 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asymptotically Optimal Primal-Dual Incremental Algorithm for Contextual Linear Bandits
Oct 23, 2020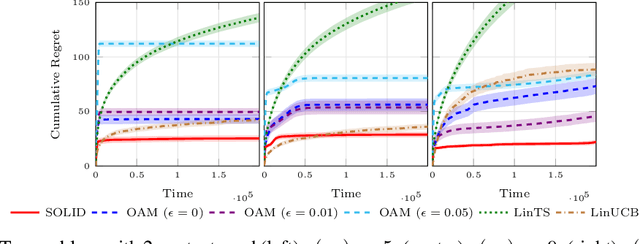

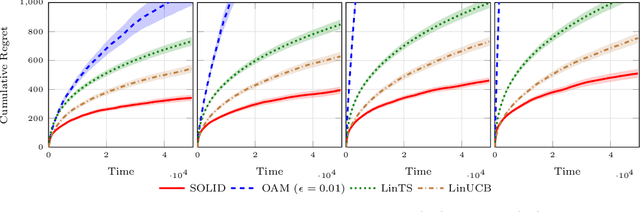
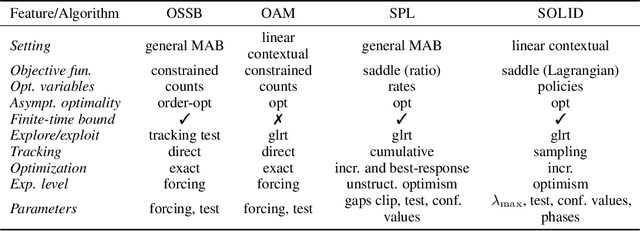
In the contextual linear bandit setting, algorithms built on the optimism principle fail to exploit the structure of the problem and have been shown to be asymptotically suboptimal. In this paper, we follow recent approaches of deriving asymptotically optimal algorithms from problem-dependent regret lower bounds and we introduce a novel algorithm improving over the state-of-the-art along multiple dimensions. We build on a reformulation of the lower bound, where context distribution and exploration policy are decoupled, and we obtain an algorithm robust to unbalanced context distributions. Then, using an incremental primal-dual approach to solve the Lagrangian relaxation of the lower bound, we obtain a scalable and computationally efficient algorithm. Finally, we remove forced exploration and build on confidence intervals of the optimization problem to encourage a minimum level of exploration that is better adapted to the problem structure. We demonstrate the asymptotic optimality of our algorithm, while providing both problem-dependent and worst-case finite-time regret guarantees. Our bounds scale with the logarithm of the number of arms, thus avoiding the linear dependence common in all related prior works. Notably, we establish minimax optimality for any learning horizon in the special case of non-contextual linear bandits. Finally, we verify that our algorithm obtains better empirical performance than state-of-the-art baselines.
Provably Efficient Reward-Agnostic Navigation with Linear Value Iteration
Aug 18, 2020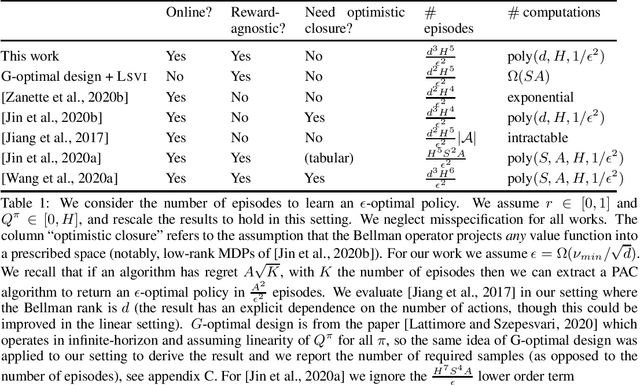

There has been growing progress on theoretical analyses for provably efficient learning in MDPs with linear function approximation, but much of the existing work has made strong assumptions to enable exploration by conventional exploration frameworks. Typically these assumptions are stronger than what is needed to find good solutions in the batch setting. In this work, we show how under a more standard notion of low inherent Bellman error, typically employed in least-square value iteration-style algorithms, we can provide strong PAC guarantees on learning a near optimal value function provided that the linear space is sufficiently ``explorable''. We present a computationally tractable algorithm for the reward-free setting and show how it can be used to learn a near optimal policy for any (linear) reward function, which is revealed only once learning has completed. If this reward function is also estimated from the samples gathered during pure exploration, our results also provide same-order PAC guarantees on the performance of the resulting policy for this setting.
