 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Vs. MLP-Mixer Exponential Expressive Gap For NLP Problems
Aug 17, 2022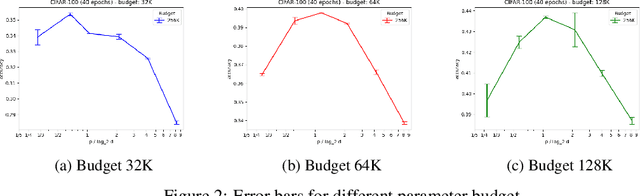
Vision-Transformers are widely used in various vision tasks. Meanwhile, there is another line of works starting with the MLP-mixer trying to achieve similar performance using mlp-based architectures. Interestingly, until now none reported using them for NLP tasks, additionally until now non of those mlp-based architectures claimed to achieve state-of-the-art in vision tasks. In this paper, we analyze the expressive power of mlp-based architectures in modeling dependencies between multiple different inputs simultaneously, and show an exponential gap between the attention and the mlp-based mechanisms. Our results suggest a theoretical explanation for the mlp inability to compete with attention-based mechanisms in NLP problems, they also suggest that the performance gap in vision tasks may be due to the mlp relative weakness in modeling dependencies between multiple different locations, and that combining smart input permutations to the mlp architectures may not suffice alone to close the performance gap.
Random Search Hyper-Parameter Tuning: Expected Improvement Estimation and the Corresponding Lower Bound
Aug 17, 2022Hyperparameter tuning is a common technique for improving the performance of neural networks. Most techniques for hyperparameter search involve an iterated process where the model is retrained at every iteration. However, the expected accuracy improvement from every additional search iteration, is still unknown. Calculating the expected improvement can help create stopping rules for hyperparameter tuning and allow for a wiser allocation of a project's computational budget. In this paper, we establish an empirical estimate for the expected accuracy improvement from an additional iteration of hyperparameter search. Our results hold for any hyperparameter tuning method which is based on random search \cite{bergstra2012random} and samples hyperparameters from a fixed distribution. We bound our estimate with an error of $O\left(\sqrt{\frac{\log k}{k}}\right)$ w.h.p. where $k$ is the current number of iterations. To the best of our knowledge this is the first bound on the expected gain from an additional iteration of hyperparameter search. Finally, we demonstrate that the optimal estimate for the expected accuracy will still have an error of $\frac{1}{k}$.
Physical Passive Patch Adversarial Attacks on Visual Odometry Systems
Jul 11, 2022
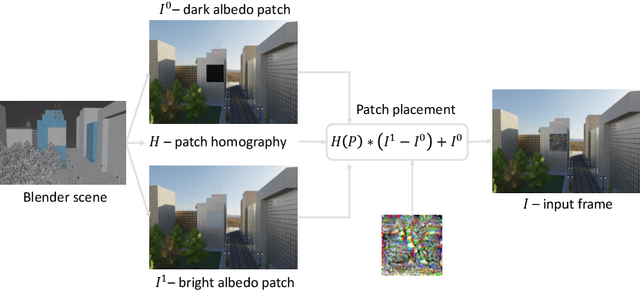

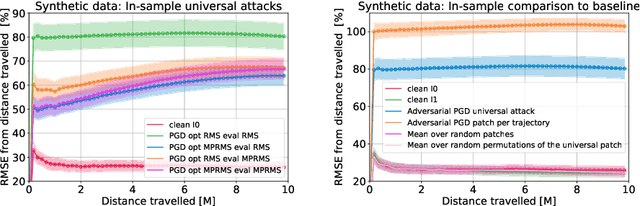
Deep neural networks are known to be susceptible to adversarial perturbations -- small perturbations that alter the output of the network and exist under strict norm limitations. While such perturbations are usually discussed as tailored to a specific input, a universal perturbation can be constructed to alter the model's output on a set of inputs. Universal perturbations present a more realistic case of adversarial attacks, as awareness of the model's exact input is not required. In addition, the universal attack setting raises the subject of generalization to unseen data, where given a set of inputs, the universal perturbations aim to alter the model's output on out-of-sample data. In this work, we study physical passive patch adversarial attacks on visual odometry-based autonomous navigation systems. A visual odometry system aims to infer the relative camera motion between two corresponding viewpoints, and is frequently used by vision-based autonomous navigation systems to estimate their state. For such navigation systems, a patch adversarial perturbation poses a severe security issue, as it can be used to mislead a system onto some collision course. To the best of our knowledge, we show for the first time that the error margin of a visual odometry model can be significantly increased by deploying patch adversarial attacks in the scene. We provide evaluation on synthetic closed-loop drone navigation data and demonstrate that a comparable vulnerability exists in real data. A reference implementation of the proposed method and the reported experiments is provided at https://github.com/patchadversarialattacks/patchadversarialattacks.
