 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIC: Permutation Invariant Critic for Multi-Agent Deep Reinforcement Learning
Oct 31, 2019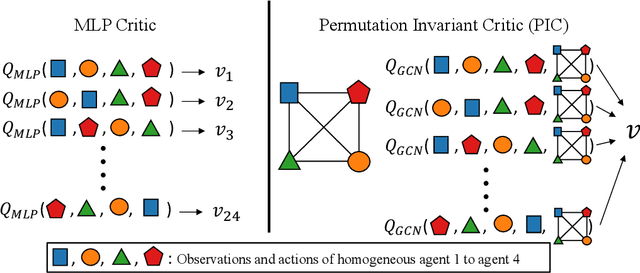
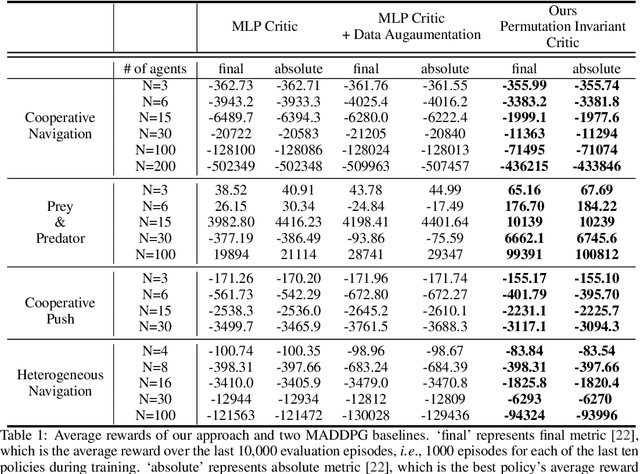
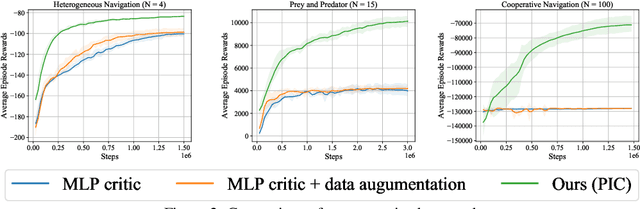
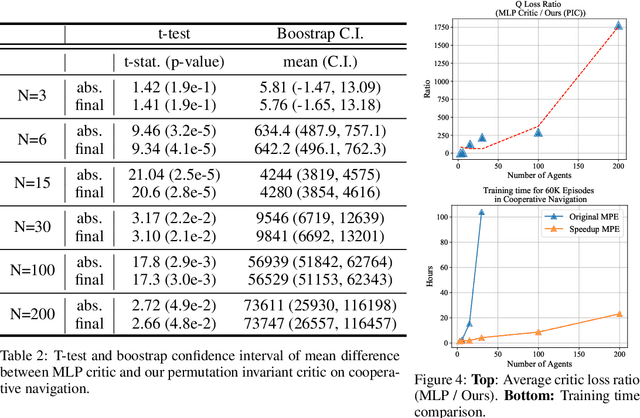
Sample efficiency and scalability to a large number of agents are two important goals for multi-agent reinforcement learning systems. Recent works got us closer to those goals, addressing non-stationarity of the environment from a single agent's perspective by utilizing a deep net critic which depends on all observations and actions. The critic input concatenates agent observations and actions in a user-specified order. However, since deep nets aren't permutation invariant, a permuted input changes the critic output despite the environment remaining identical. To avoid this inefficiency, we propose a 'permutation invariant critic' (PIC), which yields identical output irrespective of the agent permutation. This consistent representation enables our model to scale to 30 times more agents and to achieve improvements of test episode reward between 15% to 50% on the challenging multi-agent particle environment (MPE).
