 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Volumetric Object Selection
May 30, 2022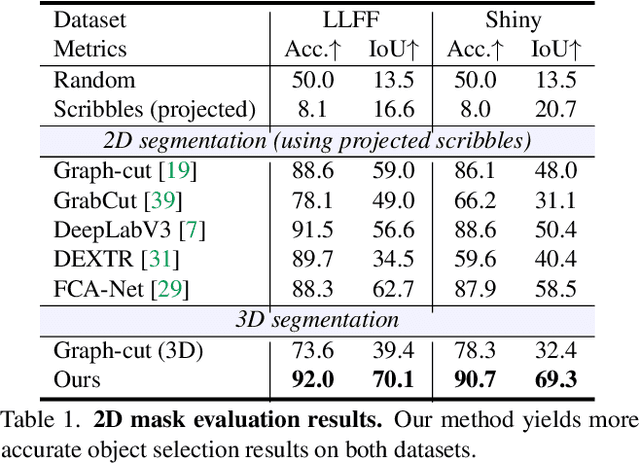
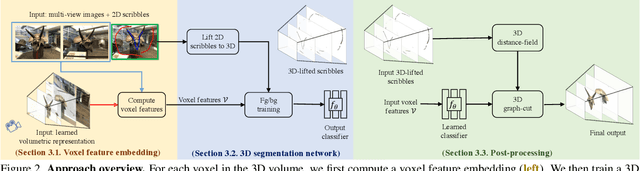


We introduce an approach for selecting objects in neural volumetric 3D representations, such as multi-plane images (MPI) and neural radiance fields (NeRF). Our approach takes a set of foreground and background 2D user scribbles in one view and automatically estimates a 3D segmentation of the desired object, which can be rendered into novel views. To achieve this result, we propose a novel voxel feature embedding that incorporates the neural volumetric 3D representation and multi-view image features from all input views. To evaluate our approach, we introduce a new dataset of human-provided segmentation masks for depicted objects in real-world multi-view scene captures. We show that our approach out-performs strong baselines, including 2D segmentation and 3D segmentation approaches adapted to our task.
Asking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022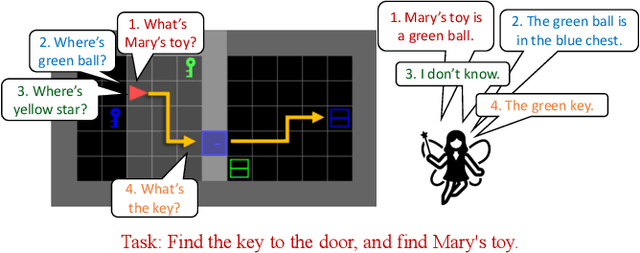
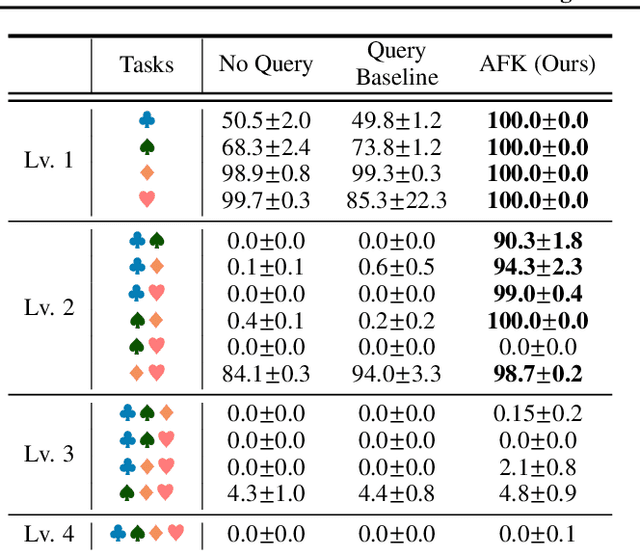


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
Total Variation Optimization Layers for Computer Vision
Apr 07, 2022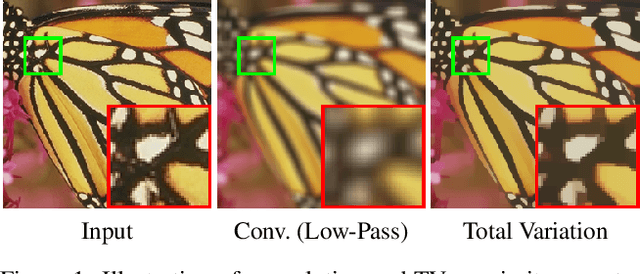



Optimization within a layer of a deep-net has emerged as a new direction for deep-net layer design. However, there are two main challenges when applying these layers to computer vision tasks: (a) which optimization problem within a layer is useful?; (b) how to ensure that computation within a layer remains efficient? To study question (a), in this work, we propose total variation (TV) minimization as a layer for computer vision. Motivated