Efficient Optimistic Exploration in Linear-Quadratic Regulators via Lagrangian Relaxation
Jul 13, 2020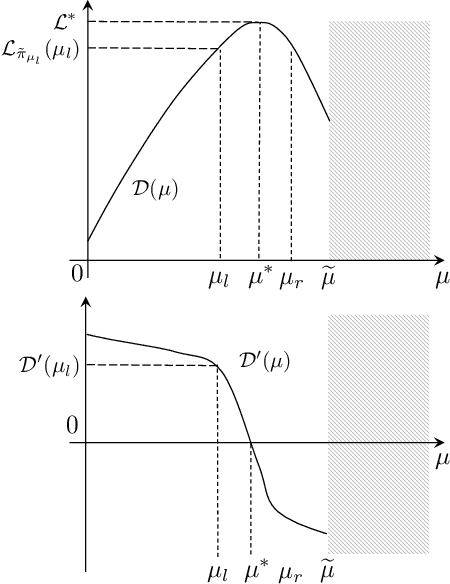


We study the exploration-exploitation dilemma in the linear quadratic regulator (LQR) setting. Inspired by the extended value iteration algorithm used in optimistic algorithms for finite MDPs, we propose to relax the optimistic optimization of \ofulq and cast it into a constrained \textit{extended} LQR problem, where an additional control variable implicitly selects the system dynamics within a confidence interval. We then move to the corresponding Lagrangian formulation for which we prove strong duality. As a result, we show that an $\epsilon$-optimistic controller can be computed efficiently by solving at most $O\big(\log(1/\epsilon)\big)$ Riccati equations. Finally, we prove that relaxing the original \ofu problem does not impact the learning performance, thus recovering the $\tilde{O}(\sqrt{T})$ regret of \ofulq. To the best of our knowledge, this is the first computationally efficient confidence-based algorithm for LQR with worst-case optimal regret guarantees.
A Provably Efficient Sample Collection Strategy for Reinforcement Learning
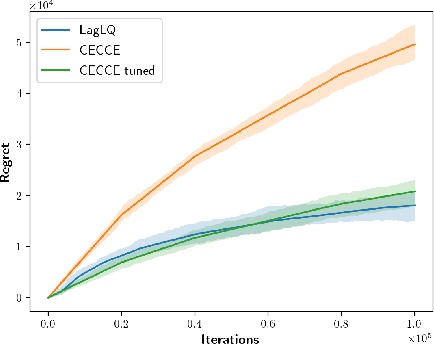
Jul 13, 2020
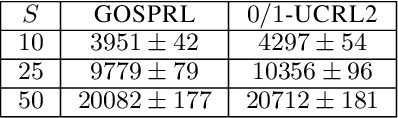
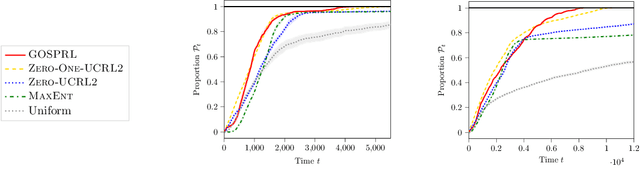
A common assumption in reinforcement learning (RL) is to have access to a generative model (i.e., a simulator of the environment), which allows to generate samples from any desired state-action pair. Nonetheless, in many settings a generative model may not be available and an adaptive exploration strategy is needed to efficiently collect samples from an unknown environment by direct interaction. In this paper, we study the scenario where an algorithm based on the generative model assumption defines the (possibly time-varying) amount of samples $b(s,a)$ required at each state-action pair $(s,a)$ and an exploration strategy has to learn how to generate $b(s,a)$ samples as fast as possible. Building on recent results for regret minimization in the stochastic shortest path (SSP) setting (Cohen et al., 2020; Tarbouriech et al., 2020), we derive an algorithm that requires $\tilde{O}( B D + D^{3/2} S^2 A)$ time steps to collect the $B = \sum_{s,a} b(s,a)$ desired samples, in any unknown and communicating MDP with $S$ states, $A$ actions and diameter $D$. Leveraging the generality of our strategy, we readily apply it to a variety of existing settings (e.g., model estimation, pure exploration in MDPs) for which we obtain improved sample-complexity guarantees, and to a set of new problems such as best-state identification and sparse reward discovery.