Co-Generation with GANs using AIS based HMC
Oct 31, 2019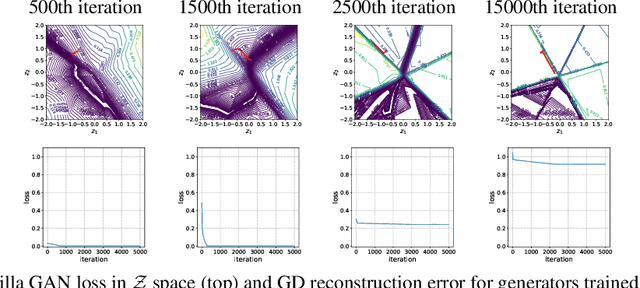
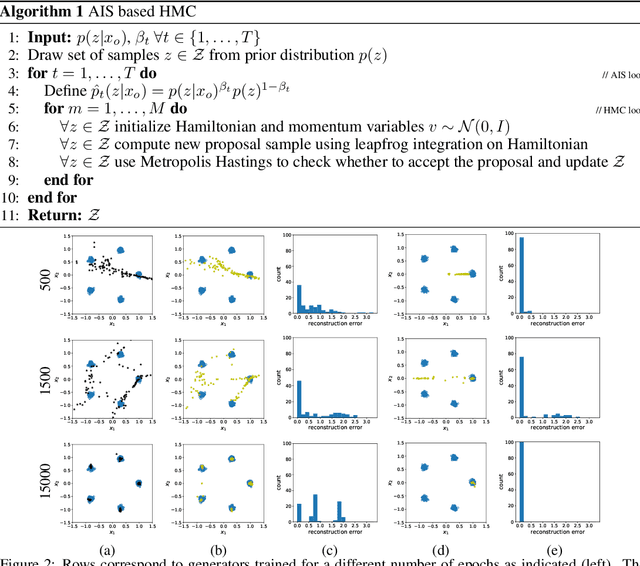
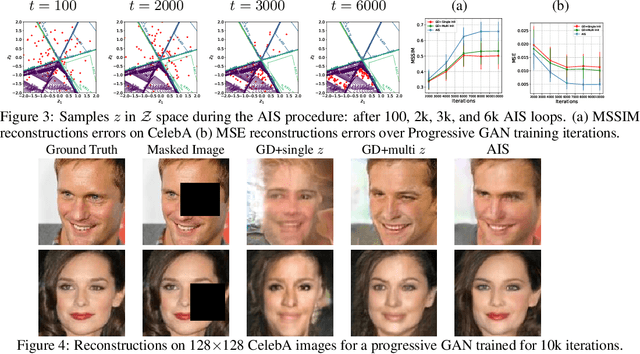

Inferring the most likely configuration for a subset of variables of a joint distribution given the remaining ones - which we refer to as co-generation - is an important challenge that is computationally demanding for all but the simplest settings. This task has received a considerable amount of attention, particularly for classical ways of modeling distributions like structured prediction. In contrast, almost nothing is known about this task when considering recently proposed techniques for modeling high-dimensional distributions, particularly generative adversarial nets (GANs). Therefore, in this paper, we study the occurring challenges for co-generation with GANs. To address those challenges we develop an annealed importance sampling based Hamiltonian Monte Carlo co-generation algorithm. The presented approach significantly outperforms classical gradient based methods on a synthetic and on the CelebA and LSUN datasets.
TAB-VCR: Tags and Attributes based VCR Baselines
Oct 31, 2019
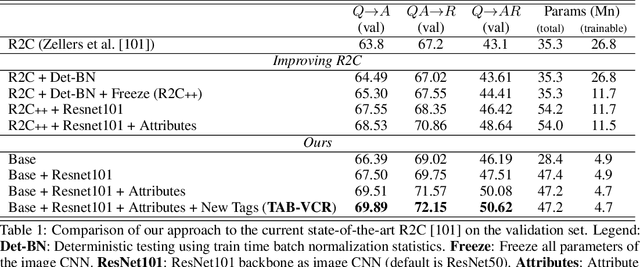
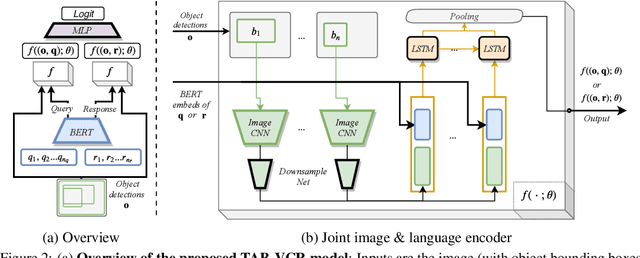

Reasoning is an important ability that we learn from a very early age. Yet, reasoning is extremely hard for algorithms. Despite impressive recent progress that has been reported on tasks that necessitate reasoning, such as visual question answering and visual dialog, models often exploit biases in datasets. To develop models with better reasoning abilities, recently, the new visual commonsense reasoning(VCR) task has been introduced. Not only do models have to answer questions, but also do they have to provide a reason for the given answer. The proposed baseline achieved compelling results, leveraging a meticulously designed model composed of LSTM modules and attention nets. Here we show that a much simpler model obtained by ablating and pruning the existing intricate baseline can perform better with half the number of trainable parameters. By associating visual features with attribute information and better text to image grounding, we obtain further improvements for our simpler & effective baseline, TAB-VCR. We show that this approach results in a 5.3%, 4.4% and 6.5% absolute improvement over the previous state-of-the-art on question answering, answer justification and holistic VCR.