by the success of total variation in image processing, we hypothesize that TV as a layer provides useful inductive bias for deep-nets too. We study this hypothesis on five computer vision tasks: image classification, weakly supervised object localization, edge-preserving smoothing, edge detection, and image denoising, improving over existing baselines. To achieve these results we had to address question (b): we developed a GPU-based projected-Newton method which is $37\times$ faster than existing solutions.
Equivariance Discovery by Learned Parameter-Sharing
Apr 07, 2022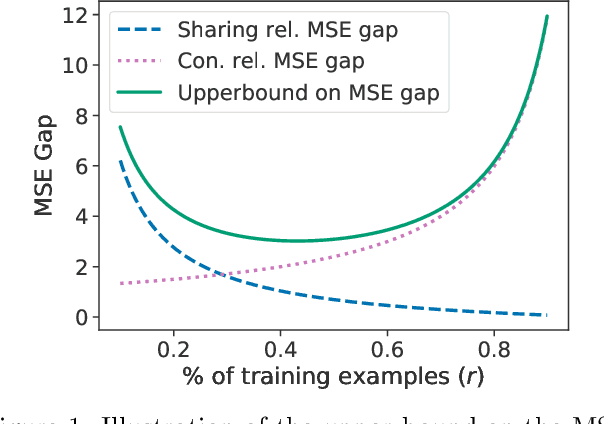
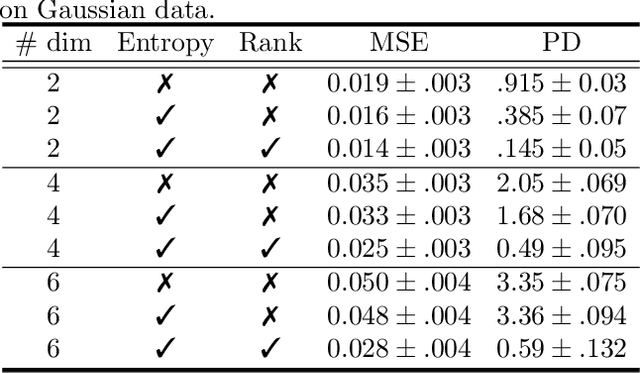
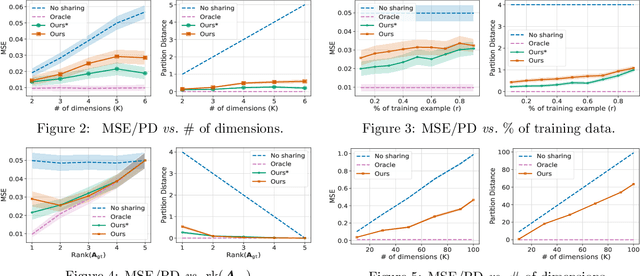
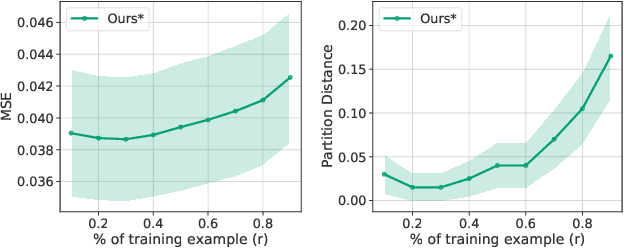
Designing equivariance as an inductive bias into deep-nets has been a prominent approach to build effective models, e.g., a convolutional neural network incorporates translation equivariance. However, incorporating these inductive biases requires knowledge about the equivariance properties of the data, which may not be available, e.g., when encountering a new domain. To address this, we study how to discover interpretable equivariances from data. Specifically, we formulate this discovery process as an optimization problem over a model's parameter-sharing schemes. We propose to use the partition distance to empirically quantify the accuracy of the recovered equivariance. Also, we theoretically analyze the method for Gaussian data and provide a bound on the mean squared gap between the studied discovery scheme and the oracle scheme. Empirically, we show that the approach recovers known equivariances, such as permutations and shifts, on sum of numbers and spatially-invariant data.
