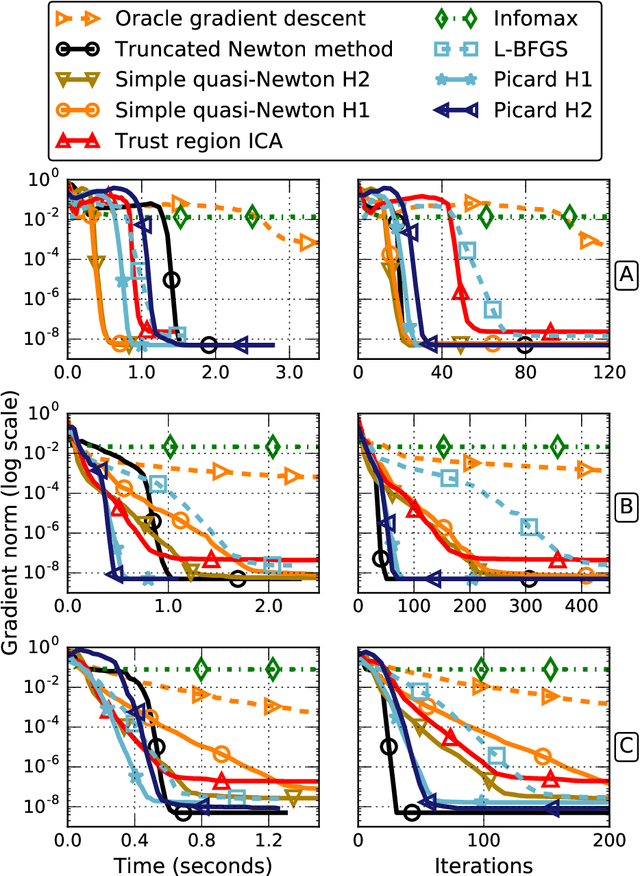
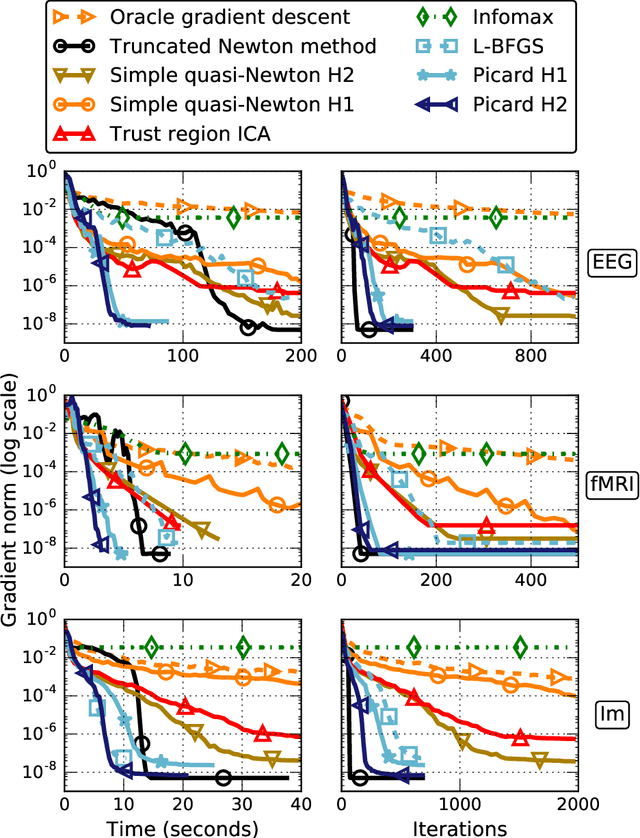
Independent Component Analysis (ICA) is a technique for unsupervised exploration of multi-channel data that is widely used in observational sciences. In its classic form, ICA relies on modeling the data as linear mixtures of non-Gaussian independent sources. The maximization of the corresponding likelihood is a challenging problem if it has to be completed quickly and accurately on large sets of real data. We introduce the Preconditioned ICA for Real Data (Picard) algorithm, which is a relative L-BFGS algorithm preconditioned with sparse Hessian approximations. Extensive numerical comparisons to several algorithms of the same class demonstrate the superior performance of the proposed technique, especially on real data, for which the ICA model does not necessarily hold.