FMRI data augmentation via synthesis
Jul 13, 2019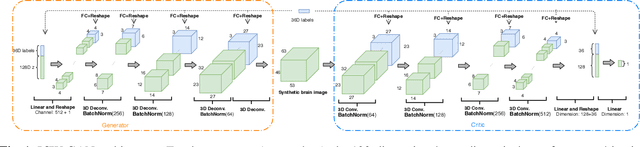
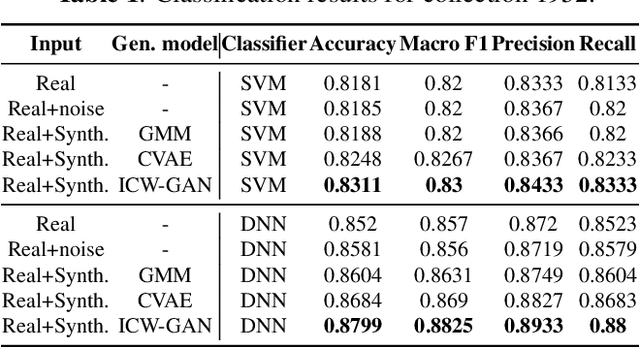
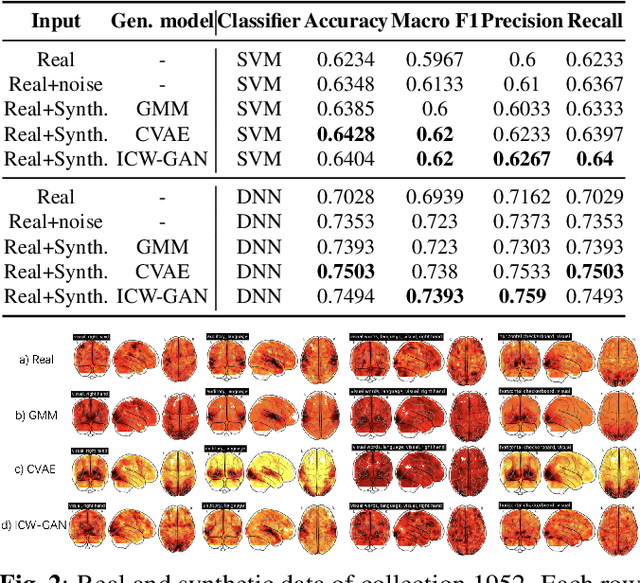
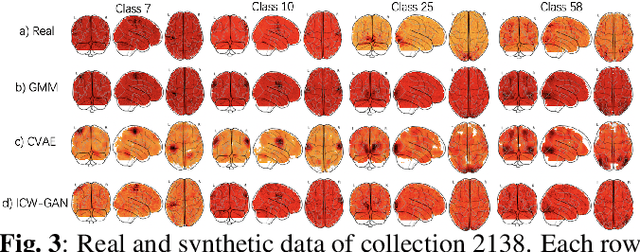
We present an empirical evaluation of fMRI data augmentation via synthesis. For synthesis we use generative mod-els trained on real neuroimaging data to produce novel task-dependent functional brain images. Analyzed generative mod-els include classic approaches such as the Gaussian mixture model (GMM), and modern implicit generative models such as the generative adversarial network (GAN) and the variational auto-encoder (VAE). In particular, the proposed GAN and VAE models utilize 3-dimensional convolutions, which enables modeling of high-dimensional brain image tensors with structured spatial correlations. The synthesized datasets are then used to augment classifiers designed to predict cognitive and behavioural outcomes. Our results suggest that the proposed models are able to generate high-quality synthetic brain images which are diverse and task-dependent. Perhaps most importantly, the performance improvements of data aug-mentation via synthesis are shown to be complementary to the choice of the predictive model. Thus, our results suggest that data augmentation via synthesis is a promising approach to address the limited availability of fMRI data, and to improve the quality of predictive fMRI models.
