 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating Trajectory Prediction with Backdoors
Jan 03, 2024



Autonomous vehicles ought to predict the surrounding agents' trajectories to allow safe maneuvers in uncertain and complex traffic situations. As companies increasingly apply trajectory prediction in the real world, security becomes a relevant concern. In this paper, we focus on backdoors - a security threat acknowledged in other fields but so far overlooked for trajectory prediction. To this end, we describe and investigate four triggers that could affect trajectory prediction. We then show that these triggers (for example, a braking vehicle), when correlated with a desired output (for example, a curve) during training, cause the desired output of a state-of-the-art trajectory prediction model. In other words, the model has good benign performance but is vulnerable to backdoors. This is the case even if the trigger maneuver is performed by a non-casual agent behind the target vehicle. As a side-effect, our analysis reveals interesting limitations within trajectory prediction models. Finally, we evaluate a range of defenses against backdoors. While some, like simple offroad checks, do not enable detection for all triggers, clustering is a promising candidate to support manual inspection to find backdoors.
Social-Transmotion: Promptable Human Trajectory Prediction
Dec 26, 2023



Accurate human trajectory prediction is crucial for applications such as autonomous vehicles, robotics, and surveillance systems. Yet, existing models often fail to fully leverage the non-verbal social cues human subconsciously communicate when navigating the space. To address this, we introduce Social-Transmotion, a generic model that exploits the power of transformers to handle diverse and numerous visual cues, capturing the multi-modal nature of human behavior. We translate the idea of a prompt from Natural Language Processing (NLP) to the task of human trajectory prediction, where a prompt can be a sequence of x-y coordinates on the ground, bounding boxes or body poses. This, in turn, augments trajectory data, leading to enhanced human trajectory prediction. Our model exhibits flexibility and adaptability by capturing spatiotemporal interactions between pedestrians based on the available visual cues, whether they are poses, bounding boxes, or a combination thereof. By the masking technique, we ensure our model's effectiveness even when certain visual cues are unavailable, although performance is further boosted with the presence of comprehensive visual data. We delve into the merits of using 2d versus 3d poses, and a limited set of poses. Additionally, we investigate the spatial and temporal attention map to identify which keypoints and frames of poses are vital for optimizing human trajectory prediction. Our approach is validated on multiple datasets, including JTA, JRDB, Pedestrians and Cyclists in Road Traffic, and ETH-UCY. The code is publicly available: https://github.com/vita-epfl/social-transmotion
Images in Discrete Choice Modeling: Addressing Data Isomorphism in Multi-Modality Inputs
Dec 22, 2023This paper explores the intersection of Discrete Choice Modeling (DCM) and machine learning, focusing on the integration of image data into DCM's utility functions and its impact on model interpretability. We investigate the consequences of embedding high-dimensional image data that shares isomorphic information with traditional tabular inputs within a DCM framework. Our study reveals that neural network (NN) components learn and replicate tabular variable representations from images when co-occurrences exist, thereby compromising the interpretability of DCM parameters. We propose and benchmark two methodologies to address this challenge: architectural design adjustments to segregate redundant information, and isomorphic information mitigation through source information masking and inpainting. Our experiments, conducted on a semi-synthetic dataset, demonstrate that while architectural modifications prove inconclusive, direct mitigation at the data source shows to be a more effective strategy in maintaining the integrity of DCM's interpretable parameters. The paper concludes with insights into the applicability of our findings in real-world settings and discusses the implications for future research in hybrid modeling that combines complex data modalities. Full control of tabular and image data congruence is attained by using the MIT moral machine dataset, and both inputs are merged into a choice model by deploying the Learning Multinomial Logit (L-MNL) framework.
Sim-to-Real Causal Transfer: A Metric Learning Approach to Causally-Aware Interaction Representations
Dec 07, 2023Modeling spatial-temporal interactions among neighboring agents is at the heart of multi-agent problems such as motion forecasting and crowd navigation. Despite notable progress, it remains unclear to which extent modern representations can capture the causal relationships behind agent interactions. In this work, we take an in-depth look at the causal awareness of these representations, from computational formalism to real-world practice. First, we cast doubt on the notion of non-causal robustness studied in the recent CausalAgents benchmark. We show that recent representations are already partially resilient to perturbations of non-causal agents, and yet modeling indirect causal effects involving mediator agents remains challenging. To address this challenge, we introduce a metric learning approach that regularizes latent representations with causal annotations. Our controlled experiments show that this approach not only leads to higher degrees of causal awareness but also yields stronger out-of-distribution robustness. To further operationalize it in practice, we propose a sim-to-real causal transfer method via cross-domain multi-task learning. Experiments on pedestrian datasets show that our method can substantially boost generalization, even in the absence of real-world causal annotations. We hope our work provides a new perspective on the challenges and potential pathways towards causally-aware representations of multi-agent interactions. Our code is available at https://github.com/socialcausality.
Towards more Practical Threat Models in Artificial Intelligence Security
Nov 16, 2023
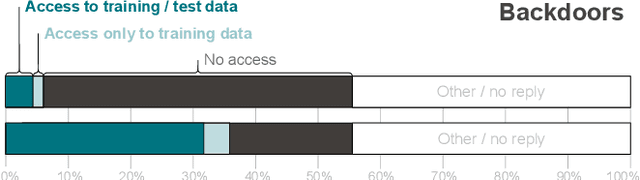