Fast Nonlinear Vector Quantile Regression
May 30, 2022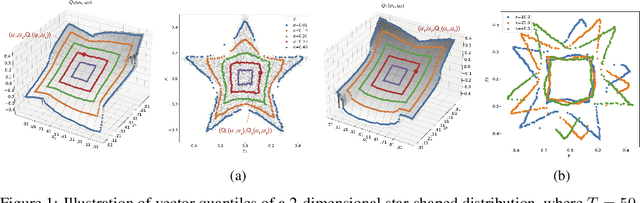

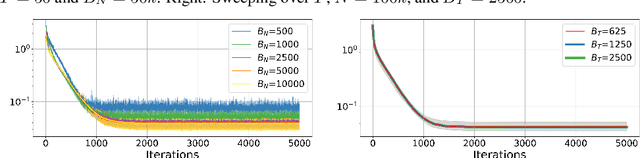

Quantile regression (QR) is a powerful tool for estimating one or more conditional quantiles of a target variable $\mathrm{Y}$ given explanatory features $\boldsymbol{\mathrm{X}}$. A limitation of QR is that it is only defined for scalar target variables, due to the formulation of its objective function, and since the notion of quantiles has no standard definition for multivariate distributions. Recently, vector quantile regression (VQR) was proposed as an extension of QR for high-dimensional target variables, thanks to a meaningful generalization of the notion of quantiles to multivariate distributions. Despite its elegance, VQR is arguably not applicable in practice due to several limitations: (i) it assumes a linear model for the quantiles of the target $\mathrm{Y}$ given the features $\boldsymbol{\mathrm{X}}$; (ii) its exact formulation is intractable even for modestly-sized problems in terms of target dimensions, number of regressed quantile levels, or number of features, and its relaxed dual formulation may violate the monotonicity of the estimated quantiles; (iii) no fast or scalable solvers for VQR currently exist. In this work we fully address these limitations, namely: (i) We extend VQR to the non-linear case, showing substantial improvement over linear VQR; (ii) We propose vector monotone rearrangement, a method which ensures the estimates obtained by VQR relaxations are monotone functions; (iii) We provide fast, GPU-accelerated solvers for linear and nonlinear VQR which maintain a fixed memory footprint with number of samples and quantile levels, and demonstrate that they scale to millions of samples and thousands of quantile levels; (iv) We release an optimized python package of our solvers as to widespread the use of VQR in real-world applications.
Towards Predicting Fine Finger Motions from Ultrasound Images via Kinematic Representation
Feb 10, 2022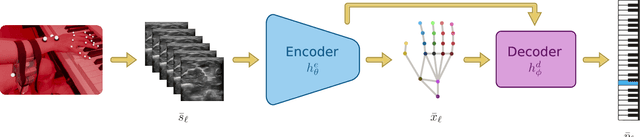
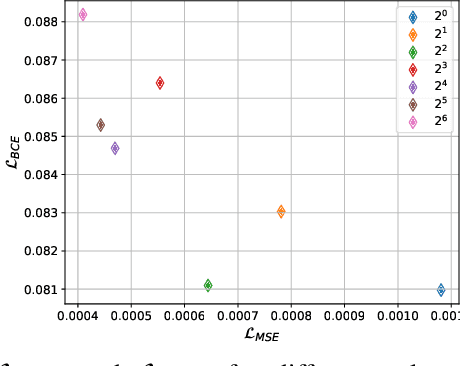

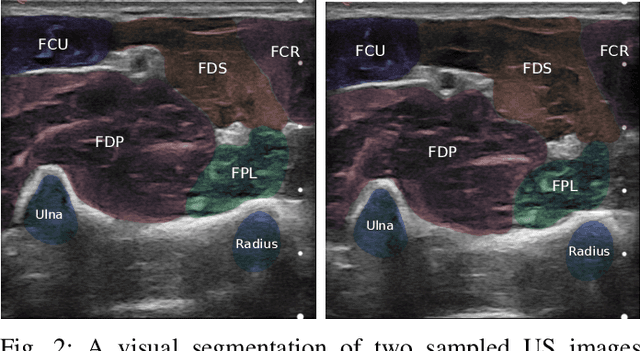
A central challenge in building robotic prostheses is the creation of a sensor-based system able to read physiological signals from the lower limb and instruct a robotic hand to perform various tasks. Existing systems typically perform discrete gestures such as pointing or grasping, by employing electromyography (EMG) or ultrasound (US) technologies to analyze the state of the muscles. In this work, we study the inference problem of identifying the activation of specific fingers from a sequence of US images when performing dexterous tasks such as keyboard typing or playing the piano. While estimating finger gestures has been done in the past by detecting prominent gestures, we are interested in classification done in the context of fine motions that evolve over time. We consider this task as an important step towards higher adoption rates of robotic prostheses among arm amputees, as it has the potential to dramatically increase functionality in performing daily tasks. Our key observation, motivating this work, is that modeling the hand as a robotic manipulator allows to encode an intermediate representation wherein US images are mapped to said configurations. Given a sequence of such learned configurations, coupled with a neural-network architecture that exploits temporal coherence, we are able to infer fine finger motions. We evaluated our method by collecting data from a group of subjects and demonstrating how our framework can be used to replay music played or text typed. To the best of our knowledge, this is the first study demonstrating these downstream tasks within an end-to-end system.