Knowledge Flow: Improve Upon Your Teachers
Apr 11, 2019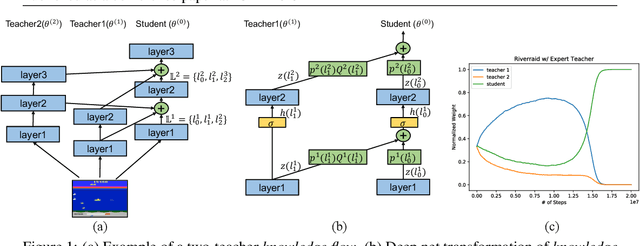
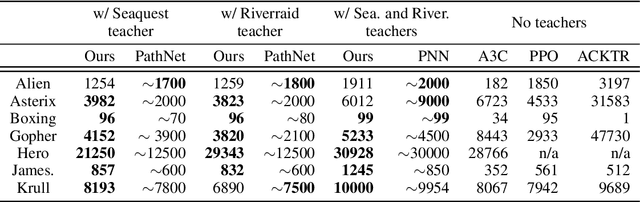
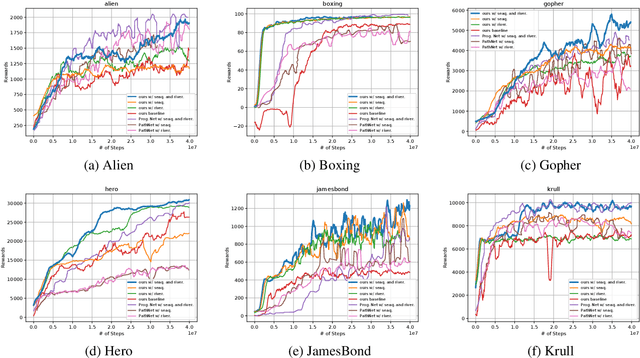
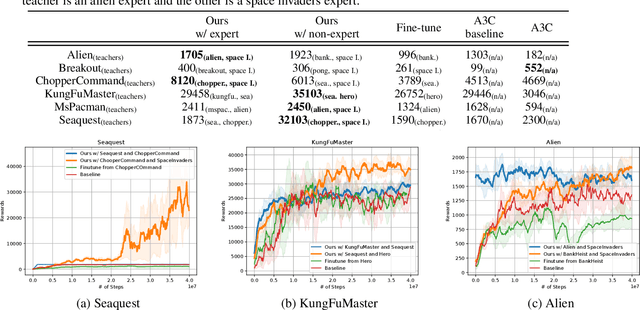
A zoo of deep nets is available these days for almost any given task, and it is increasingly unclear which net to start with when addressing a new task, or which net to use as an initialization for fine-tuning a new model. To address this issue, in this paper, we develop knowledge flow which moves 'knowledge' from multiple deep nets, referred to as teachers, to a new deep net model, called the student. The structure of the teachers and the student can differ arbitrarily and they can be trained on entirely different tasks with different output spaces too. Upon training with knowledge flow the student is independent of the teachers. We demonstrate our approach on a variety of supervised and reinforcement learning tasks, outperforming fine-tuning and other 'knowledge exchange' methods.
Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering
Nov 01, 2018

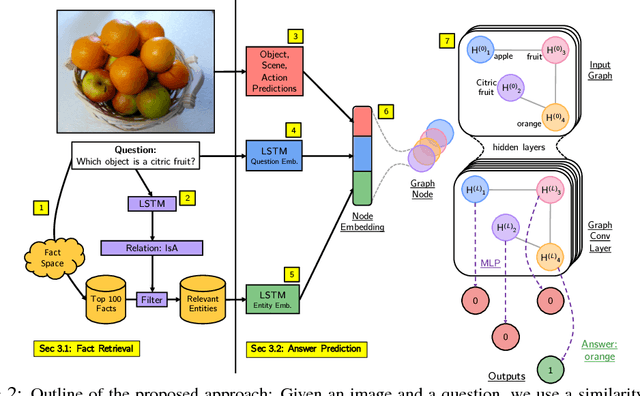
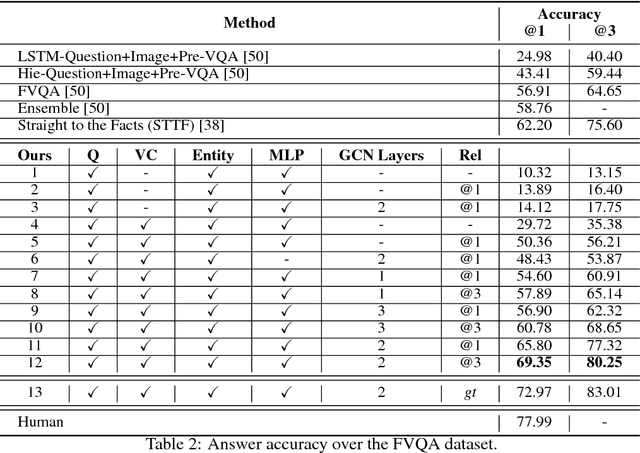
Accurately answering a question about a given image requires combining observations with general knowledge. While this is effortless for humans, reasoning with general knowledge remains an algorithmic challenge. To advance research in this direction a novel `fact-based' visual question answering (FVQA) task has been introduced recently along with a large set of curated facts which link two entities, i.e., two possible answers, via a relation. Given a question-image pair, deep network techniques have been employed to successively reduce the large set of facts until one of the two entities of the final remaining fact is predicted as the answer. We observe that a successive process which considers one fact at a time to form a local decision is sub-optimal. Instead, we develop an entity graph and use a graph convolutional network to `reason' about the correct answer by jointly considering all entities. We show on the challenging FVQA dataset that this leads to an improvement in accuracy of around 7% compared to the state of the art.
Structural Consistency and Controllability for Diverse Colorization
Sep 06, 2018
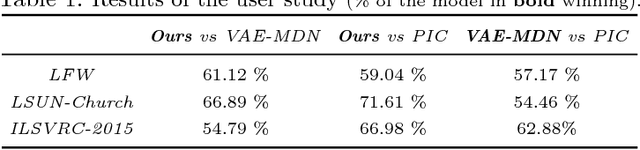

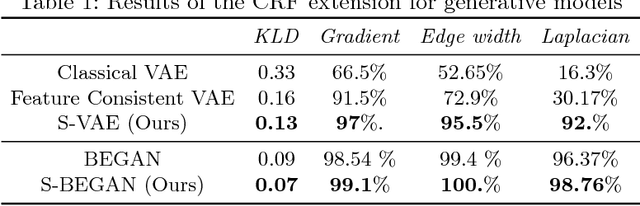
Colorizing a given gray-level image is an important task in the media and advertising industry. Due to the ambiguity inherent to colorization (many shades are often plausible), recent approaches started to explicitly model diversity. However, one of the most obvious artifacts, structural inconsistency, is rarely considered by existing methods which predict chrominance independently for every pixel. To address this issue, we develop a conditional random field based variational auto-encoder formulation which is able to achieve diversity while taking into account structural consistency. Moreover, we introduce a controllability mecha- nism that can incorporate external constraints from diverse sources in- cluding a user interface. Compared to existing baselines, we demonstrate that our method obtains more diverse and globally consistent coloriza- tions on the LFW, LSUN-Church and ILSVRC-2015 datasets.