Mask2Former for Video Instance Segmentation
Dec 20, 2021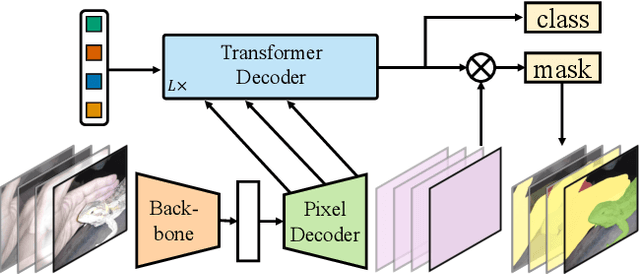
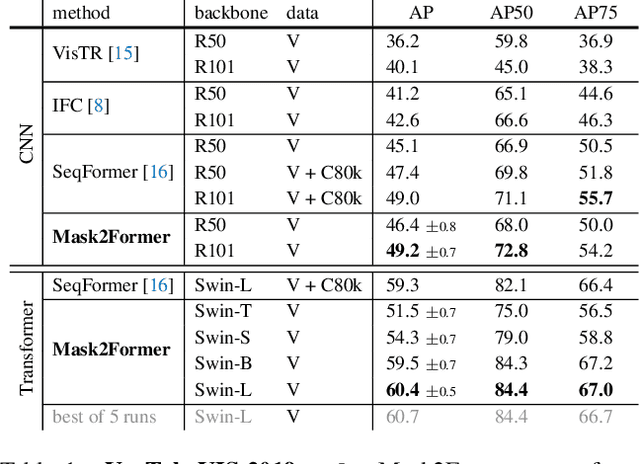
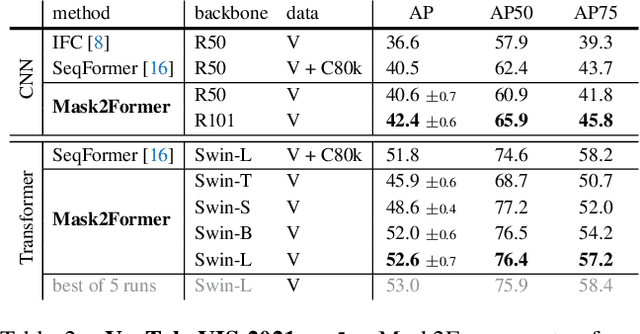
We find Mask2Former also achieves state-of-the-art performance on video instance segmentation without modifying the architecture, the loss or even the training pipeline. In this report, we show universal image segmentation architectures trivially generalize to video segmentation by directly predicting 3D segmentation volumes. Specifically, Mask2Former sets a new state-of-the-art of 60.4 AP on YouTubeVIS-2019 and 52.6 AP on YouTubeVIS-2021. We believe Mask2Former is also capable of handling video semantic and panoptic segmentation, given its versatility in image segmentation. We hope this will make state-of-the-art video segmentation research more accessible and bring more attention to designing universal image and video segmentation architectures.
