 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization
Dec 16, 2021
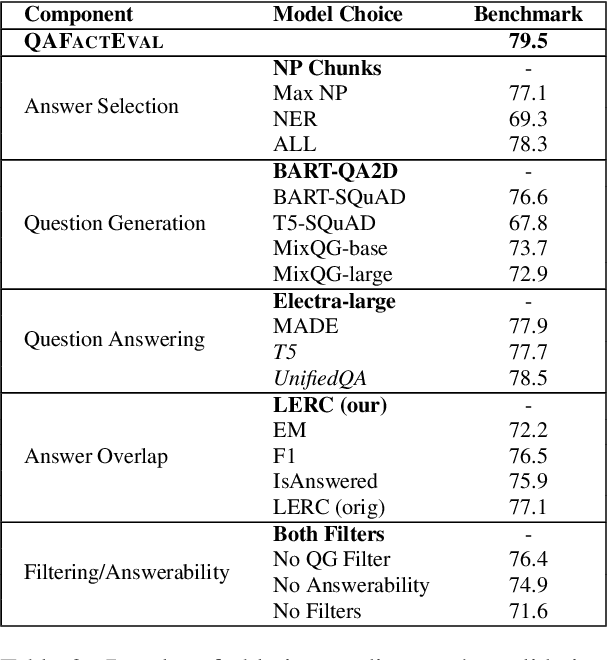
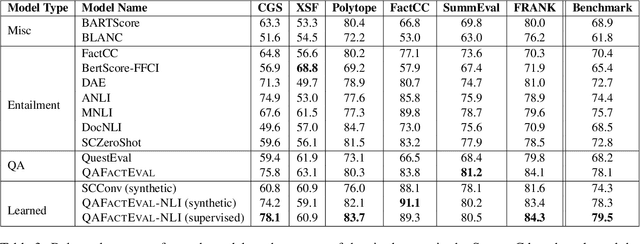

Factual consistency is an essential quality of text summarization models in practical settings. Existing work in evaluating this dimension can be broadly categorized into two lines of research, entailment-based metrics and question answering (QA)-based metrics. However, differing experimental setups presented in recent work lead to contrasting conclusions as to which paradigm performs best. In this work, we conduct an extensive comparison of entailment and QA-based metrics, demonstrating that carefully choosing the components of a QA-based metric is critical to performance. Building on those insights, we propose an optimized metric, which we call QAFactEval, that leads to a 15% average improvement over previous QA-based metrics on the SummaC factual consistency benchmark. Our solution improves upon the best-performing entailment-based metric and achieves state-of-the-art performance on this benchmark. Furthermore, we find that QA-based and entailment-based metrics offer complementary signals and combine the two into a single, learned metric for further performance boost. Through qualitative and quantitative analyses, we point to question generation and answerability classification as two critical components for future work in QA-based metrics.
