 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based analysis of brain activity reveals the hierarchy of language in 305 subjects
Oct 12, 2021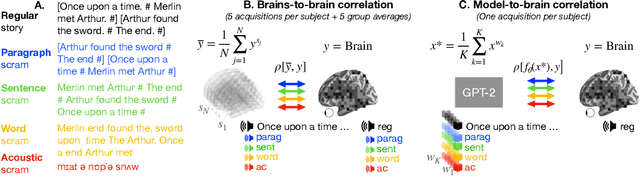
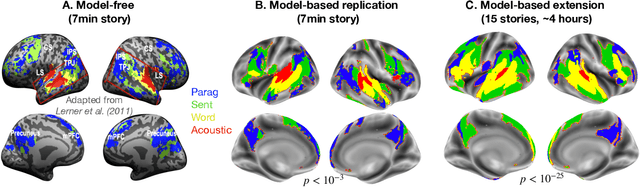
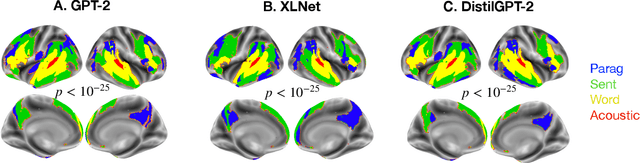
A popular approach to decompose the neural bases of language consists in correlating, across individuals, the brain responses to different stimuli (e.g. regular speech versus scrambled words, sentences, or paragraphs). Although successful, this `model-free' approach necessitates the acquisition of a large and costly set of neuroimaging data. Here, we show that a model-based approach can reach equivalent results within subjects exposed to natural stimuli. We capitalize on the recently-discovered similarities between deep language models and the human brain to compute the mapping between i) the brain responses to regular speech and ii) the activations of deep language models elicited by modified stimuli (e.g. scrambled words, sentences, or paragraphs). Our model-based approach successfully replicates the seminal study of Lerner et al. (2011), which revealed the hierarchy of language areas by comparing the functional-magnetic resonance imaging (fMRI) of seven subjects listening to 7min of both regular and scrambled narratives. We further extend and precise these results to the brain signals of 305 individuals listening to 4.1 hours of narrated stories. Overall, this study paves the way for efficient and flexible analyses of the brain bases of language.
CADDA: Class-wise Automatic Differentiable Data Augmentation for EEG Signals
Jun 25, 2021
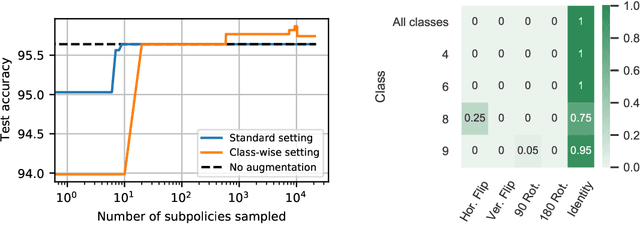
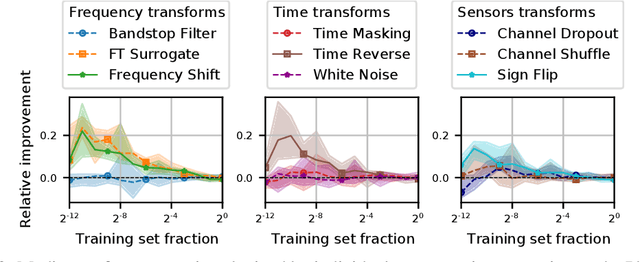
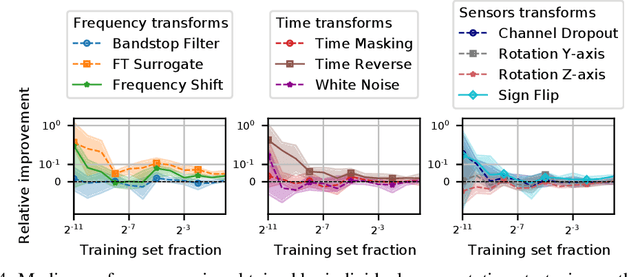
Data augmentation is a key element of deep learning pipelines, as it informs the network during training about transformations of the input data that keep the label unchanged. Manually finding adequate augmentation methods and parameters for a given pipeline is however rapidly cumbersome. In particular, while intuition can guide this decision for images, the design and choice of augmentation policies remains unclear for more complex types of data, such as neuroscience signals. Moreover, label independent strategies might not be suitable for such structured data and class-dependent augmentations might be necessary. This idea has been surprisingly unexplored in the literature, while it is quite intuitive: changing the color of a car image does not change the object class to be predicted, but doing the same to the picture of an orange does. This paper aims to increase the generalization power added through class-wise data augmentation. Yet, as seeking transformations depending on the class largely increases the complexity of the task, using gradient-free optimization techniques as done by most existing automatic approaches becomes intractable for real-world datasets. For this reason we propose to use differentiable data augmentation amenable to gradient-based learning. EEG signals are a perfect example of data for which good augmentation policies are mostly unknown. In this work, we demonstrate the relevance of our approach on the clinically relevant sleep staging classification task, for which we also propose differentiable transformations.