Recent works have identified a gap between research and practice in artificial intelligence security: threats studied in academia do not always reflect the practical use and security risks of AI. For example, while models are often studied in isolation, they form part of larger ML pipelines in practice. Recent works also brought forward that adversarial manipulations introduced by academic attacks are impractical. We take a first step towards describing the full extent of this disparity. To this end, we revisit the threat models of the six most studied attacks in AI security research and match them to AI usage in practice via a survey with \textbf{271} industrial practitioners. On the one hand, we find that all existing threat models are indeed applicable. On the other hand, there are significant mismatches: research is often too generous with the attacker, assuming access to information not frequently available in real-world settings. Our paper is thus a call for action to study more practical threat models in artificial intelligence security.
JRDB-Traj: A Dataset and Benchmark for Trajectory Forecasting in Crowds
Nov 05, 2023
Predicting future trajectories is critical in autonomous navigation, especially in preventing accidents involving humans, where a predictive agent's ability to anticipate in advance is of utmost importance. Trajectory forecasting models, employed in fields such as robotics, autonomous vehicles, and navigation, face challenges in real-world scenarios, often due to the isolation of model components. To address this, we introduce a novel dataset for end-to-end trajectory forecasting, facilitating the evaluation of models in scenarios involving less-than-ideal preceding modules such as tracking. This dataset, an extension of the JRDB dataset, provides comprehensive data, including the locations of all agents, scene images, and point clouds, all from the robot's perspective. The objective is to predict the future positions of agents relative to the robot using raw sensory input data. It bridges the gap between isolated models and practical applications, promoting a deeper understanding of navigation dynamics. Additionally, we introduce a novel metric for assessing trajectory forecasting models in real-world scenarios where ground-truth identities are inaccessible, addressing issues related to undetected or over-detected agents. Researchers are encouraged to use our benchmark for model evaluation and benchmarking.
TIC-TAC: A Framework To Learn And Evaluate Your Covariance
Oct 29, 2023



We study the problem of unsupervised heteroscedastic covariance estimation, where the goal is to learn the multivariate target distribution $\mathcal{N}(y, \Sigma_y | x )$ given an observation $x$. This problem is particularly challenging as $\Sigma_{y}$ varies for different samples (heteroscedastic) and no annotation for the covariance is available (unsupervised). Typically, state-of-the-art methods predict the mean $f_{\theta}(x)$ and covariance $\textrm{Cov}(f_{\theta}(x))$ of the target distribution through two neural networks trained using the negative log-likelihood. This raises two questions: (1) Does the predicted covariance truly capture the randomness of the predicted mean? (2) In the absence of ground-truth annotation, how can we quantify the performance of covariance estimation? We address (1) by deriving TIC: Taylor Induced Covariance, which captures the randomness of the multivariate $f_{\theta}(x)$ by incorporating its gradient and curvature around $x$ through the second order Taylor polynomial. Furthermore, we tackle (2) by introducing TAC: Task Agnostic Correlations, a metric which leverages conditioning of the normal distribution to evaluate the covariance. We verify the effectiveness of TIC through multiple experiments spanning synthetic (univariate, multivariate) and real-world datasets (UCI Regression, LSP, and MPII Human Pose Estimation). Our experiments show that TIC outperforms state-of-the-art in accurately learning the covariance, as quantified through TAC.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
On Pitfalls of Test-Time Adaptation
Jun 06, 2023



Test-Time Adaptation (TTA) has recently emerged as a promising approach for tackling the robustness challenge under distribution shifts. However, the lack of consistent settings and systematic studies in prior literature hinders thorough assessments of existing methods. To address this issue, we present TTAB, a test-time adaptation benchmark that encompasses ten state-of-the-art algorithms, a diverse array of distribution shifts, and two evaluation protocols. Through extensive experiments, our benchmark reveals three common pitfalls in prior efforts. First, selecting appropriate hyper-parameters, especially for model selection, is exceedingly difficult due to online batch dependency. Second, the effectiveness of TTA varies greatly depending on the quality and properties of the model being adapted. Third, even under optimal algorithmic conditions, none of the existing methods are capable of addressing all common types of distribution shifts. Our findings underscore the need for future research in the field to conduct rigorous evaluations on a broader set of models and shifts, and to re-examine the assumptions behind the empirical success of TTA. Our code is available at \url{https://github.com/lins-lab/ttab}.