 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic transfer learning methodology to expedite high fidelity simulation of reactive flows
May 17, 2024



Reduced order models based on the transport of a lower dimensional manifold representation of the thermochemical state, such as Principal Component (PC) transport and Machine Learning (ML) techniques, have been developed to reduce the computational cost associated with the Direct Numerical Simulations (DNS) of reactive flows. Both PC transport and ML normally require an abundance of data to exhibit sufficient predictive accuracy, which might not be available due to the prohibitive cost of DNS or experimental data acquisition. To alleviate such difficulties, similar data from an existing dataset or domain (source domain) can be used to train ML models, potentially resulting in adequate predictions in the domain of interest (target domain). This study presents a novel probabilistic transfer learning (TL) framework to enhance the trust in ML models in correctly predicting the thermochemical state in a lower dimensional manifold and a sparse data setting. The framework uses Bayesian neural networks, and autoencoders, to reduce the dimensionality of the state space and diffuse the knowledge from the source to the target domain. The new framework is applied to one-dimensional freely-propagating flame solutions under different data sparsity scenarios. The results reveal that there is an optimal amount of knowledge to be transferred, which depends on the amount of data available in the target domain and the similarity between the domains. TL can reduce the reconstruction error by one order of magnitude for cases with large sparsity. The new framework required 10 times less data for the target domain to reproduce the same error as in the abundant data scenario. Furthermore, comparisons with a state-of-the-art deterministic TL strategy show that the probabilistic method can require four times less data to achieve the same reconstruction error.
Transfer learning for predicting source terms of principal component transport in chemically reactive flow
Dec 01, 2023The objective of this study is to evaluate whether the number of requisite training samples can be reduced with the use of various transfer learning models for predicting, for example, the chemical source terms of the data-driven reduced-order model that represents the homogeneous ignition process of a hydrogen/air mixture. Principal component analysis is applied to reduce the dimensionality of the hydrogen/air mixture in composition space. Artificial neural networks (ANNs) are used to tabulate the reaction rates of principal components, and subsequently, a system of ordinary differential equations is solved. As the number of training samples decreases at the target task (i.e.,for T0 > 1000 K and various phi), the reduced-order model fails to predict the ignition evolution of a hydrogen/air mixture. Three transfer learning strategies are then applied to the training of the ANN model with a sparse dataset. The performance of the reduced-order model with a sparse dataset is found to be remarkably enhanced if the training of the ANN model is restricted by a regularization term that controls the degree of knowledge transfer from source to target tasks. To this end, a novel transfer learning method is introduced, parameter control via partial initialization and regularization (PaPIR), whereby the amount of knowledge transferred is systemically adjusted for the initialization and regularization of the ANN model in the target task. It is found that an additional performance gain can be achieved by changing the initialization scheme of the ANN model in the target task when the task similarity between source and target tasks is relatively low.
Turbulence in Focus: Benchmarking Scaling Behavior of 3D Volumetric Super-Resolution with BLASTNet 2.0 Data
Sep 26, 2023Analysis of compressible turbulent flows is essential for applications related to propulsion, energy generation, and the environment. Here, we present BLASTNet 2.0, a 2.2 TB network-of-datasets containing 744 full-domain samples from 34 high-fidelity direct numerical simulations, which addresses the current limited availability of 3D high-fidelity reacting and non-reacting compressible turbulent flow simulation data. With this data, we benchmark a total of 49 variations of five deep learning approaches for 3D super-resolution - which can be applied for improving scientific imaging, simulations, turbulence models, as well as in computer vision applications. We perform neural scaling analysis on these models to examine the performance of different machine learning (ML) approaches, including two scientific ML techniques. We demonstrate that (i) predictive performance can scale with model size and cost, (ii) architecture matters significantly, especially for smaller models, and (iii) the benefits of physics-based losses can persist with increasing model size. The outcomes of this benchmark study are anticipated to offer insights that can aid the design of 3D super-resolution models, especially for turbulence models, while this data is expected to foster ML methods for a broad range of flow physics applications. This data is publicly available with download links and browsing tools consolidated at https://blastnet.github.io.
The Bearable Lightness of Big Data: Towards Massive Public Datasets in Scientific Machine Learning
Jul 25, 2022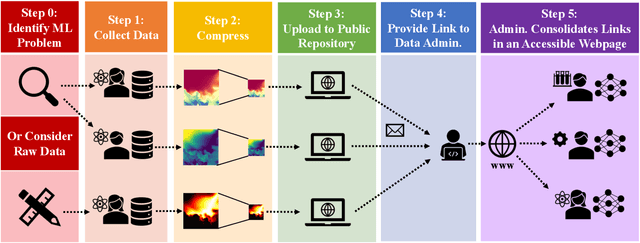
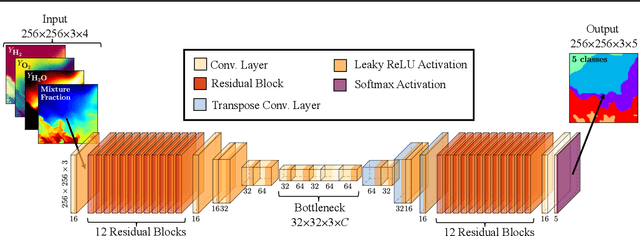
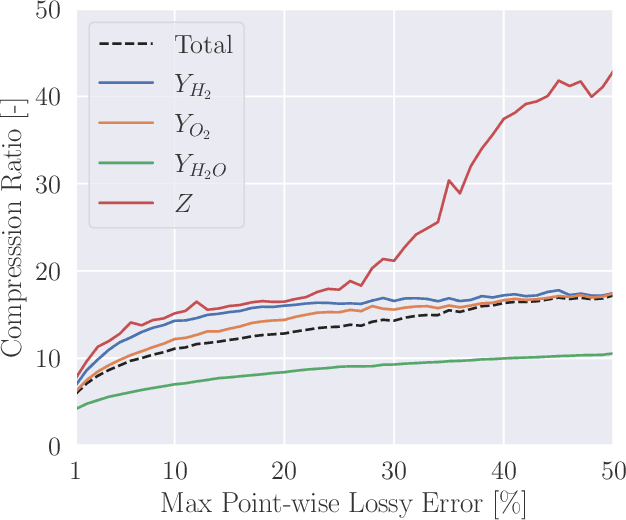

In general, large datasets enable deep learning models to perform with good accuracy and generalizability. However, massive high-fidelity simulation datasets (from molecular chemistry, astrophysics, computational fluid dynamics (CFD), etc. can be challenging to curate due to dimensionality and storage constraints. Lossy compression algorithms can help mitigate limitations from storage, as long as the overall data fidelity is preserved. To illustrate this point, we demonstrate that deep learning models, trained and tested on data from a petascale CFD simulation, are robust to errors introduced during lossy compression in a semantic segmentation problem. Our results demonstrate that lossy compression algorithms offer a realistic pathway for exposing high-fidelity scientific data to open-source data repositories for building community datasets. In this paper, we outline, construct, and evaluate the requirements for establishing a big data framework, demonstrated at https://blastnet.github.io/, for scientific machine learning.
* Accepted in ICML 2022 2nd AI for Science Workshop. 10 pages, 8 figures