Robust learning from corrupted EEG with dynamic spatial filtering
May 27, 2021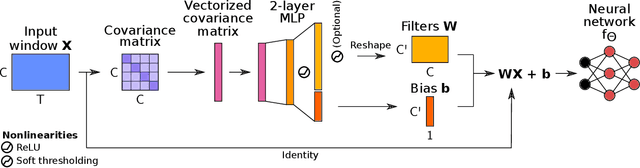
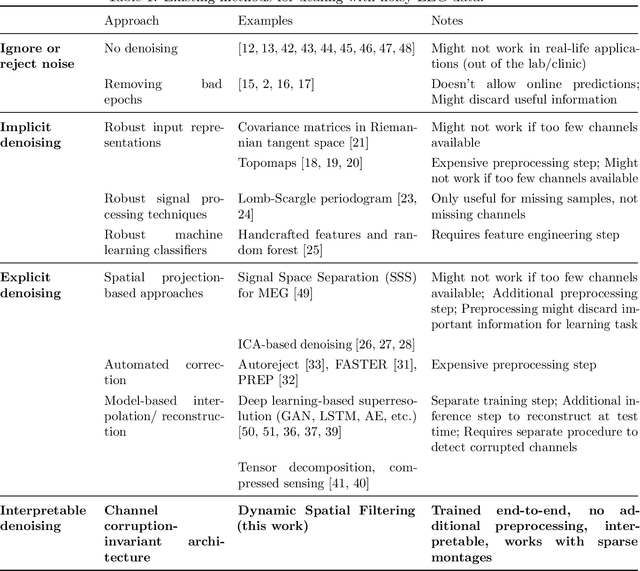
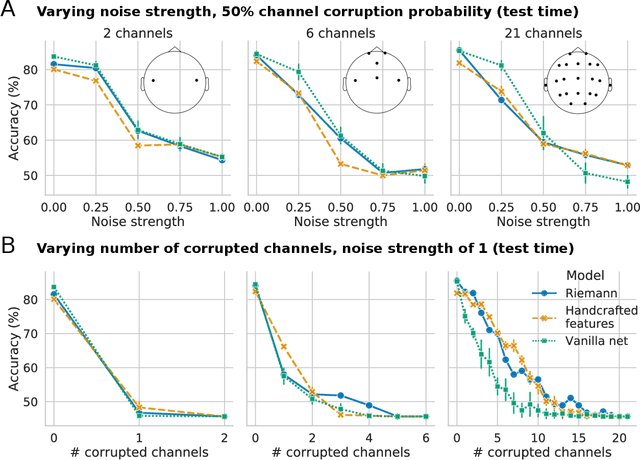
Building machine learning models using EEG recorded outside of the laboratory setting requires methods robust to noisy data and randomly missing channels. This need is particularly great when working with sparse EEG montages (1-6 channels), often encountered in consumer-grade or mobile EEG devices. Neither classical machine learning models nor deep neural networks trained end-to-end on EEG are typically designed or tested for robustness to corruption, and especially to randomly missing channels. While some studies have proposed strategies for using data with missing channels, these approaches are not practical when sparse montages are used and computing power is limited (e.g., wearables, cell phones). To tackle this problem, we propose dynamic spatial filtering (DSF), a multi-head attention module that can be plugged in before the first layer of a neural network to handle missing EEG channels by learning to focus on good channels and to ignore bad ones. We tested DSF on public EEG data encompassing ~4,000 recordings with simulated channel corruption and on a private dataset of ~100 at-home recordings of mobile EEG with natural corruption. Our proposed approach achieves the same performance as baseline models when no noise is applied, but outperforms baselines by as much as 29.4% accuracy when significant channel corruption is present. Moreover, DSF outputs are interpretable, making it possible to monitor channel importance in real-time. This approach has the potential to enable the analysis of EEG in challenging settings where channel corruption hampers the reading of brain signals.
