 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Accuracy: The Right Metric for Evaluating LLM Judges -- Explained through Youden's J statistic
Dec 08, 2025



Rigorous evaluation of large language models (LLMs) relies on comparing models by the prevalence of desirable or undesirable behaviors, such as task pass rates or policy violations. These prevalence estimates are produced by a classifier, either an LLM-as-a-judge or human annotators, making the choice of classifier central to trustworthy evaluation. Common metrics used for this choice, such as Accuracy, Precision, and F1, are sensitive to class imbalance and to arbitrary choices of positive class, and can favor judges that distort prevalence estimates. We show that Youden's $J$ statistic is theoretically aligned with choosing the best judge to compare models, and that Balanced Accuracy is an equivalent linear transformation of $J$. Through both analytical arguments and empirical examples and simulations, we demonstrate how selecting judges using Balanced Accuracy leads to better, more robust classifier selection.
Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
Jun 12, 2024



The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Apr 29, 2024



Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
CLSE: Corpus of Linguistically Significant Entities
Nov 04, 2022



One of the biggest challenges of natural language generation (NLG) is the proper handling of named entities. Named entities are a common source of grammar mistakes such as wrong prepositions, wrong article handling, or incorrect entity inflection. Without factoring linguistic representation, such errors are often underrepresented when evaluating on a small set of arbitrarily picked argument values, or when translating a dataset from a linguistically simpler language, like English, to a linguistically complex language, like Russian. However, for some applications, broadly precise grammatical correctness is critical -- native speakers may find entity-related grammar errors silly, jarring, or even offensive. To enable the creation of more linguistically diverse NLG datasets, we release a Corpus of Linguistically Significant Entities (CLSE) annotated by linguist experts. The corpus includes 34 languages and covers 74 different semantic types to support various applications from airline ticketing to video games. To demonstrate one possible use of CLSE, we produce an augmented version of the Schema-Guided Dialog Dataset, SGD-CLSE. Using the CLSE's entities and a small number of human translations, we create a linguistically representative NLG evaluation benchmark in three languages: French (high-resource), Marathi (low-resource), and Russian (highly inflected language). We establish quality baselines for neural, template-based, and hybrid NLG systems and discuss the strengths and weaknesses of each approach.
Using Machine Translation to Localize Task Oriented NLG Output
Jul 09, 2021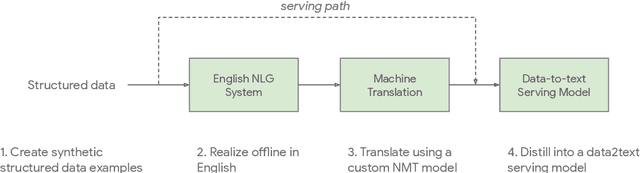
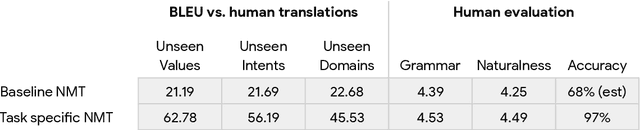
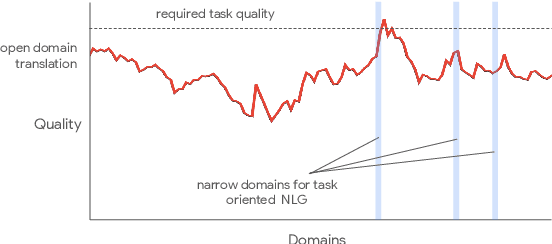
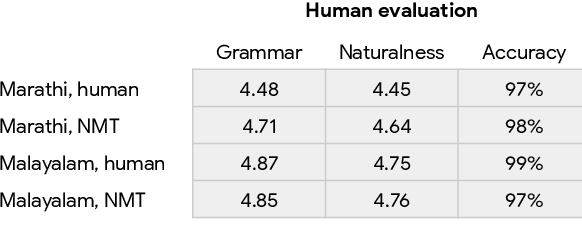
One of the challenges in a task oriented natural language application like the Google Assistant, Siri, or Alexa is to localize the output to many languages. This paper explores doing this by applying machine translation to the English output. Using machine translation is very scalable, as it can work with any English output and can handle dynamic text, but otherwise the problem is a poor fit. The required quality bar is close to perfection, the range of sentences is extremely narrow, and the sentences are often very different than the ones in the machine translation training data. This combination of requirements is novel in the field of domain adaptation for machine translation. We are able to reach the required quality bar by building on existing ideas and adding new ones: finetuning on in-domain translations, adding sentences from the Web, adding semantic annotations, and using automatic error detection. The paper shares our approach and results, together with a distillation model to serve the translation models at scale.