Exploring Neural Models for Query-Focused Summarization
Dec 15, 2021
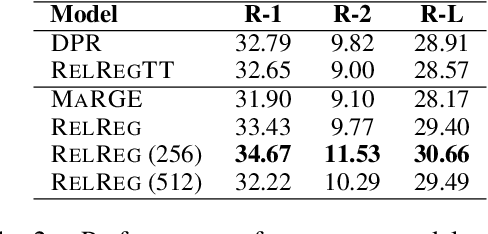
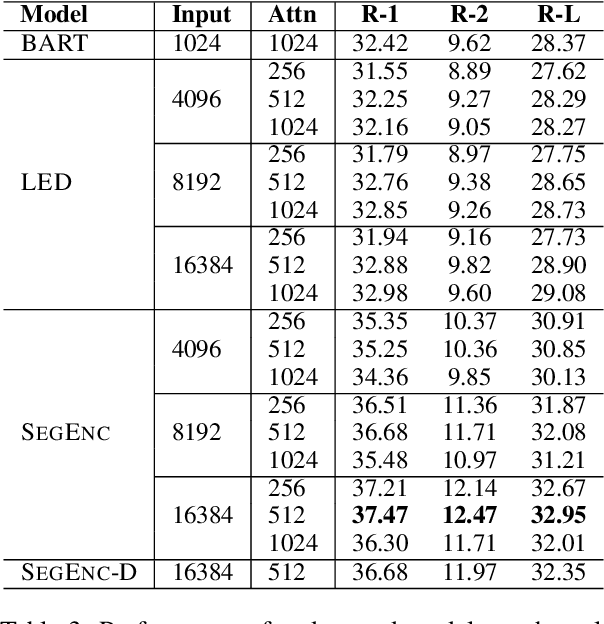
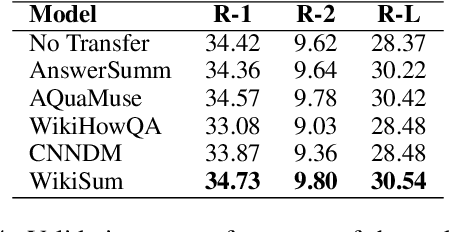
Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. While recently released datasets, such as QMSum or AQuaMuSe, facilitate research efforts in QFS, the field lacks a comprehensive study of the broad space of applicable modeling methods. In this paper we conduct a systematic exploration of neural approaches to QFS, considering two general classes of methods: two-stage extractive-abstractive solutions and end-to-end models. Within those categories, we investigate existing methods and present two model extensions that achieve state-of-the-art performance on the QMSum dataset by a margin of up to 3.38 ROUGE-1, 3.72 ROUGE-2, and 3.28 ROUGE-L. Through quantitative experiments we highlight the trade-offs between different model configurations and explore the transfer abilities between summarization tasks. Code and checkpoints are made publicly available: https://github.com/salesforce/query-focused-sum.
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Dec 08, 2021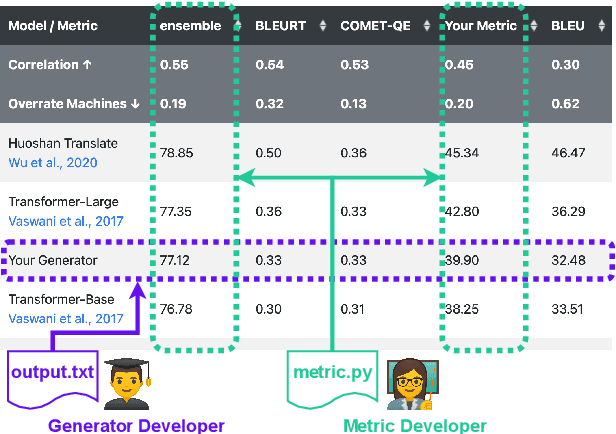
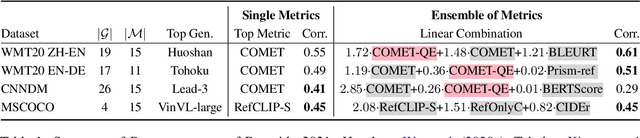
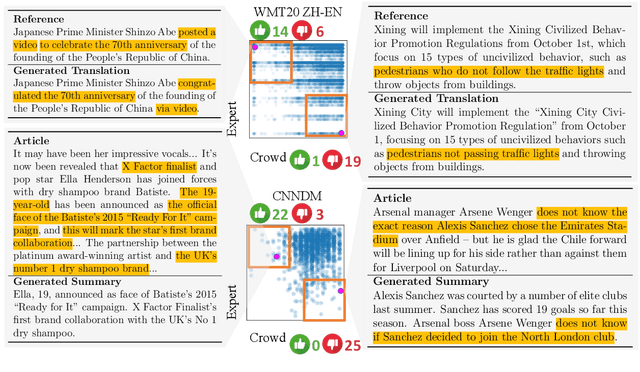

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.