Implicit differentiation for fast hyperparameter selection in non-smooth convex learning
May 17, 2021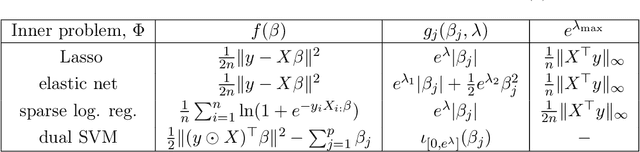
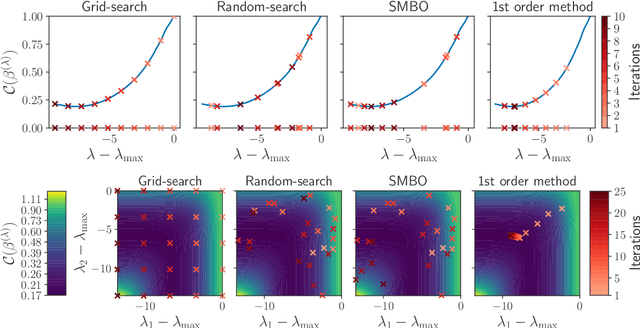
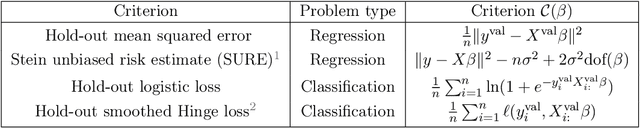
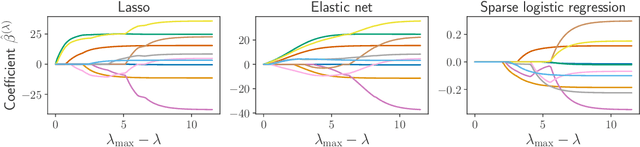
Finding the optimal hyperparameters of a model can be cast as a bilevel optimization problem, typically solved using zero-order techniques. In this work we study first-order methods when the inner optimization problem is convex but non-smooth. We show that the forward-mode differentiation of proximal gradient descent and proximal coordinate descent yield sequences of Jacobians converging toward the exact Jacobian. Using implicit differentiation, we show it is possible to leverage the non-smoothness of the inner problem to speed up the computation. Finally, we provide a bound on the error made on the hypergradient when the inner optimization problem is solved approximately. Results on regression and classification problems reveal computational benefits for hyperparameter optimization, especially when multiple hyperparameters are required.
