 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Browsing: Controllable Diversity for Image Generation
Jun 22, 2026Modern text-to-image models excel in visual fidelity and prompt adherence. However, this strict adherence comes at the cost of diversity: generated samples tend to collapse into a single visual interpretation. Existing methods to improve diversity produce outputs driven by incidental variations rather than meaningful design choices. This motivates a new variant of the diversity task where structure is enforced on the generated samples. We introduce a method for controlled diversity that enables Semantic Browsing, where users can navigate structured image galleries and experience creative exploration through a systematic traversal of meaningful, interpretable axes of variation. Achieving this level of semantic control requires a deep understanding of the scene. We exploit the fact that recent text-to-image models are trained on elaborated captions, effectively decoupling semantic decision-making from pixel generation. This enables a paradigm shift: instead of relying on stochastic variation within the text-to-image model, we induce diversity directly at the text level. By leveraging rich textual representations, we allow a Vision Language Model (VLM) to operate on the full scene context. To overcome the generic outputs typical of standard VLMs, we employ an agentic workflow that explicitly enforces structured variation attuned to the original prompt. We demonstrate that our method produces diverse and navigable design spaces where every variation corresponds to a specific, user-understandable semantic decision.
On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers
Mar 30, 2026Modern Text-to-Image (T2I) diffusion models have achieved remarkable semantic alignment, yet they often suffer from a significant lack of variety, converging on a narrow set of visual solutions for any given prompt. This typicality bias presents a challenge for creative applications that require a wide range of generative outcomes. We identify a fundamental trade-off in current approaches to diversity: modifying model inputs requires costly optimization to incorporate feedback from the generative path. In contrast, acting on spatially-committed intermediate latents tends to disrupt the forming visual structure, leading to artifacts. In this work, we propose to apply repulsion in the Contextual Space as a novel framework for achieving rich diversity in Diffusion Transformers. By intervening in the multimodal attention channels, we apply on-the-fly repulsion during the transformer's forward pass, injecting the intervention between blocks where text conditioning is enriched with emergent image structure. This allows for redirecting the guidance trajectory after it is structurally informed but before the composition is fixed. Our results demonstrate that repulsion in the Contextual Space produces significantly richer diversity without sacrificing visual fidelity or semantic adherence. Furthermore, our method is uniquely efficient, imposing a small computational overhead while remaining effective even in modern "Turbo" and distilled models where traditional trajectory-based interventions typically fail.
Visual Diffusion Models are Geometric Solvers
Oct 24, 2025In this paper we show that visual diffusion models can serve as effective geometric solvers: they can directly reason about geometric problems by working in pixel space. We first demonstrate this on the Inscribed Square Problem, a long-standing problem in geometry that asks whether every Jordan curve contains four points forming a square. We then extend the approach to two other well-known hard geometric problems: the Steiner Tree Problem and the Simple Polygon Problem. Our method treats each problem instance as an image and trains a standard visual diffusion model that transforms Gaussian noise into an image representing a valid approximate solution that closely matches the exact one. The model learns to transform noisy geometric structures into correct configurations, effectively recasting geometric reasoning as image generation. Unlike prior work that necessitates specialized architectures and domain-specific adaptations when applying diffusion to parametric geometric representations, we employ a standard visual diffusion model that operates on the visual representation of the problem. This simplicity highlights a surprising bridge between generative modeling and geometric problem solving. Beyond the specific problems studied here, our results point toward a broader paradigm: operating in image space provides a general and practical framework for approximating notoriously hard problems, and opens the door to tackling a far wider class of challenging geometric tasks.
Be Decisive: Noise-Induced Layouts for Multi-Subject Generation
May 27, 2025Generating multiple distinct subjects remains a challenge for existing text-to-image diffusion models. Complex prompts often lead to subject leakage, causing inaccuracies in quantities, attributes, and visual features. Preventing leakage among subjects necessitates knowledge of each subject's spatial location. Recent methods provide these spatial locations via an external layout control. However, enforcing such a prescribed layout often conflicts with the innate layout dictated by the sampled initial noise, leading to misalignment with the model's prior. In this work, we introduce a new approach that predicts a spatial layout aligned with the prompt, derived from the initial noise, and refines it throughout the denoising process. By relying on this noise-induced layout, we avoid conflicts with externally imposed layouts and better preserve the model's prior. Our method employs a small neural network to predict and refine the evolving noise-induced layout at each denoising step, ensuring clear boundaries between subjects while maintaining consistency. Experimental results show that this noise-aligned strategy achieves improved text-image alignment and more stable multi-subject generation compared to existing layout-guided techniques, while preserving the rich diversity of the model's original distribution.
Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation
Mar 25, 2024



Text-to-image diffusion models have an unprecedented ability to generate diverse and high-quality images. However, they often struggle to faithfully capture the intended semantics of complex input prompts that include multiple subjects. Recently, numerous layout-to-image extensions have been introduced to improve user control, aiming to localize subjects represented by specific tokens. Yet, these methods often produce semantically inaccurate images, especially when dealing with multiple semantically or visually similar subjects. In this work, we study and analyze the causes of these limitations. Our exploration reveals that the primary issue stems from inadvertent semantic leakage between subjects in the denoising process. This leakage is attributed to the diffusion model's attention layers, which tend to blend the visual features of different subjects. To address these issues, we introduce Bounded Attention, a training-free method for bounding the information flow in the sampling process. Bounded Attention prevents detrimental leakage among subjects and enables guiding the generation to promote each subject's individuality, even with complex multi-subject conditioning. Through extensive experimentation, we demonstrate that our method empowers the generation of multiple subjects that better align with given prompts and layouts.
Digital Gimbal: End-to-end Deep Image Stabilization with Learnable Exposure Times
Dec 08, 2020
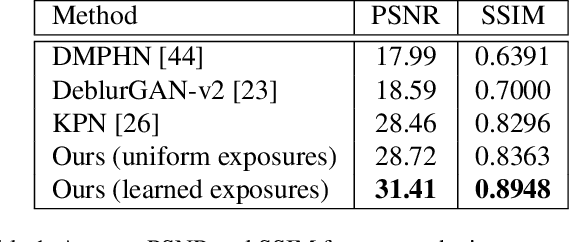

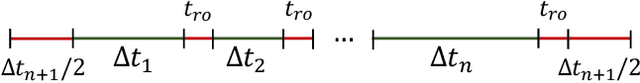
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work, we propose to digitally emulate a mechanically stabilized system from the input of a fast unstabilized camera. To exploit the trade-off between motion blur at long exposures and low SNR at short exposures, we train a CNN that estimates a sharp high-SNR image by aggregating a burst of noisy short-exposure frames, related by unknown motion. We further suggest learning the burst's exposure times in an end-to-end manner, thus balancing the noise and blur across the frames. We demonstrate this method's advantage over the traditional approach of deblurring a single image or denoising a fixed-exposure burst.