Improved Analysis of UCRL2 with Empirical Bernstein Inequality
Jul 10, 2020
We consider the problem of exploration-exploitation in communicating Markov Decision Processes. We provide an analysis of UCRL2 with Empirical Bernstein inequalities (UCRL2B). For any MDP with $S$ states, $A$ actions, $\Gamma \leq S$ next states and diameter $D$, the regret of UCRL2B is bounded as $\widetilde{O}(\sqrt{D\Gamma S A T})$.
A Novel Confidence-Based Algorithm for Structured Bandits
May 23, 2020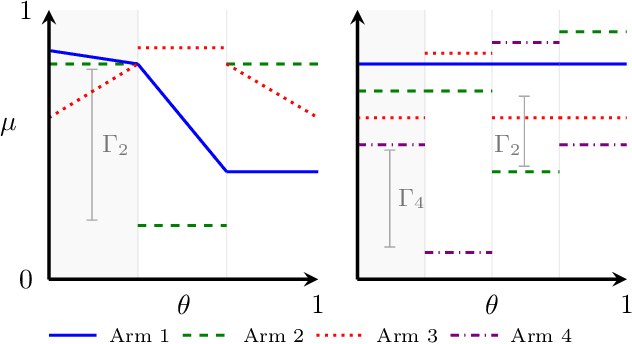

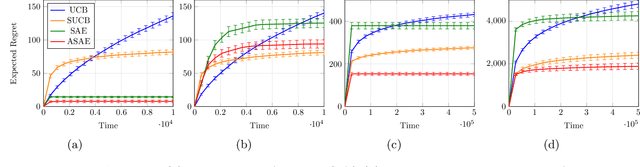
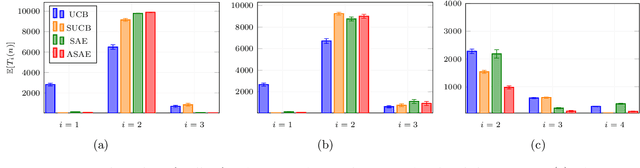
We study finite-armed stochastic bandits where the rewards of each arm might be correlated to those of other arms. We introduce a novel phased algorithm that exploits the given structure to build confidence sets over the parameters of the true bandit problem and rapidly discard all sub-optimal arms. In particular, unlike standard bandit algorithms with no structure, we show that the number of times a suboptimal arm is selected may actually be reduced thanks to the information collected by pulling other arms. Furthermore, we show that, in some structures, the regret of an anytime extension of our algorithm is uniformly bounded over time. For these constant-regret structures, we also derive a matching lower bound. Finally, we demonstrate numerically that our approach better exploits certain structures than existing methods.
Meta-learning with Stochastic Linear Bandits
May 18, 2020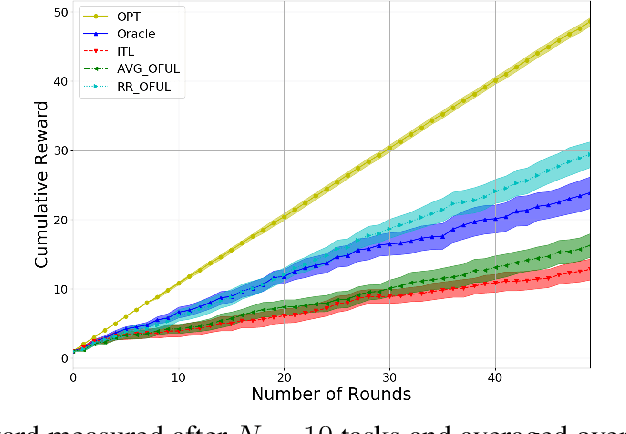
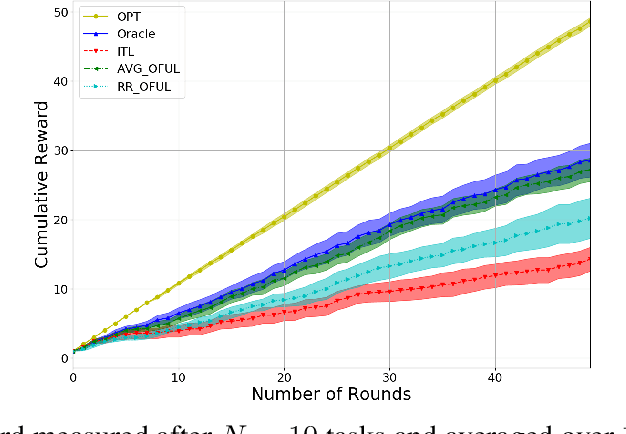
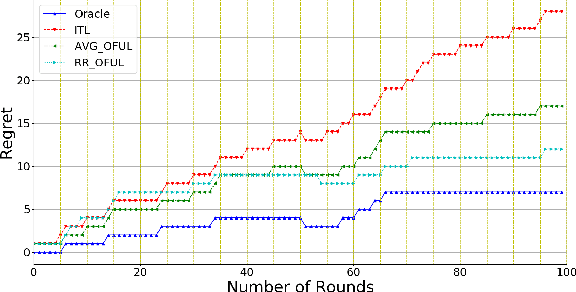
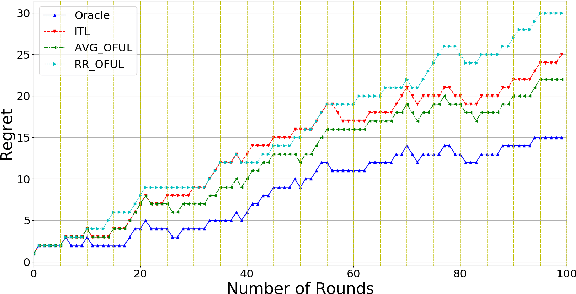
