 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Explanatory Heatmap Resolution and Semantics via Decomposition Depth
Apr 04, 2016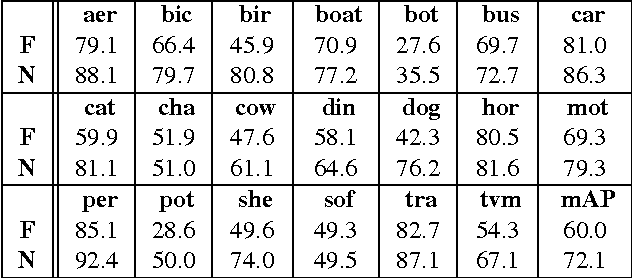

We present an application of the Layer-wise Relevance Propagation (LRP) algorithm to state of the art deep convolutional neural networks and Fisher Vector classifiers to compare the image perception and prediction strategies of both classifiers with the use of visualized heatmaps. Layer-wise Relevance Propagation (LRP) is a method to compute scores for individual components of an input image, denoting their contribution to the prediction of the classifier for one particular test point. We demonstrate the impact of different choices of decomposition cut-off points during the LRP-process, controlling the resolution and semantics of the heatmap on test images from the PASCAL VOC 2007 test data set.
Explaining NonLinear Classification Decisions with Deep Taylor Decomposition
Dec 08, 2015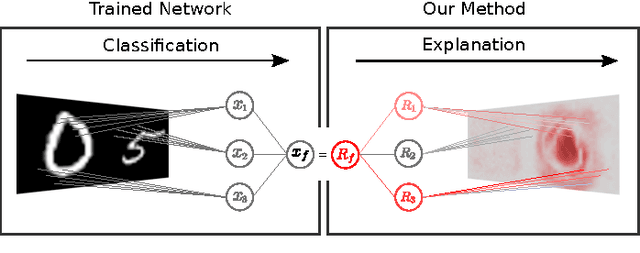
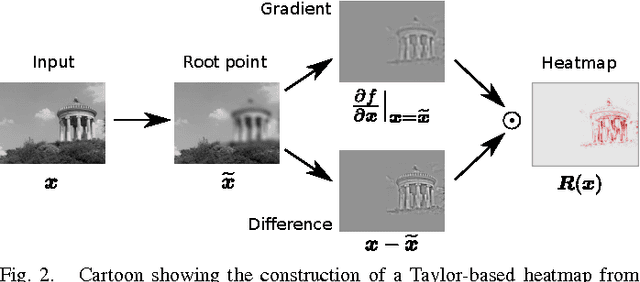
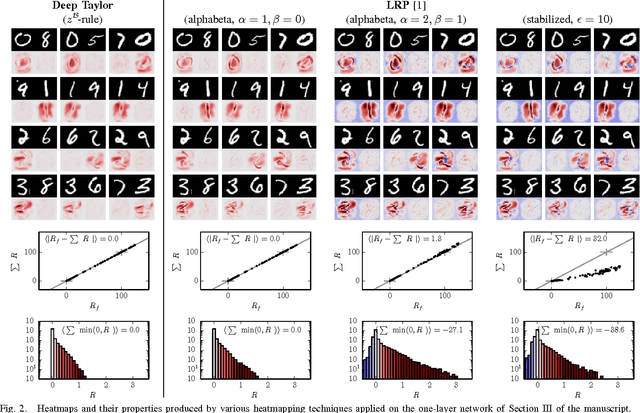
Nonlinear methods such as Deep Neural Networks (DNNs) are the gold standard for various challenging machine learning problems, e.g., image classification, natural language processing or human action recognition. Although these methods perform impressively well, they have a significant disadvantage, the lack of transparency, limiting the interpretability of the solution and thus the scope of application in practice. Especially DNNs act as black boxes due to their multilayer nonlinear structure. In this paper we introduce a novel methodology for interpreting generic multilayer neural networks by decomposing the network classification decision into contributions of its input elements. Although our focus is on image classification, the method is applicable to a broad set of input data, learning tasks and network architectures. Our method is based on deep Taylor decomposition and efficiently utilizes the structure of the network by backpropagating the explanations from the output to the input layer. We evaluate the proposed method empirically on the MNIST and ILSVRC data sets.