Unsupervised Video Object Segmentation using Motion Saliency-Guided Spatio-Temporal Propagation
Sep 04, 2018

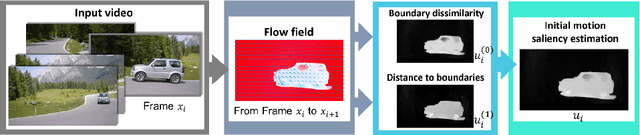

Unsupervised video segmentation plays an important role in a wide variety of applications from object identification to compression. However, to date, fast motion, motion blur and occlusions pose significant challenges. To address these challenges for unsupervised video segmentation, we develop a novel saliency estimation technique as well as a novel neighborhood graph, based on optical flow and edge cues. Our approach leads to significantly better initial foreground-background estimates and their robust as well as accurate diffusion across time. We evaluate our proposed algorithm on the challenging DAVIS, SegTrack v2 and FBMS-59 datasets. Despite the usage of only a standard edge detector trained on 200 images, our method achieves state-of-the-art results outperforming deep learning based methods in the unsupervised setting. We even demonstrate competitive results comparable to deep learning based methods in the semi-supervised setting on the DAVIS dataset.
Straight to the Facts: Learning Knowledge Base Retrieval for Factual Visual Question Answering
Sep 04, 2018

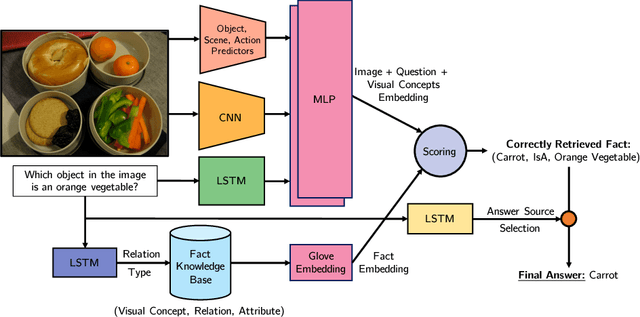

Question answering is an important task for autonomous agents and virtual assistants alike and was shown to support the disabled in efficiently navigating an overwhelming environment. Many existing methods focus on observation-based questions, ignoring our ability to seamlessly combine observed content with general knowledge. To understand interactions with a knowledge base, a dataset has been introduced recently and keyword matching techniques were shown to yield compelling results despite being vulnerable to misconceptions due to synonyms and homographs. To address this issue, we develop a learning-based approach which goes straight to the facts via a learned embedding space. We demonstrate state-of-the-art results on the challenging recently introduced fact-based visual question answering dataset, outperforming competing methods by more than 5%.
VideoMatch: Matching based Video Object Segmentation
Sep 04, 2018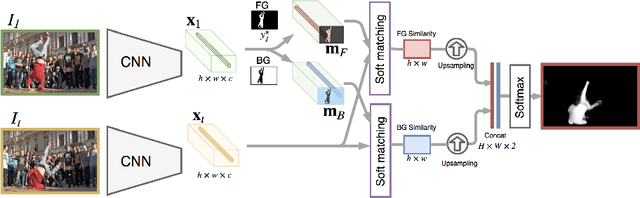

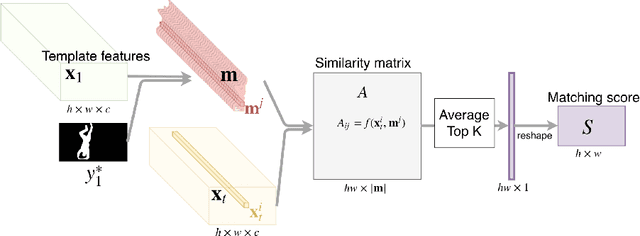

Video object segmentation is challenging yet important in a wide variety of applications for video analysis. Recent works formulate video object segmentation as a prediction task using deep nets to achieve appealing state-of-the-art performance. Due to the formulation as a prediction task, most of these methods require fine-tuning during test time, such that the deep nets memorize the appearance of the objects of interest in the given video. However, fine-tuning is time-consuming and computationally expensive, hence the algorithms are far from real time. To address this issue, we develop a novel matching based algorithm for video object segmentation. In contrast to memorization based classification techniques, the proposed approach learns to match extracted features to a provided template without memorizing the appearance of the objects. We validate the effectiveness and the robustness of the proposed method on the challenging DAVIS-16, DAVIS-17, Youtube-Objects and JumpCut datasets. Extensive results show that our method achieves comparable performance without fine-tuning and is much more favorable in terms of computational time.