 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGensors: Authoring Personalized Visual Sensors with Multimodal Foundation Models and Reasoning
Jan 27, 2025



Multimodal large language models (MLLMs), with their expansive world knowledge and reasoning capabilities, present a unique opportunity for end-users to create personalized AI sensors capable of reasoning about complex situations. A user could describe a desired sensing task in natural language (e.g., "alert if my toddler is getting into mischief"), with the MLLM analyzing the camera feed and responding within seconds. In a formative study, we found that users saw substantial value in defining their own sensors, yet struggled to articulate their unique personal requirements and debug the sensors through prompting alone. To address these challenges, we developed Gensors, a system that empowers users to define customized sensors supported by the reasoning capabilities of MLLMs. Gensors 1) assists users in eliciting requirements through both automatically-generated and manually created sensor criteria, 2) facilitates debugging by allowing users to isolate and test individual criteria in parallel, 3) suggests additional criteria based on user-provided images, and 4) proposes test cases to help users "stress test" sensors on potentially unforeseen scenarios. In a user study, participants reported significantly greater sense of control, understanding, and ease of communication when defining sensors using Gensors. Beyond addressing model limitations, Gensors supported users in debugging, eliciting requirements, and expressing unique personal requirements to the sensor through criteria-based reasoning; it also helped uncover users' "blind spots" by exposing overlooked criteria and revealing unanticipated failure modes. Finally, we discuss how unique characteristics of MLLMs--such as hallucinations and inconsistent responses--can impact the sensor-creation process. These findings contribute to the design of future intelligent sensing systems that are intuitive and customizable by everyday users.
Thing2Reality: Transforming 2D Content into Conditioned Multiviews and 3D Gaussian Objects for XR Communication
Oct 09, 2024



During remote communication, participants often share both digital and physical content, such as product designs, digital assets, and environments, to enhance mutual understanding. Recent advances in augmented communication have facilitated users to swiftly create and share digital 2D copies of physical objects from video feeds into a shared space. However, conventional 2D representations of digital objects restricts users' ability to spatially reference items in a shared immersive environment. To address this, we propose Thing2Reality, an Extended Reality (XR) communication platform that enhances spontaneous discussions of both digital and physical items during remote sessions. With Thing2Reality, users can quickly materialize ideas or physical objects in immersive environments and share them as conditioned multiview renderings or 3D Gaussians. Thing2Reality enables users to interact with remote objects or discuss concepts in a collaborative manner. Our user study revealed that the ability to interact with and manipulate 3D representations of objects significantly enhances the efficiency of discussions, with the potential to augment discussion of 2D artifacts.
InstructPipe: Building Visual Programming Pipelines with Human Instructions
Dec 15, 2023



Visual programming provides beginner-level programmers with a coding-free experience to build their customized pipelines. Existing systems require users to build a pipeline entirely from scratch, implying that novice users need to set up and link appropriate nodes all by themselves, starting from a blank workspace. We present InstructPipe, an AI assistant that enables users to start prototyping machine learning (ML) pipelines with text instructions. We designed two LLM modules and a code interpreter to execute our solution. LLM modules generate pseudocode of a target pipeline, and the interpreter renders a pipeline in the node-graph editor for further human-AI collaboration. Technical evaluations reveal that InstructPipe reduces user interactions by 81.1% compared to traditional methods. Our user study (N=16) showed that InstructPipe empowers novice users to streamline their workflow in creating desired ML pipelines, reduce their learning curve, and spark innovative ideas with open-ended commands.
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Feb 22, 2022

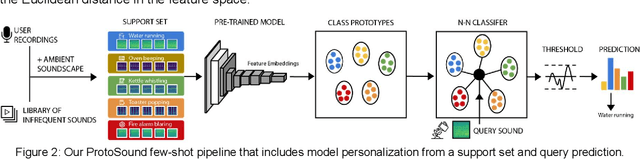
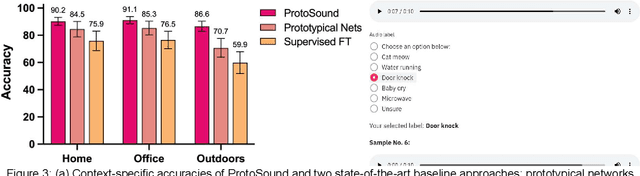
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.