Masked-attention Mask Transformer for Universal Image Segmentation
Dec 10, 2021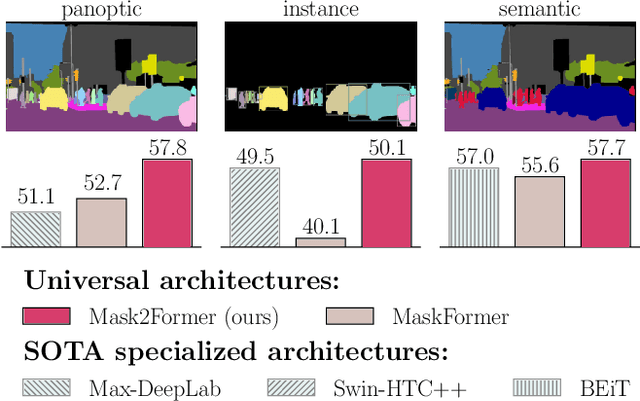
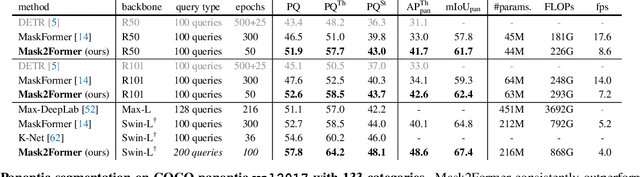
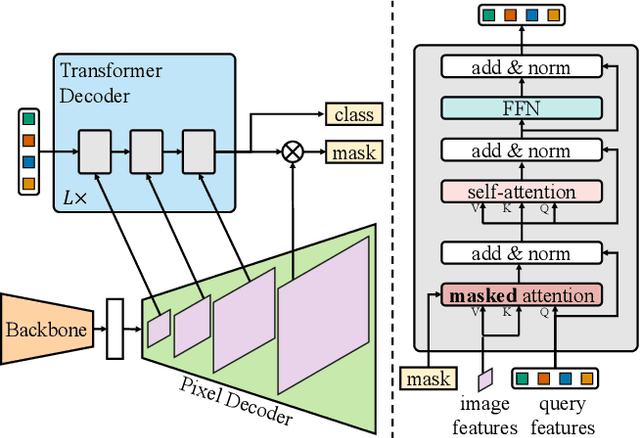
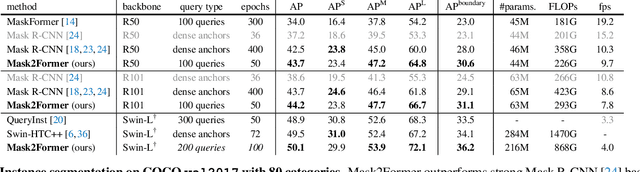
Image segmentation is about grouping pixels with different semantics, e.g., category or instance membership, where each choice of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
Class-agnostic Reconstruction of Dynamic Objects from Videos
Dec 03, 2021
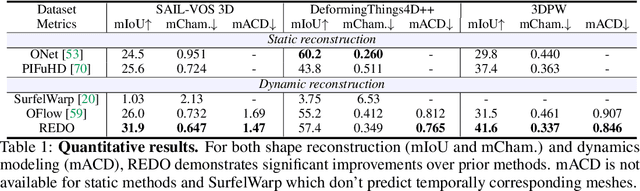
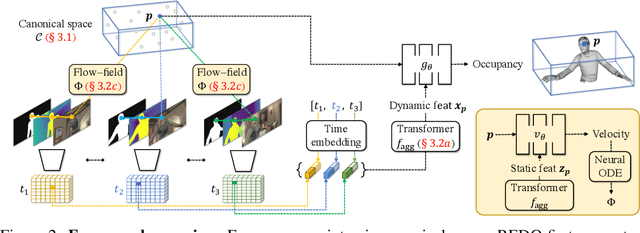
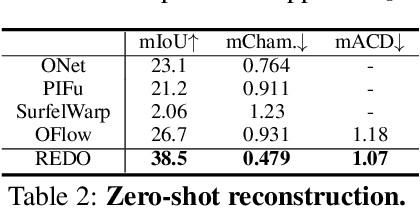
We introduce REDO, a class-agnostic framework to REconstruct the Dynamic Objects from RGBD or calibrated videos. Compared to prior work, our problem setting is more realistic yet more challenging for three reasons: 1) due to occlusion or camera settings an object of interest may never be entirely visible, but we aim to reconstruct the complete shape; 2) we aim to handle different object dynamics including rigid motion, non-rigid motion, and articulation; 3) we aim to reconstruct different categories of objects with one unified framework. To address these challenges, we develop two novel modules. First, we introduce a canonical 4D implicit function which is pixel-aligned with aggregated temporal visual cues. Second, we develop a 4D transformation module which captures object dynamics to support temporal propagation and aggregation. We study the efficacy of REDO in extensive experiments on synthetic RGBD video datasets SAIL-VOS 3D and DeformingThings4D++, and on real-world video data 3DPW. We find REDO outperforms state-of-the-art dynamic reconstruction methods by a margin. In ablation studies we validate each developed component.