We investigate meta-learning procedures in the setting of stochastic linear bandits tasks. The goal is to select a learning algorithm which works well on average over a class of bandits tasks, that are sampled from a task-distribution. Inspired by recent work on learning-to-learn linear regression, we consider a class of bandit algorithms that implement a regularized version of the well-known OFUL algorithm, where the regularization is a square euclidean distance to a bias vector. We first study the benefit of the biased OFUL algorithm in terms of regret minimization. We then propose two strategies to estimate the bias within the learning-to-learn setting. We show both theoretically and experimentally, that when the number of tasks grows and the variance of the task-distribution is small, our strategies have a significant advantage over learning the tasks in isolation.
Learning Adaptive Exploration Strategies in Dynamic Environments Through Informed Policy Regularization
May 06, 2020

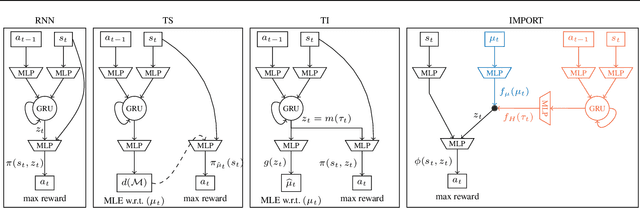
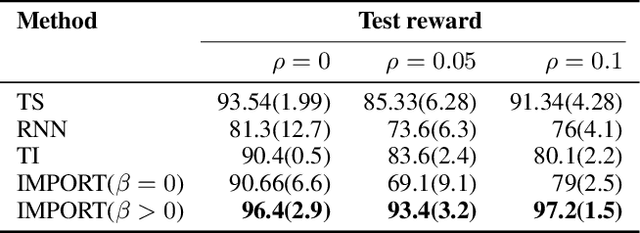
We study the problem of learning exploration-exploitation strategies that effectively adapt to dynamic environments, where the task may change over time. While RNN-based policies could in principle represent such strategies, in practice their training time is prohibitive and the learning process often converges to poor solutions. In this paper, we consider the case where the agent has access to a description of the task (e.g., a task id or task parameters) at training time, but not at test time. We propose a novel algorithm that regularizes the training of an RNN-based policy using informed policies trained to maximize the reward in each task. This dramatically reduces the sample complexity of training RNN-based policies, without losing their representational power. As a result, our method learns exploration strategies that efficiently balance between gathering information about the unknown and changing task and maximizing the reward over time. We test the performance of our algorithm in a variety of environments where tasks may vary within each episode.