SPDCinv: Inverse Quantum-Optical Design of High-Dimensional Qudits
Dec 11, 2021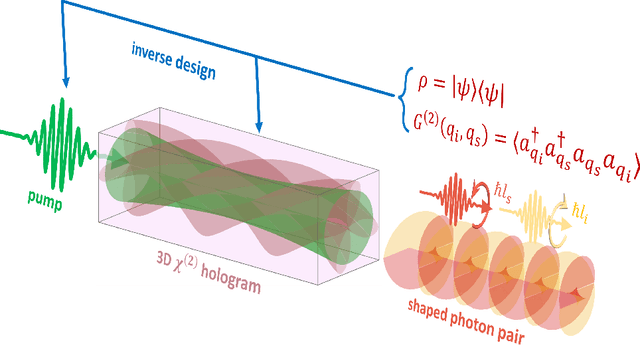
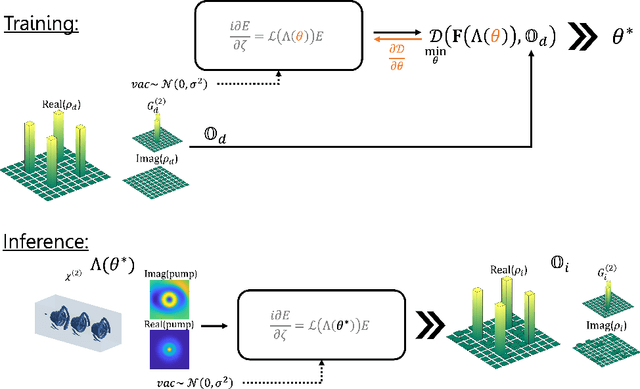
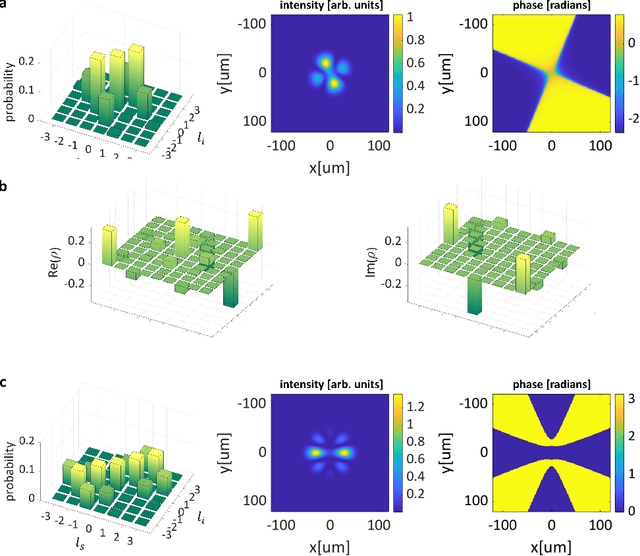
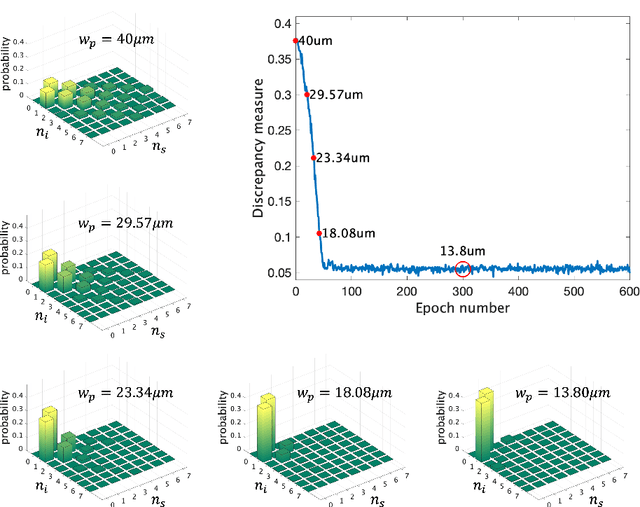
Spontaneous parametric down-conversion in quantum optics is an invaluable resource for the realization of high-dimensional qudits with spatial modes of light. One of the main open challenges is how to directly generate a desirable qudit state in the SPDC process. This problem can be addressed through advanced computational learning methods; however, due to difficulties in modeling the SPDC process by a fully differentiable algorithm that takes into account all interaction effects, progress has been limited. Here, we overcome these limitations and introduce a physically-constrained and differentiable model, validated against experimental results for shaped pump beams and structured crystals, capable of learning every interaction parameter in the process. We avoid any restrictions induced by the stochastic nature of our physical model and integrate the dynamic equations governing the evolution under the SPDC Hamiltonian. We solve the inverse problem of designing a nonlinear quantum optical system that achieves the desired quantum state of down-converted photon pairs. The desired states are defined using either the second-order correlations between different spatial modes or by specifying the required density matrix. By learning nonlinear volume holograms as well as different pump shapes, we successfully show how to generate maximally entangled states. Furthermore, we simulate all-optical coherent control over the generated quantum state by actively changing the profile of the pump beam. Our work can be useful for applications such as novel designs of high-dimensional quantum key distribution and quantum information processing protocols. In addition, our method can be readily applied for controlling other degrees of freedom of light in the SPDC process, such as the spectral and temporal properties, and may even be used in condensed-matter systems having a similar interaction Hamiltonian.
Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels
Mar 25, 2021
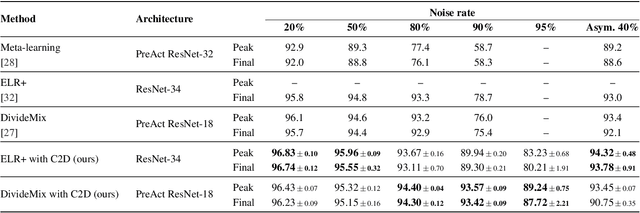
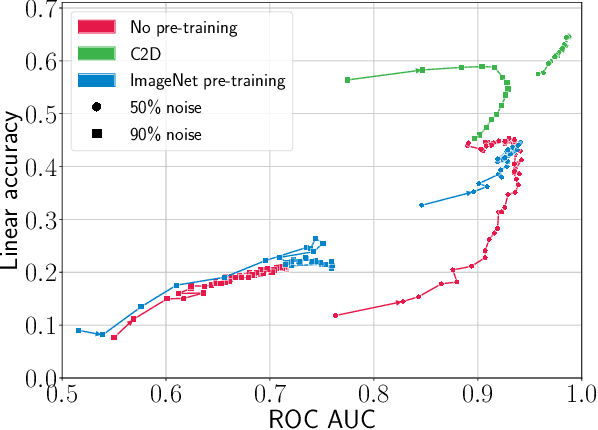
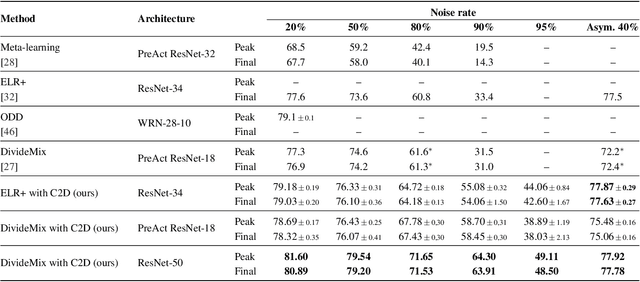
The success of learning with noisy labels (LNL) methods relies heavily on the success of a warm-up stage where standard supervised training is performed using the full (noisy) training set. In this paper, we identify a "warm-up obstacle": the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels. We propose "Contrast to Divide" (C2D), a simple framework that solves this problem by pre-training the feature extractor in a self-supervised fashion. Using self-supervised pre-training boosts the performance of existing LNL approaches by drastically reducing the warm-up stage's susceptibility to noise level, shortening its duration, and increasing extracted feature quality. C2D works out of the box with existing methods and demonstrates markedly improved performance, especially in the high noise regime, where we get a boost of more than 27% for CIFAR-100 with 90% noise over the previous state of the art. In real-life noise settings, C2D trained on mini-WebVision outperforms previous works both in WebVision and ImageNet validation sets by 3% top-1 accuracy. We perform an in-depth analysis of the framework, including investigating the performance of different pre-training approaches and estimating the effective upper bound of the LNL performance with semi-supervised learning. Code for reproducing our experiments is available at https://github.com/ContrastToDivide/C2D
Inverse Design of Quantum Holograms in Three-Dimensional Nonlinear Photonic Crystals
Feb 20, 2021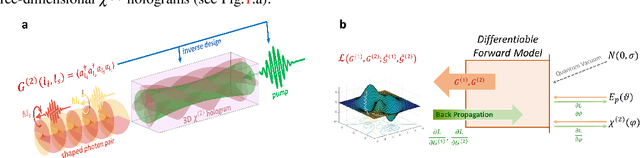
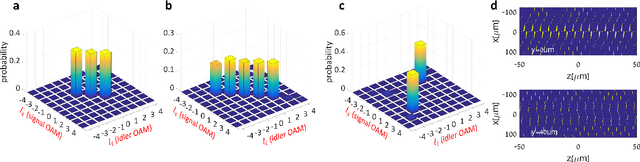
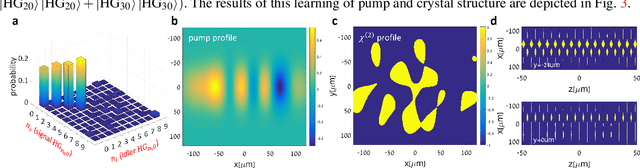
We introduce a systematic approach for designing 3D nonlinear photonic crystals and pump beams for generating desired quantum correlations between structured photon-pairs. Our model is fully differentiable, allowing accurate and efficient learning and discovery of novel designs.
