 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbulence in Focus: Benchmarking Scaling Behavior of 3D Volumetric Super-Resolution with BLASTNet 2.0 Data
Sep 26, 2023Analysis of compressible turbulent flows is essential for applications related to propulsion, energy generation, and the environment. Here, we present BLASTNet 2.0, a 2.2 TB network-of-datasets containing 744 full-domain samples from 34 high-fidelity direct numerical simulations, which addresses the current limited availability of 3D high-fidelity reacting and non-reacting compressible turbulent flow simulation data. With this data, we benchmark a total of 49 variations of five deep learning approaches for 3D super-resolution - which can be applied for improving scientific imaging, simulations, turbulence models, as well as in computer vision applications. We perform neural scaling analysis on these models to examine the performance of different machine learning (ML) approaches, including two scientific ML techniques. We demonstrate that (i) predictive performance can scale with model size and cost, (ii) architecture matters significantly, especially for smaller models, and (iii) the benefits of physics-based losses can persist with increasing model size. The outcomes of this benchmark study are anticipated to offer insights that can aid the design of 3D super-resolution models, especially for turbulence models, while this data is expected to foster ML methods for a broad range of flow physics applications. This data is publicly available with download links and browsing tools consolidated at https://blastnet.github.io.
Studying Large Language Model Generalization with Influence Functions
Aug 07, 2023



When trying to gain better visibility into a machine learning model in order to understand and mitigate the associated risks, a potentially valuable source of evidence is: which training examples most contribute to a given behavior? Influence functions aim to answer a counterfactual: how would the model's parameters (and hence its outputs) change if a given sequence were added to the training set? While influence functions have produced insights for small models, they are difficult to scale to large language models (LLMs) due to the difficulty of computing an inverse-Hessian-vector product (IHVP). We use the Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC) approximation to scale influence functions up to LLMs with up to 52 billion parameters. In our experiments, EK-FAC achieves similar accuracy to traditional influence function estimators despite the IHVP computation being orders of magnitude faster. We investigate two algorithmic techniques to reduce the cost of computing gradients of candidate training sequences: TF-IDF filtering and query batching. We use influence functions to investigate the generalization patterns of LLMs, including the sparsity of the influence patterns, increasing abstraction with scale, math and programming abilities, cross-lingual generalization, and role-playing behavior. Despite many apparently sophisticated forms of generalization, we identify a surprising limitation: influences decay to near-zero when the order of key phrases is flipped. Overall, influence functions give us a powerful new tool for studying the generalization properties of LLMs.
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Jun 28, 2023



Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
Operationalising the Definition of General Purpose AI Systems: Assessing Four Approaches
Jun 05, 2023The European Union's Artificial Intelligence (AI) Act is set to be a landmark legal instrument for regulating AI technology. While stakeholders have primarily focused on the governance of fixed purpose AI applications (also known as narrow AI), more attention is required to understand the nature of highly and broadly capable systems. As of the beginning of 2023, several definitions for General Purpose AI Systems (GPAIS) exist in relation to the AI Act, attempting to distinguish between systems with and without a fixed purpose. In this article, we operationalise these differences through the concept of "distinct tasks" and examine four approaches (quantity, performance, adaptability, and emergence) to determine whether an AI system should be classified as a GPAIS. We suggest that EU stakeholders use the four approaches as a starting point to discriminate between fixed-purpose and GPAIS.
BenchMD: A Benchmark for Modality-Agnostic Learning on Medical Images and Sensors
Apr 17, 2023



Medical data poses a daunting challenge for AI algorithms: it exists in many different modalities, experiences frequent distribution shifts, and suffers from a scarcity of examples and labels. Recent advances, including transformers and self-supervised learning, promise a more universal approach that can be applied flexibly across these diverse conditions. To measure and drive progress in this direction, we present BenchMD: a benchmark that tests how modality-agnostic methods, including architectures and training techniques (e.g. self-supervised learning, ImageNet pretraining), perform on a diverse array of clinically-relevant medical tasks. BenchMD combines 19 publicly available datasets for 7 medical modalities, including 1D sensor data, 2D images, and 3D volumetric scans. Our benchmark reflects real-world data constraints by evaluating methods across a range of dataset sizes, including challenging few-shot settings that incentivize the use of pretraining. Finally, we evaluate performance on out-of-distribution data collected at different hospitals than the training data, representing naturally-occurring distribution shifts that frequently degrade the performance of medical AI models. Our baseline results demonstrate that no modality-agnostic technique achieves strong performance across all modalities, leaving ample room for improvement on the benchmark. Code is released at https://github.com/rajpurkarlab/BenchMD .
Multispectral Self-Supervised Learning with Viewmaker Networks
Feb 11, 2023