Active Model Estimation in Markov Decision Processes
Mar 06, 2020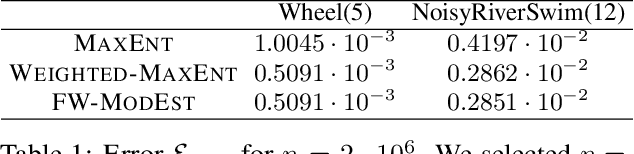
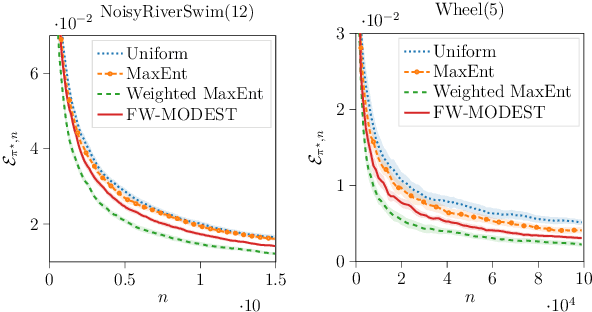
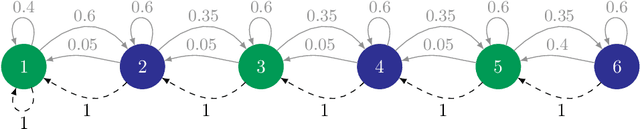
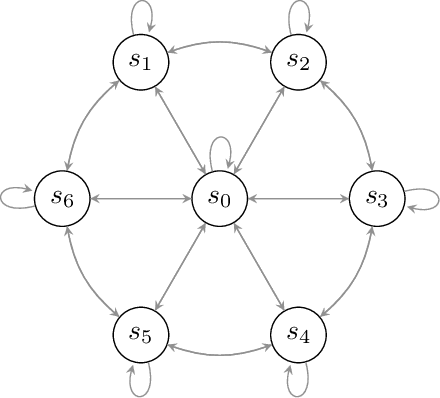
We study the problem of efficient exploration in order to learn an accurate model of an environment, modeled as a Markov decision process (MDP). Efficient exploration in this problem requires the agent to identify the regions in which estimating the model is more difficult and then exploit this knowledge to collect more samples there. In this paper, we formalize this problem, introduce the first algorithm to learn an $\epsilon$-accurate estimate of the dynamics, and provide its sample complexity analysis. While this algorithm enjoys strong guarantees in the large-sample regime, it tends to have a poor performance in early stages of exploration. To address this issue, we propose an algorithm that is based on maximum weighted entropy, a heuristic that stems from common sense and our theoretical analysis. The main idea here is cover the entire state-action space with the weight proportional to the noise in the transitions. Using a number of simple domains with heterogeneous noise in their transitions, we show that our heuristic-based algorithm outperforms both our original algorithm and the maximum entropy algorithm in the small sample regime, while achieving similar asymptotic performance as that of the original algorithm.
Learning Near Optimal Policies with Low Inherent Bellman Error
Mar 05, 2020
We study the exploration problem with approximate linear action-value functions in episodic reinforcement learning under the notion of low inherent Bellman error, a condition normally employed to show convergence of approximate value iteration. First we relate this condition to other common frameworks and show that it is strictly more general than the low rank (or linear) MDP assumption of prior work. Second we provide an algorithm with a high probability regret bound $\widetilde O(\sum_{t=1}^H d_t \sqrt{K} + \sum_{t=1}^H \sqrt{d_t} \IBE K)$ where $H$ is the horizon, $K$ is the number of episodes, $\IBE$ is the value if the inherent Bellman error and $d_t$ is the feature dimension at timestep $t$. In addition, we show that the result is unimprovable beyond constants and logs by showing a matching lower bound. This has two important consequences: 1) the algorithm has the optimal statistical rate for this setting which is more general than prior work on low-rank MDPs 2) the lack of closedness (measured by the inherent Bellman error) is only amplified by $\sqrt{d_t}$ despite working in the online setting. Finally, the algorithm reduces to the celebrated \textsc{LinUCB} when $H=1$ but with a different choice of the exploration parameter that allows handling misspecified contextual linear bandits. While computational tractability questions remain open for the MDP setting, this enriches the class of MDPs with a linear representation for the action-value function where statistically efficient reinforcement learning is possible.