SimuGAN: Unsupervised forward modeling and optimal design of a LIDAR Camera
Dec 16, 2020
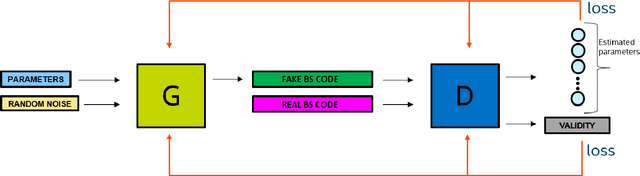
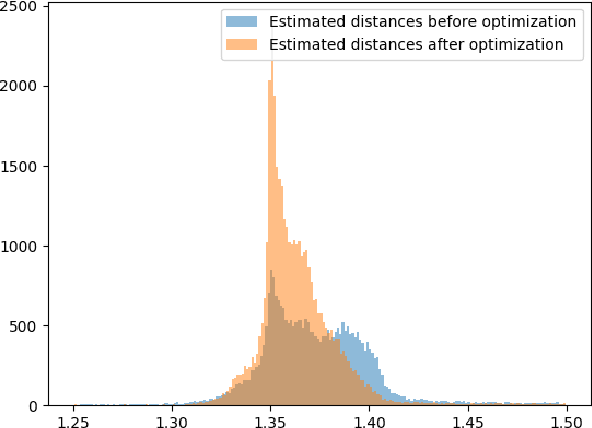
Energy-saving LIDAR camera for short distances estimates an object's distance using temporally intensity-coded laser light pulses and calculates the maximum correlation with the back-scattered pulse. Though on low power, the backs-scattered pulse is noisy and unstable, which leads to inaccurate and unreliable depth estimation. To address this problem, we use GANs (Generative Adversarial Networks), which are two neural networks that can learn complicated class distributions through an adversarial process. We learn the LIDAR camera's hidden properties and behavior, creating a novel, fully unsupervised forward model that simulates the camera. Then, we use the model's differentiability to explore the camera parameter space and optimize those parameters in terms of depth, accuracy, and stability. To achieve this goal, we also propose a new custom loss function designated to the back-scattered code distribution's weaknesses and its circular behavior. The results are demonstrated on both synthetic and real data.
Digital Gimbal: End-to-end Deep Image Stabilization with Learnable Exposure Times
Dec 08, 2020

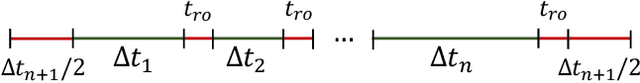
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work, we propose to digitally emulate a mechanically stabilized system from the input of a fast unstabilized camera. To exploit the trade-off between motion blur at long exposures and low SNR at short exposures, we train a CNN that estimates a sharp high-SNR image by aggregating a burst of noisy short-exposure frames, related by unknown motion. We further suggest learning the burst's exposure times in an end-to-end manner, thus balancing the noise and blur across the frames. We demonstrate this method's advantage over the traditional approach of deblurring a single image or denoising a fixed-exposure burst.