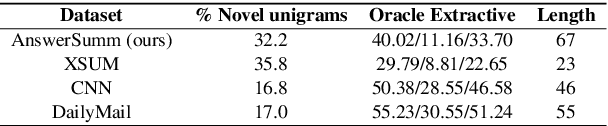
AnswerSumm: A Manually-Curated Dataset and Pipeline for Answer Summarization
Nov 11, 2021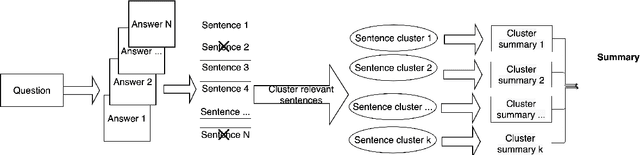
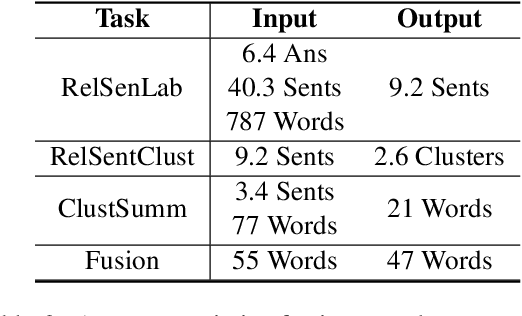
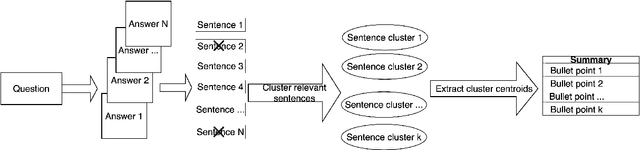
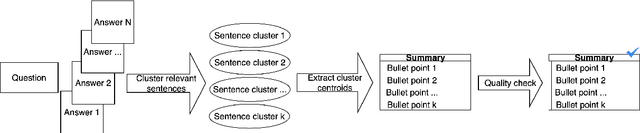
Community Question Answering (CQA) fora such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of community-based questions. Each question thread can receive a large number of answers with different perspectives. One goal of answer summarization is to produce a summary that reflects the range of answer perspectives. A major obstacle for abstractive answer summarization is the absence of a dataset to provide supervision for producing such summaries. Recent works propose heuristics to create such data, but these are often noisy and do not cover all perspectives present in the answers. This work introduces a novel dataset of 4,631 CQA threads for answer summarization, curated by professional linguists. Our pipeline gathers annotations for all subtasks involved in answer summarization, including the selection of answer sentences relevant to the question, grouping these sentences based on perspectives, summarizing each perspective, and producing an overall summary. We analyze and benchmark state-of-the-art models on these subtasks and introduce a novel unsupervised approach for multi-perspective data augmentation, that further boosts overall summarization performance according to automatic evaluation. Finally, we propose reinforcement learning rewards to improve factual consistency and answer coverage and analyze areas for improvement.
Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Sep 21, 2021
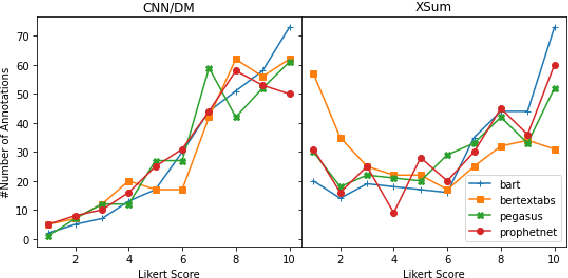
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.
ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining
Jun 01, 2021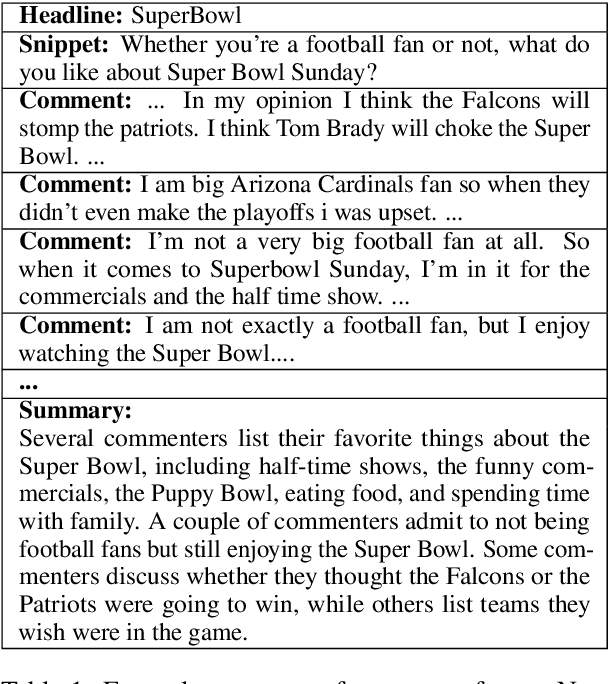


While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues--viewpoints--assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.
Multi-Perspective Abstractive Answer Summarization
Apr 17, 2021

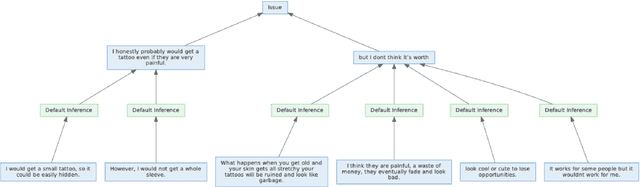
Community Question Answering (CQA) forums such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of questions. Each question thread can receive a large number of answers with different perspectives. The goal of multi-perspective answer summarization is to produce a summary that includes all perspectives of the answer. A major obstacle for multi-perspective, abstractive answer summarization is the absence of a dataset to provide supervision for producing such summaries. This work introduces a novel dataset creation method to automatically create multi-perspective, bullet-point abstractive summaries from an existing CQA forum. Supervision provided by this dataset trains models to inherently produce multi-perspective summaries. Additionally, to train models to output more diverse, faithful answer summaries while retaining multiple perspectives, we propose a multi-reward optimization technique coupled with a sentence-relevance prediction multi-task loss. Our methods demonstrate improved coverage of perspectives and faithfulness as measured by automatic and human evaluations compared to a strong baseline.
Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation
Oct 24, 2020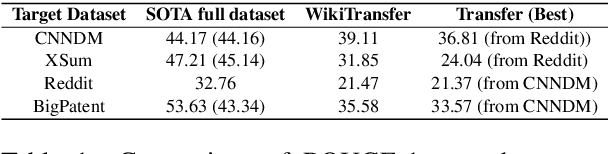
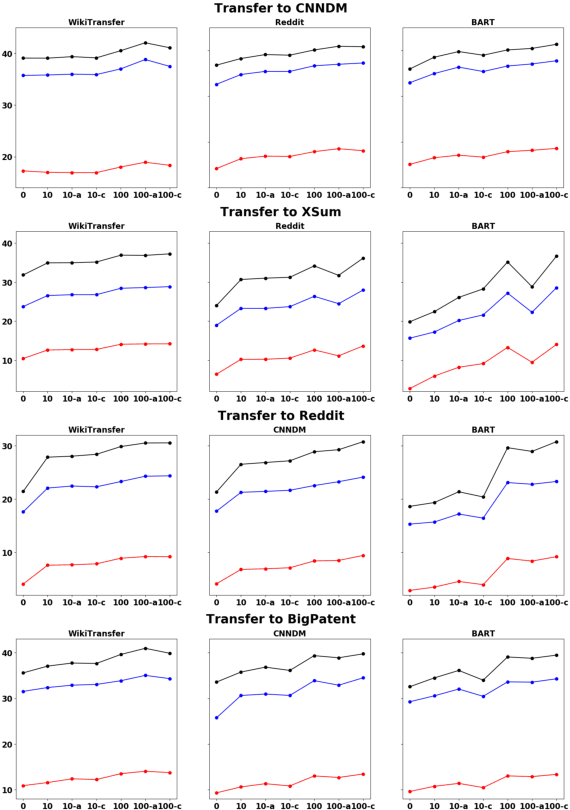

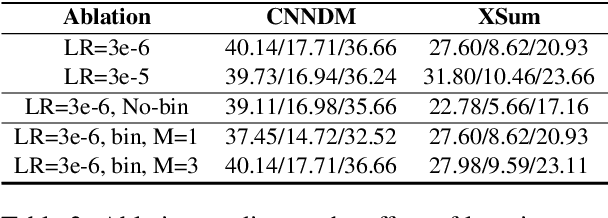