Semantic Tracklets: An Object-Centric Representation for Visual Multi-Agent Reinforcement Learning
Aug 06, 2021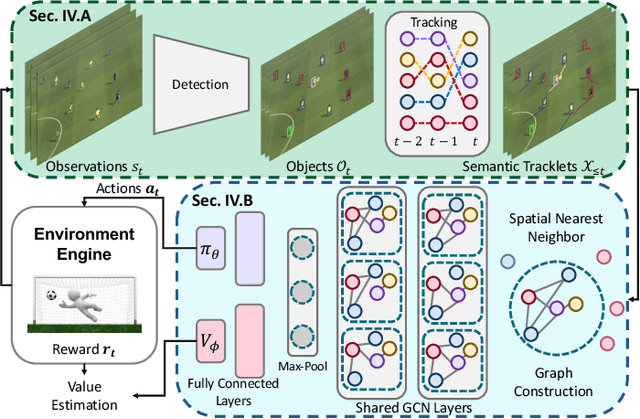
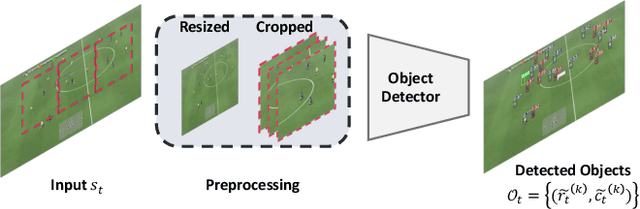


Solving complex real-world tasks, e.g., autonomous fleet control, often involves a coordinated team of multiple agents which learn strategies from visual inputs via reinforcement learning. Many existing multi-agent reinforcement learning (MARL) algorithms however don't scale to environments where agents operate on visual inputs. To address this issue, algorithmically, recent works have focused on non-stationarity and exploration. In contrast, we study whether scalability can also be achieved via a disentangled representation. For this, we explicitly construct an object-centric intermediate representation to characterize the states of an environment, which we refer to as `semantic tracklets.' We evaluate `semantic tracklets' on the visual multi-agent particle environment (VMPE) and on the challenging visual multi-agent GFootball environment. `Semantic tracklets' consistently outperform baselines on VMPE, and achieve a +2.4 higher score difference than baselines on GFootball. Notably, this method is the first to successfully learn a strategy for five players in the GFootball environment using only visual data.