Contrastive learning methods have been applied to a range of domains and modalities by training models to identify similar ``views'' of data points. However, specialized scientific modalities pose a challenge for this paradigm, as identifying good views for each scientific instrument is complex and time-intensive. In this paper, we focus on applying contrastive learning approaches to a variety of remote sensing datasets. We show that Viewmaker networks, a recently proposed method for generating views, are promising for producing views in this setting without requiring extensive domain knowledge and trial and error. We apply Viewmaker to four multispectral imaging problems, each with a different format, finding that Viewmaker can outperform cropping- and reflection-based methods for contrastive learning in every case when evaluated on downstream classification tasks. This provides additional evidence that domain-agnostic methods can empower contrastive learning to scale to real-world scientific domains. Open source code can be found at https://github.com/jbayrooti/divmaker.
Task Ambiguity in Humans and Language Models
Dec 20, 2022



Language models have recently achieved strong performance across a wide range of NLP benchmarks. However, unlike benchmarks, real world tasks are often poorly specified, and agents must deduce the user's intended behavior from a combination of context, instructions, and examples. We investigate how both humans and models behave in the face of such task ambiguity by proposing AmbiBench, a new benchmark of six ambiguously-specified classification tasks. We evaluate humans and models on AmbiBench by seeing how well they identify the intended task using 1) instructions with varying degrees of ambiguity, and 2) different numbers of labeled examples. We find that the combination of model scaling (to 175B parameters) and training with human feedback data enables models to approach or exceed the accuracy of human participants across tasks, but that either one alone is not sufficient. In addition, we show how to dramatically improve the accuracy of language models trained without large-scale human feedback training by finetuning on a small number of ambiguous in-context examples, providing a promising direction for teaching models to generalize well in the face of ambiguity.
Feature Dropout: Revisiting the Role of Augmentations in Contrastive Learning
Dec 16, 2022