Deep Recurrent Encoder: A scalable end-to-end network to model brain signals
Mar 29, 2021
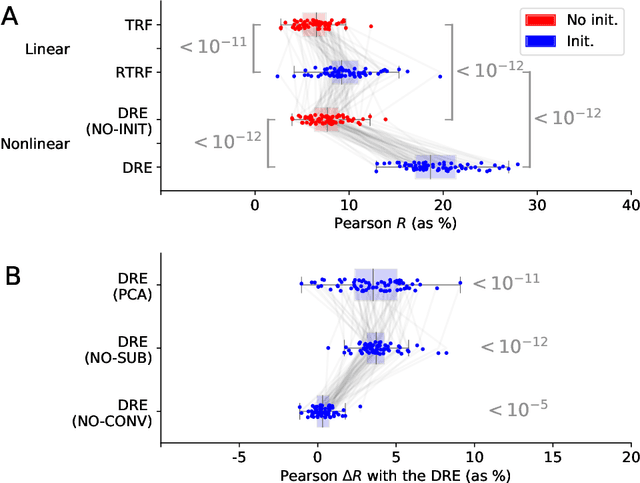
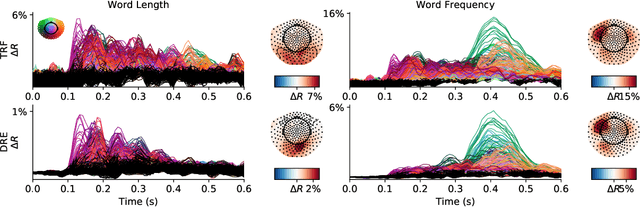
Understanding how the brain responds to sensory inputs is challenging: brain recordings are partial, noisy, and high dimensional; they vary across sessions and subjects and they capture highly nonlinear dynamics. These challenges have led the community to develop a variety of preprocessing and analytical (almost exclusively linear) methods, each designed to tackle one of these issues. Instead, we propose to address these challenges through a specific end-to-end deep learning architecture, trained to predict the brain responses of multiple subjects at once. We successfully test this approach on a large cohort of magnetoencephalography (MEG) recordings acquired during a one-hour reading task. Our Deep Recurrent Encoding (DRE) architecture reliably predicts MEG responses to words with a three-fold improvement over classic linear methods. To overcome the notorious issue of interpretability of deep learning, we describe a simple variable importance analysis. When applied to DRE, this method recovers the expected evoked responses to word length and word frequency. The quantitative improvement of the present deep learning approach paves the way to better understand the nonlinear dynamics of brain activity from large datasets.
Decomposing lexical and compositional syntax and semantics with deep language models
Mar 02, 2021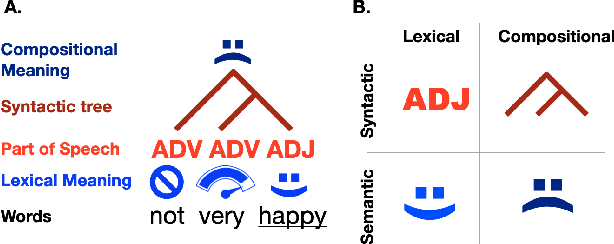
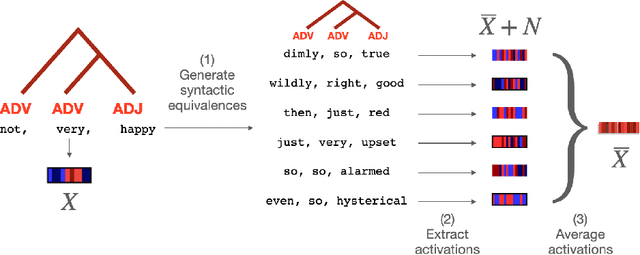
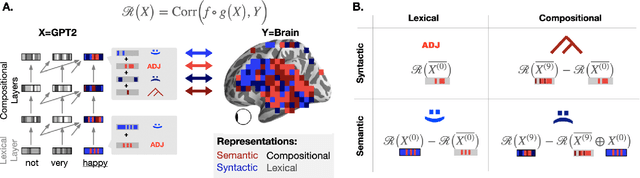
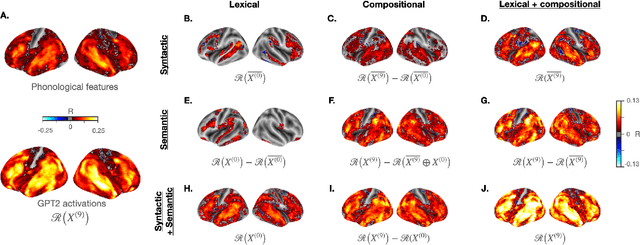
The activations of language transformers like GPT2 have been shown to linearly map onto brain activity during speech comprehension. However, the nature of these activations remains largely unknown and presumably conflate distinct linguistic classes. Here, we propose a taxonomy to factorize the high-dimensional activations of language models into four combinatorial classes: lexical, compositional, syntactic, and semantic representations. We then introduce a statistical method to decompose, through the lens of GPT2's activations, the brain activity of 345 subjects recorded with functional magnetic resonance imaging (fMRI) during the listening of ~4.6 hours of narrated text. The results highlight two findings. First, compositional representations recruit a more widespread cortical network than lexical ones, and encompass the bilateral temporal, parietal and prefrontal cortices. Second, contrary to previous claims, syntax and semantics are not associated with separated modules, but, instead, appear to share a common and distributed neural substrate. Overall, this study introduces a general framework to isolate the distributed representations of linguistic constructs generated in naturalistic settings.