Analyzing Classifiers: Fisher Vectors and Deep Neural Networks
Dec 01, 2015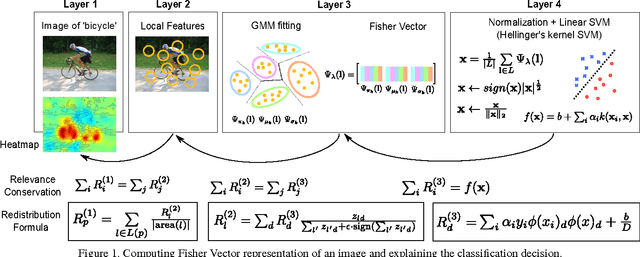
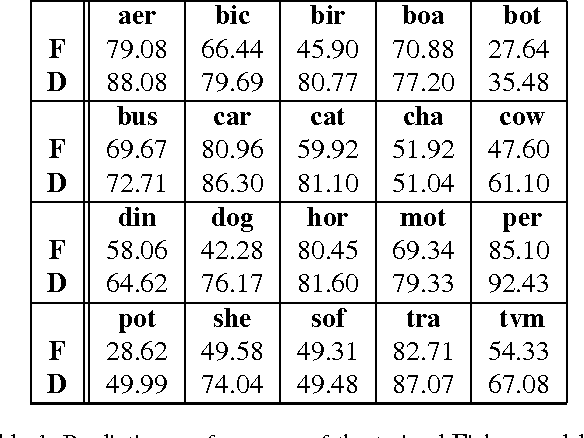
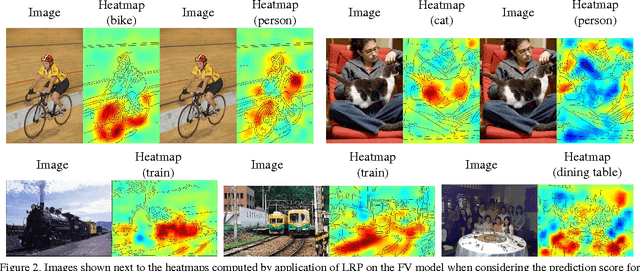

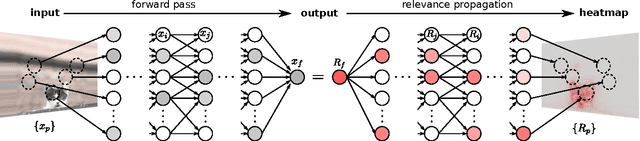
Fisher Vector classifiers and Deep Neural Networks (DNNs) are popular and successful algorithms for solving image classification problems. However, both are generally considered `black box' predictors as the non-linear transformations involved have so far prevented transparent and interpretable reasoning. Recently, a principled technique, Layer-wise Relevance Propagation (LRP), has been developed in order to better comprehend the inherent structured reasoning of complex nonlinear classification models such as Bag of Feature models or DNNs. In this paper we (1) extend the LRP framework also for Fisher Vector classifiers and then use it as analysis tool to (2) quantify the importance of context for classification, (3) qualitatively compare DNNs against FV classifiers in terms of important image regions and (4) detect potential flaws and biases in data. All experiments are performed on the PASCAL VOC 2007 data set.