What role do augmentations play in contrastive learning? Recent work suggests that good augmentations are label-preserving with respect to a specific downstream task. We complicate this picture by showing that label-destroying augmentations can be useful in the foundation model setting, where the goal is to learn diverse, general-purpose representations for multiple downstream tasks. We perform contrastive learning experiments on a range of image and audio datasets with multiple downstream tasks (e.g. for digits superimposed on photographs, predicting the class of one vs. the other). We find that Viewmaker Networks, a recently proposed model for learning augmentations for contrastive learning, produce label-destroying augmentations that stochastically destroy features needed for different downstream tasks. These augmentations are interpretable (e.g. altering shapes, digits, or letters added to images) and surprisingly often result in better performance compared to expert-designed augmentations, despite not preserving label information. To support our empirical results, we theoretically analyze a simple contrastive learning setting with a linear model. In this setting, label-destroying augmentations are crucial for preventing one set of features from suppressing the learning of features useful for another downstream task. Our results highlight the need for analyzing the interaction between multiple downstream tasks when trying to explain the success of foundation models.
Active Learning Helps Pretrained Models Learn the Intended Task
Apr 18, 2022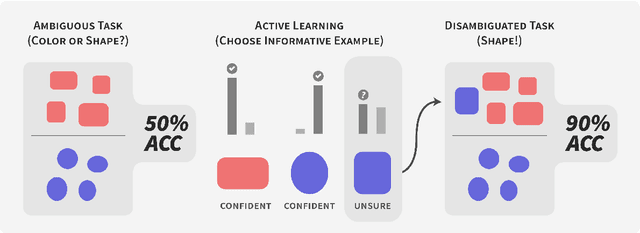
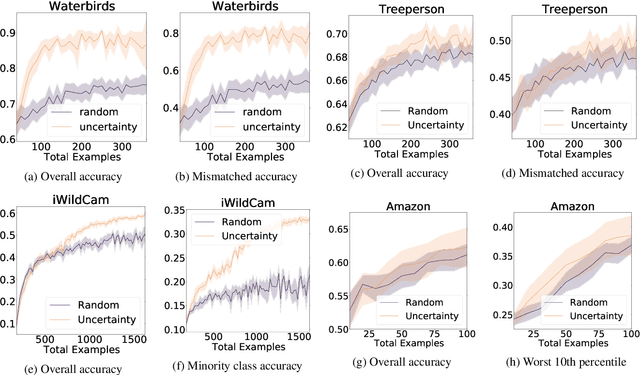
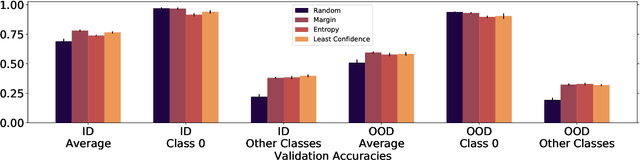
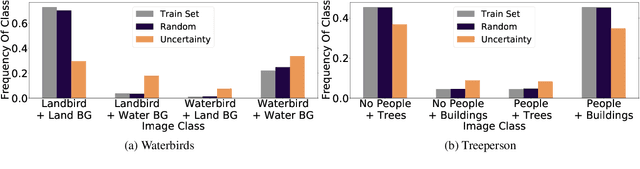
Models can fail in unpredictable ways during deployment due to task ambiguity, when multiple behaviors are consistent with the provided training data. An example is an object classifier trained on red squares and blue circles: when encountering blue squares, the intended behavior is undefined. We investigate whether pretrained models are better active learners, capable of disambiguating between the possible tasks a user may be trying to specify. Intriguingly, we find that better active learning is an emergent property of the pretraining process: pretrained models require up to 5 times fewer labels when using uncertainty-based active learning, while non-pretrained models see no or even negative benefit. We find these gains come from an ability to select examples with attributes that disambiguate the intended behavior, such as rare product categories or atypical backgrounds. These attributes are far more linearly separable in pretrained model's representation spaces vs non-pretrained models, suggesting a possible mechanism for this behavior.
Oolong: Investigating What Makes Crosslingual Transfer Hard with Controlled Studies
Feb 24, 2022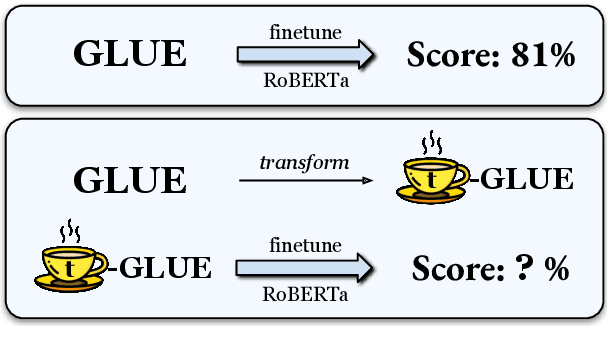

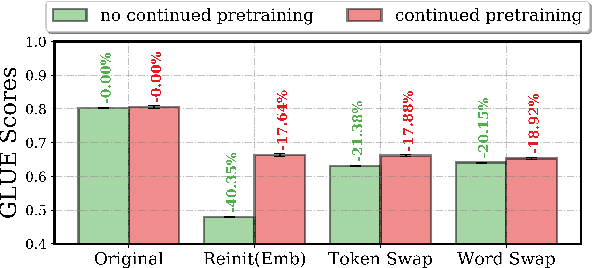
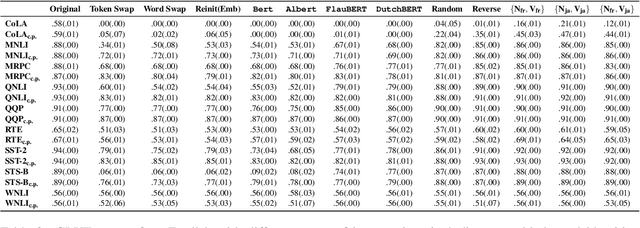
Little is known about what makes cross-lingual transfer hard, since factors like tokenization, morphology, and syntax all change at once between languages. To disentangle the impact of these factors, we propose a set of controlled transfer studies: we systematically transform GLUE tasks to alter different factors one at a time, then measure the resulting drops in a pretrained model's downstream performance. In contrast to prior work suggesting little effect from syntax on knowledge transfer, we find significant impacts from syntactic shifts (3-6% drop), though models quickly adapt with continued pretraining on a small dataset. However, we find that by far the most impactful factor for crosslingual transfer is the challenge of aligning the new embeddings with the existing transformer layers (18% drop), with little additional effect from switching tokenizers (<2% drop) or word morphologies (<2% drop). Moreover, continued pretraining with a small dataset is not very effective at closing this gap - suggesting that new directions are needed for solving this problem.