Adaptive Multi-View ICA: Estimation of noise levels for optimal inference
Feb 22, 2021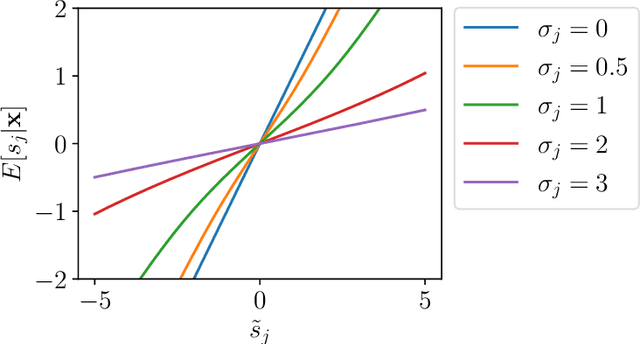
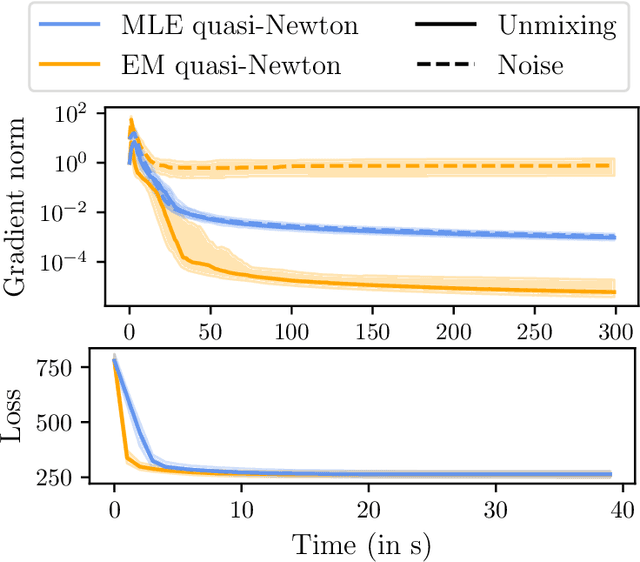
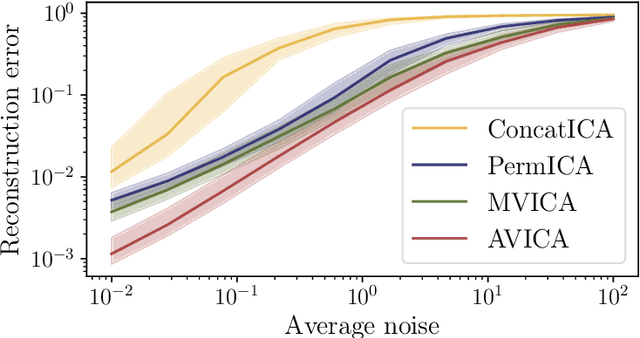
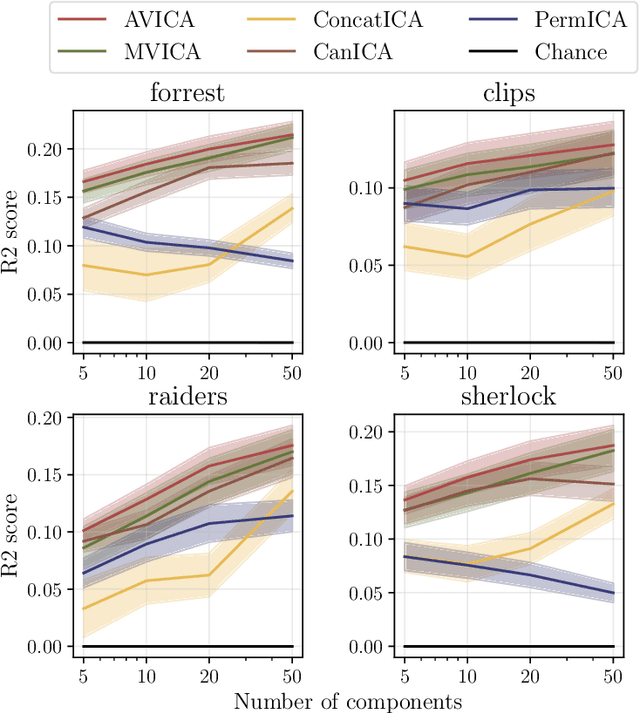
We consider a multi-view learning problem known as group independent component analysis (group ICA), where the goal is to recover shared independent sources from many views. The statistical modeling of this problem requires to take noise into account. When the model includes additive noise on the observations, the likelihood is intractable. By contrast, we propose Adaptive multiView ICA (AVICA), a noisy ICA model where each view is a linear mixture of shared independent sources with additive noise on the sources. In this setting, the likelihood has a tractable expression, which enables either direct optimization of the log-likelihood using a quasi-Newton method, or generalized EM. Importantly, we consider that the noise levels are also parameters that are learned from the data. This enables sources estimation with a closed-form Minimum Mean Squared Error (MMSE) estimator which weights each view according to its relative noise level. On synthetic data, AVICA yields better sources estimates than other group ICA methods thanks to its explicit MMSE