Models pretrained with self-supervised objectives on large text corpora achieve state-of-the-art performance on text summarization tasks. However, these models are typically fine-tuned on hundreds of thousands of data points, an infeasible requirement when applying summarization to new, niche domains. In this work, we introduce a general method, called WikiTransfer, for fine-tuning pretrained models for summarization in an unsupervised, dataset-specific manner which makes use of characteristics of the target dataset such as the length and abstractiveness of the desired summaries. We achieve state-of-the-art, zero-shot abstractive summarization performance on the CNN-DailyMail dataset and demonstrate the effectiveness of our approach on three additional, diverse datasets. The models fine-tuned in this unsupervised manner are more robust to noisy data and also achieve better few-shot performance using 10 and 100 training examples. We perform ablation studies on the effect of the components of our unsupervised fine-tuning data and analyze the performance of these models in few-shot scenarios along with data augmentation techniques using both automatic and human evaluation.
SummEval: Re-evaluating Summarization Evaluation
Jul 31, 2020
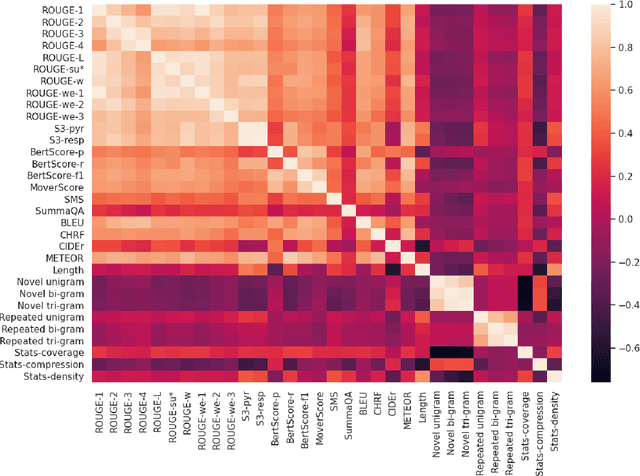
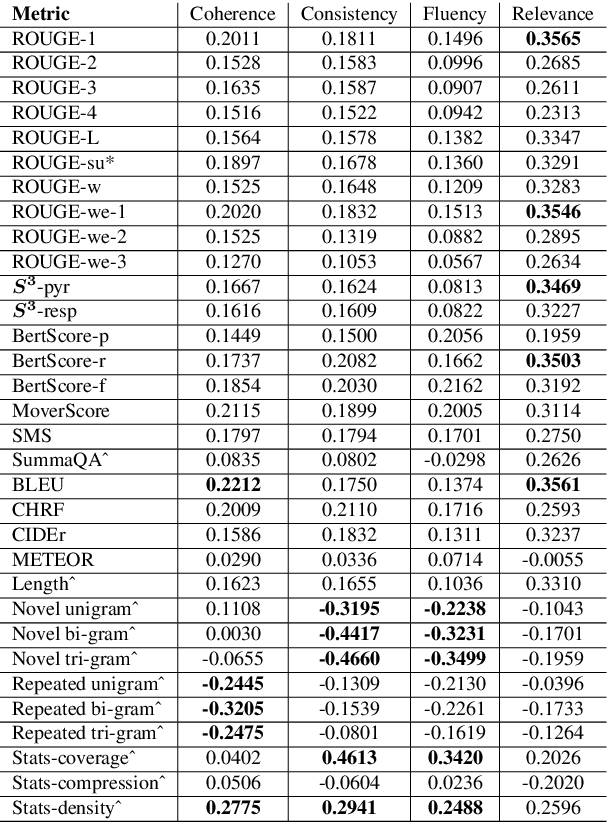
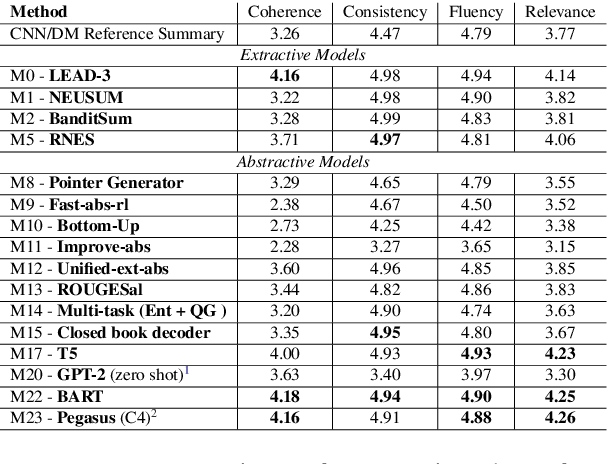
The scarcity of comprehensive up-to-date studies on evaluation metrics for text summarization and the lack of consensus regarding evaluation protocols continues to inhibit progress. We address the existing shortcomings of summarization evaluation methods along five dimensions: 1) we re-evaluate 12 automatic evaluation metrics in a comprehensive and consistent fashion using neural summarization model outputs along with expert and crowd-sourced human annotations, 2) we consistently benchmark 23 recent summarization models using the aforementioned automatic evaluation metrics, 3) we assemble the largest