Cooperative Exploration for Multi-Agent Deep Reinforcement Learning
Jul 23, 2021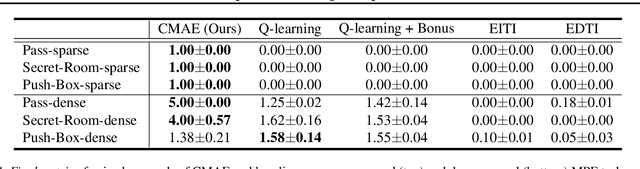
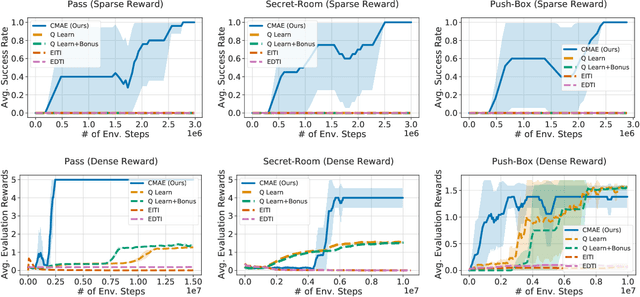
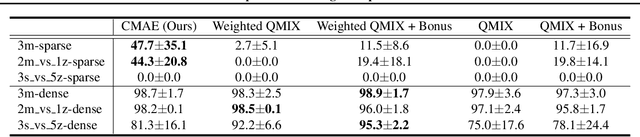
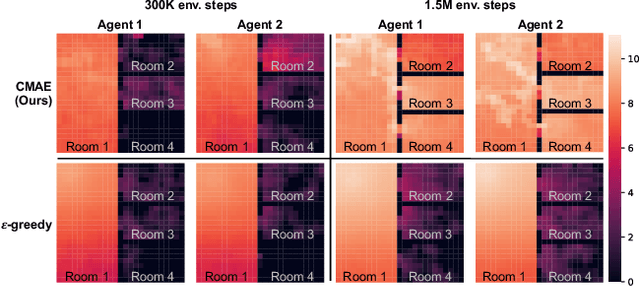
Exploration is critical for good results in deep reinforcement learning and has attracted much attention. However, existing multi-agent deep reinforcement learning algorithms still use mostly noise-based techniques. Very recently, exploration methods that consider cooperation among multiple agents have been developed. However, existing methods suffer from a common challenge: agents struggle to identify states that are worth exploring, and hardly coordinate exploration efforts toward those states. To address this shortcoming, in this paper, we propose cooperative multi-agent exploration (CMAE): agents share a common goal while exploring. The goal is selected from multiple projected state spaces via a normalized entropy-based technique. Then, agents are trained to reach this goal in a coordinated manner. We demonstrate that CMAE consistently outperforms baselines on various tasks, including a sparse-reward version of the multiple-particle environment (MPE) and the Starcraft multi-agent challenge (SMAC).
Per-Pixel Classification is Not All You Need for Semantic Segmentation
Jul 13, 2021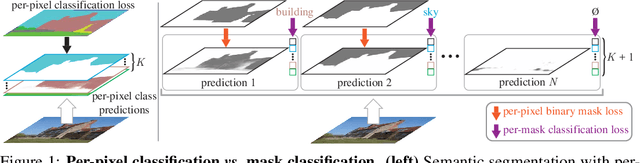
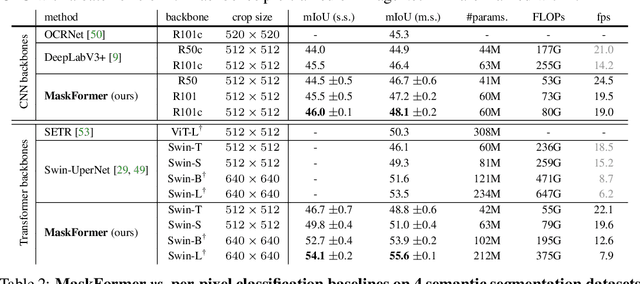
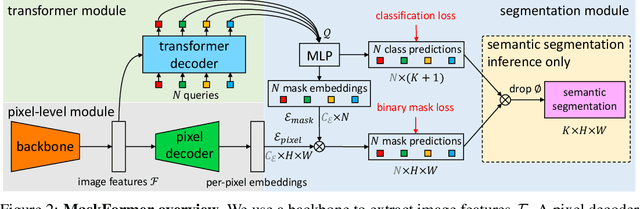

Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.