estimator. On real magnetoencephalograpy (MEG) data, we provide evidence that the decomposition is less sensitive to sampling noise and that the noise variance estimates are biologically plausible. Lastly, on functional magnetic resonance imaging (fMRI) data, AVICA exhibits best performance in transferring information across views.
Leveraging Global Parameters for Flow-based Neural Posterior Estimation
Feb 12, 2021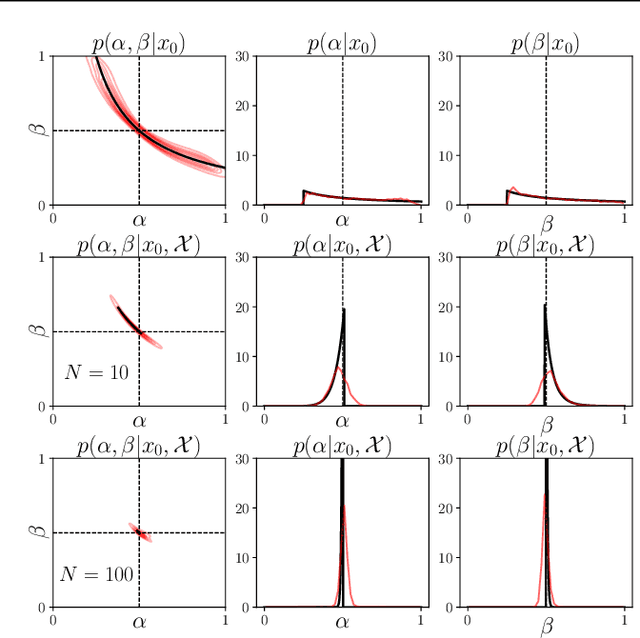
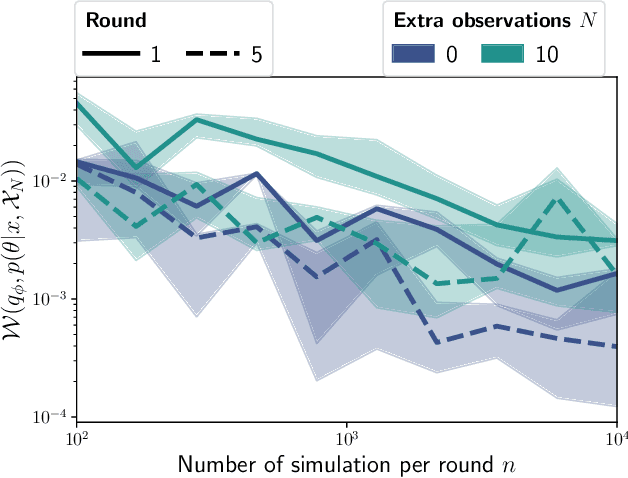
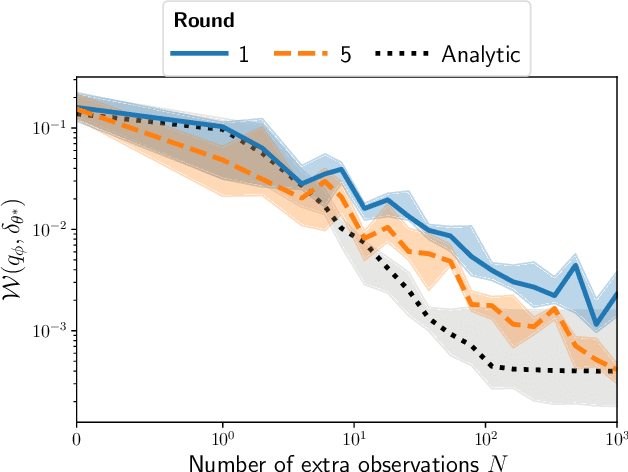
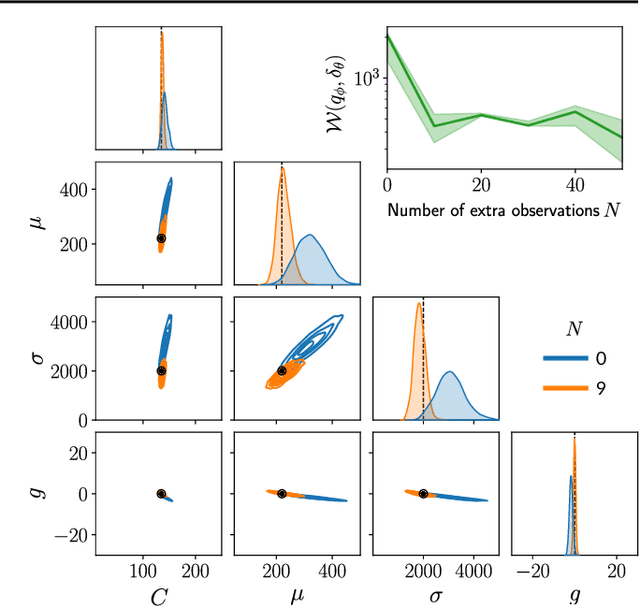
Inferring the parameters of a stochastic model based on experimental observations is central to the scientific method. A particularly challenging setting is when the model is strongly indeterminate, i.e., when distinct sets of parameters yield identical observations. This arises in many practical situations, such as when inferring the distance and power of a radio source (is the source close and weak or far and strong?) or when estimating the amplifier gain and underlying brain activity of an electrophysiological experiment. In this work, we present a method for cracking such indeterminacy by exploiting additional information conveyed by an auxiliary set of observations sharing global parameters. Our method extends recent