Evaluating the visualization of what a Deep Neural Network has learned
Sep 21, 2015
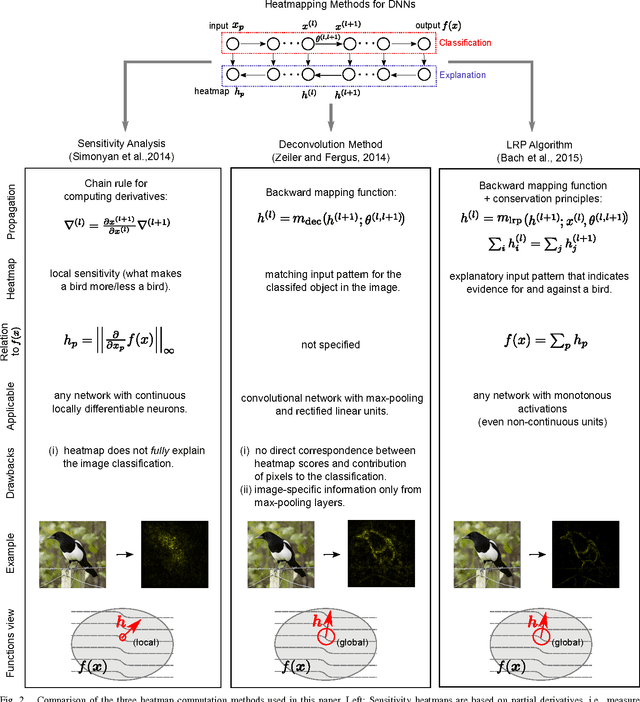
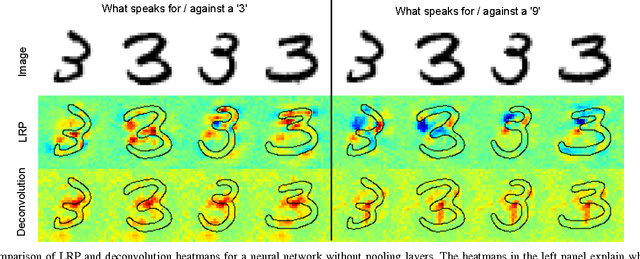
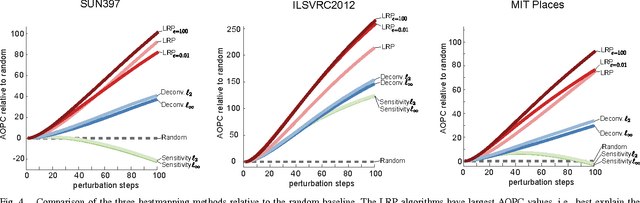
Deep Neural Networks (DNNs) have demonstrated impressive performance in complex machine learning tasks such as image classification or speech recognition. However, due to their multi-layer nonlinear structure, they are not transparent, i.e., it is hard to grasp what makes them arrive at a particular classification or recognition decision given a new unseen data sample. Recently, several approaches have been proposed enabling one to understand and interpret the reasoning embodied in a DNN for a single test image. These methods quantify the ''importance'' of individual pixels wrt the classification decision and allow a visualization in terms of a heatmap in pixel/input space. While the usefulness of heatmaps can be judged subjectively by a human, an objective quality measure is missing. In this paper we present a general methodology based on region perturbation for evaluating ordered collections of pixels such as heatmaps. We compare heatmaps computed by three different methods on the SUN397, ILSVRC2012 and MIT Places data sets. Our main result is that the recently proposed Layer-wise Relevance Propagation (LRP) algorithm qualitatively and quantitatively provides a better explanation of what made a DNN arrive at a particular classification decision than the sensitivity-based approach or the deconvolution method. We provide theoretical arguments to explain this result and discuss its practical implications. Finally, we investigate the use of heatmaps for unsupervised assessment of neural network performance.
Multi-class SVMs: From Tighter Data-Dependent Generalization Bounds to Novel Algorithms
Jun 14, 2015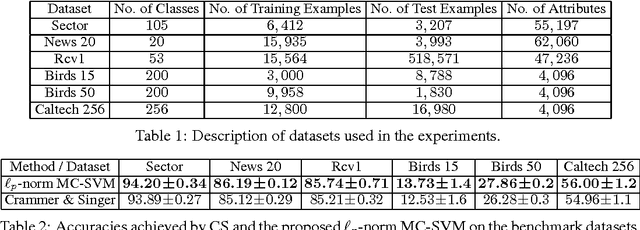
This paper studies the generalization performance of multi-class classification algorithms, for which we obtain, for the first time, a data-dependent generalization error bound with a logarithmic dependence on the class size, substantially improving the state-of-the-art linear dependence in the existing data-dependent generalization analysis. The theoretical analysis motivates us to introduce a new multi-class classification machine based on $\ell_p$-norm regularization, where the parameter $p$ controls the complexity of the corresponding bounds. We derive an efficient optimization algorithm based on Fenchel duality theory. Benchmarks on several real-world datasets show that the proposed algorithm can achieve significant accuracy gains over the state of the art.