collection of summaries generated by models trained on the CNN/DailyMail news dataset and share it in a unified format, 4) we implement and share a toolkit that provides an extensible and unified API for evaluating summarization models across a broad range of automatic metrics, 5) we assemble and share the largest and most diverse, in terms of model types, collection of human judgments of model-generated summaries on the CNN/Daily Mail dataset annotated by both expert judges and crowd source workers. We hope that this work will help promote a more complete evaluation protocol for text summarization as well as advance research in developing evaluation metrics that better correlate with human judgements.
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Apr 24, 2020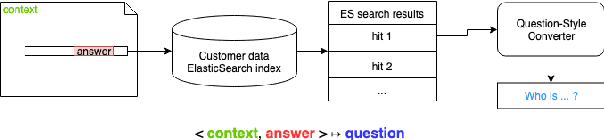


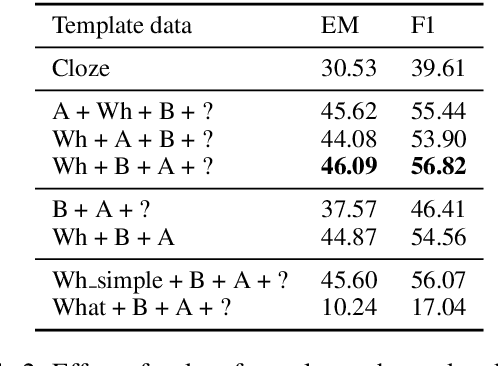
Question Answering (QA) is in increasing demand as the amount of information available online and the desire for quick access to this content grows. A common approach to QA has been to fine-tune a pretrained language model on a task-specific labeled dataset. This paradigm, however, relies on scarce, and costly to obtain, large-scale human-labeled data. We propose an unsupervised approach to training QA models with generated pseudo-training data. We show that generating questions for QA training by applying a simple template on a related, retrieved sentence rather than the original context sentence improves downstream QA performance by allowing the model to learn more complex context-question relationships. Training a QA model on this data gives a relative improvement over a previous unsupervised model in F1 score on the SQuAD dataset by about 14%, and 20% when the answer is a named entity, achieving state-of-the-art performance on SQuAD for unsupervised QA.