developments in simulation-based inference(SBI) based on normalizing flows to Bayesian hierarchical models. We validate quantitatively our proposal on a motivating example amenable to analytical solutions, and then apply it to invert a well known non-linear model from computational neuroscience.
Learning summary features of time series for likelihood free inference
Dec 04, 2020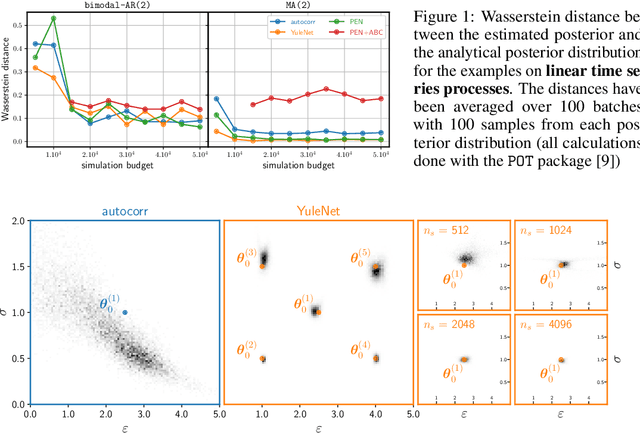
There has been an increasing interest from the scientific community in using likelihood-free inference (LFI) to determine which parameters of a given simulator model could best describe a set of experimental data. Despite exciting recent results and a wide range of possible applications, an important bottleneck of LFI when applied to time series data is the necessity of defining a set of summary features, often hand-tailored based on domain knowledge. In this work, we present a data-driven strategy for automatically learning summary features from univariate time series and apply it to signals generated from autoregressive-moving-average (ARMA) models and the Van der Pol Oscillator. Our results indicate that learning summary features from data can compete and even outperform LFI methods based on hand-crafted values such as autocorrelation coefficients even in the linear case.