Multiple Kernel Learning for Brain-Computer Interfacing
Oct 22, 2013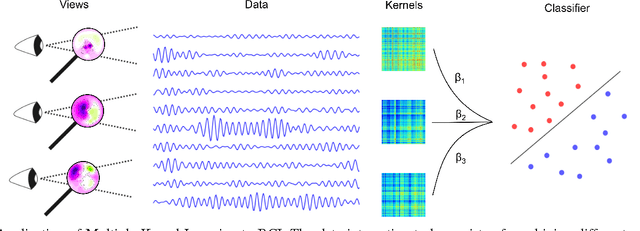
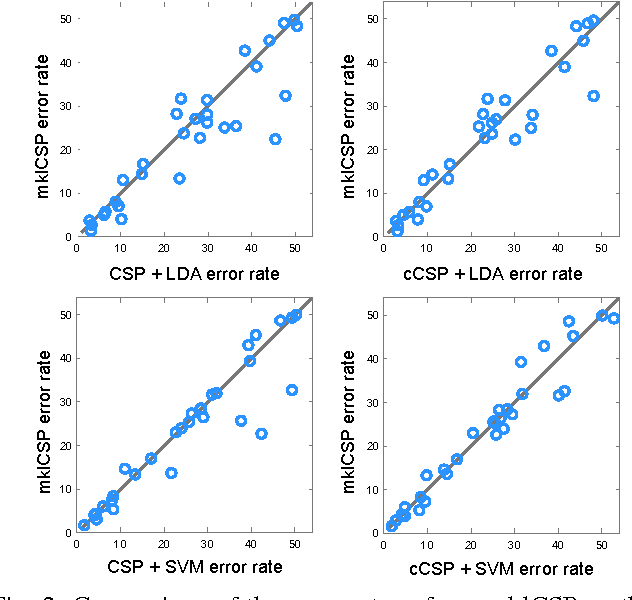

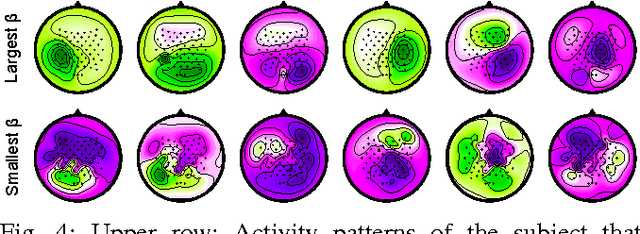
Combining information from different sources is a common way to improve classification accuracy in Brain-Computer Interfacing (BCI). For instance, in small sample settings it is useful to integrate data from other subjects or sessions in order to improve the estimation quality of the spatial filters or the classifier. Since data from different subjects may show large variability, it is crucial to weight the contributions according to importance. Many multi-subject learning algorithms determine the optimal weighting in a separate step by using heuristics, however, without ensuring that the selected weights are optimal with respect to classification. In this work we apply Multiple Kernel Learning (MKL) to this problem. MKL has been widely used for feature fusion in computer vision and allows to simultaneously learn the classifier and the optimal weighting. We compare the MKL method to two baseline approaches and investigate the reasons for performance improvement.
* Corrected manuscript
Insights from Classifying Visual Concepts with Multiple Kernel Learning
Dec 16, 2011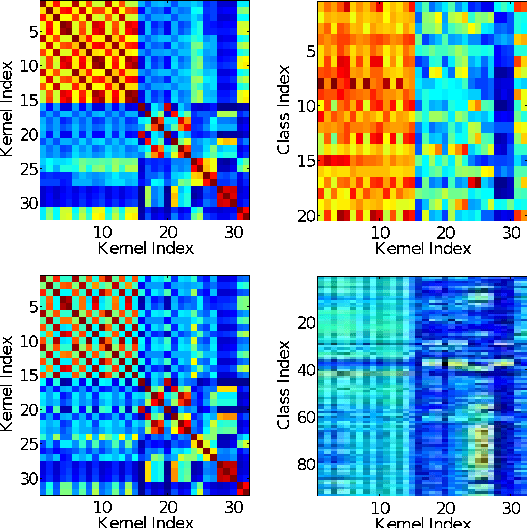
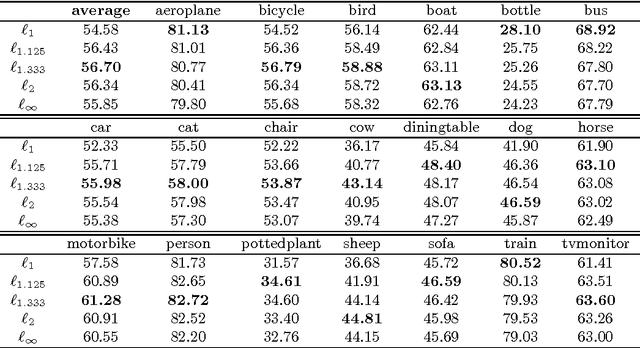
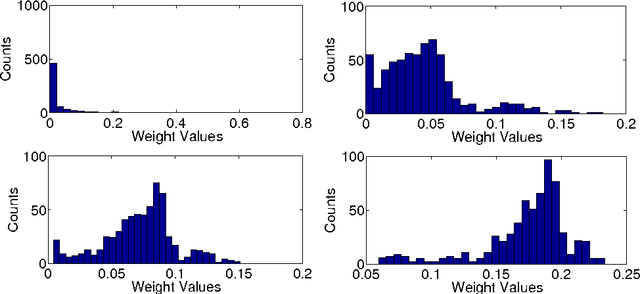
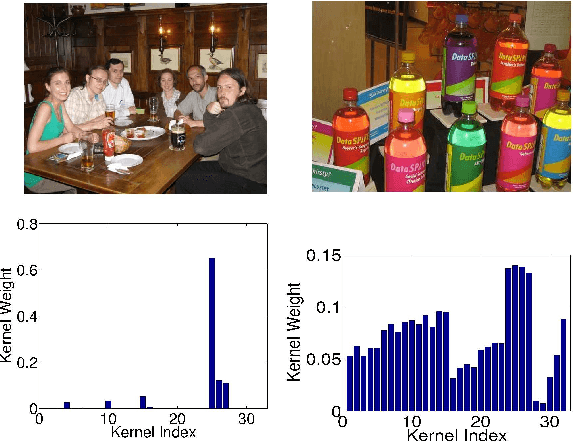
Combining information from various image features has become a standard technique in concept recognition tasks. However, the optimal way of fusing the resulting kernel functions is usually unknown in practical applications. Multiple kernel learning (MKL) techniques allow to determine an optimal linear combination of such similarity matrices. Classical approaches to MKL promote sparse mixtures. Unfortunately, so-called 1-norm MKL variants are often observed to be outperformed by an unweighted sum kernel. The contribution of this paper is twofold: We apply a recently developed non-sparse MKL variant to state-of-the-art concept recognition tasks within computer vision. We provide insights on benefits and limits of non-sparse MKL and compare it against its direct competitors, the sum kernel SVM and the sparse MKL. We report empirical results for the PASCAL VOC 2009 Classification and ImageCLEF2010 Photo Annotation challenge data sets. About to be submitted to PLoS ONE.
* 18 pages, 8 tables, 4 figures, format deviating from plos one submission format requirements for aesthetic reasons