Model identification and local linear convergence of coordinate descent
Oct 22, 2020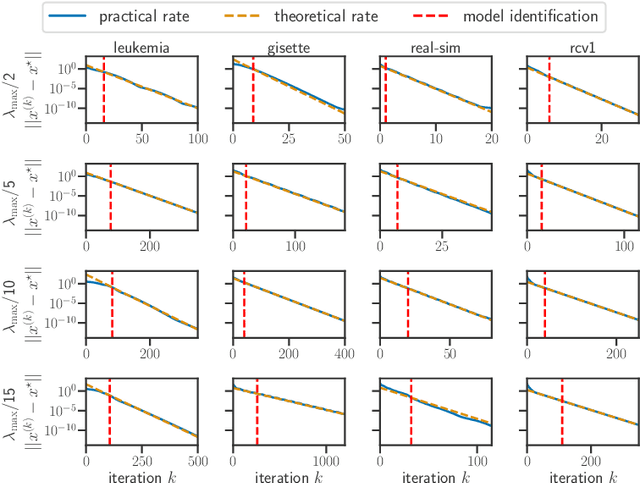
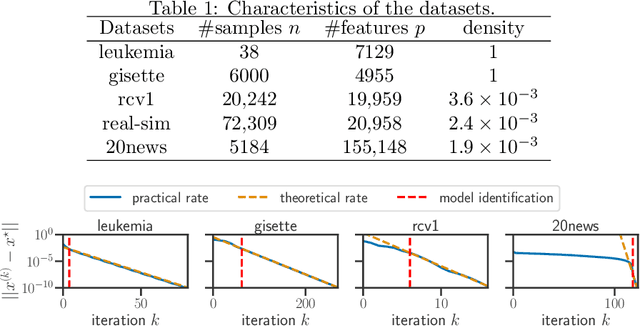
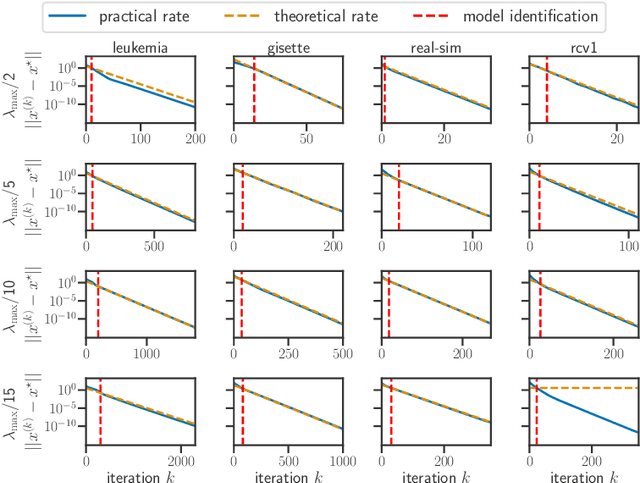
For composite nonsmooth optimization problems, Forward-Backward algorithm achieves model identification (e.g. support identification for the Lasso) after a finite number of iterations, provided the objective function is regular enough. Results concerning coordinate descent are scarcer and model identification has only been shown for specific estimators, the support-vector machine for instance. In this work, we show that cyclic coordinate descent achieves model identification in finite time for a wide class of functions. In addition, we prove explicit local linear convergence rates for coordinate descent. Extensive experiments on various estimators and on real datasets demonstrate that these rates match well empirical results.