 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contextual Bandit Bake-off
May 30, 2018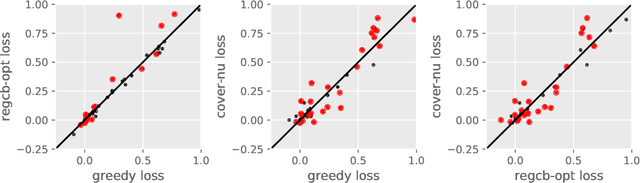

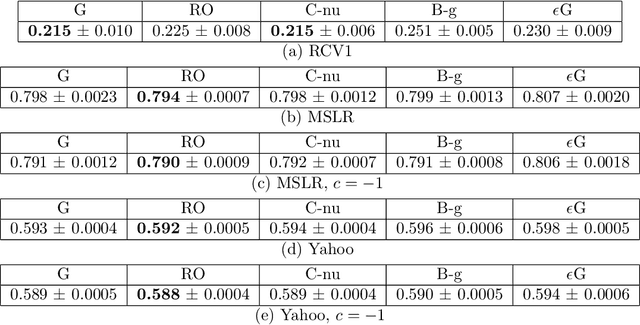
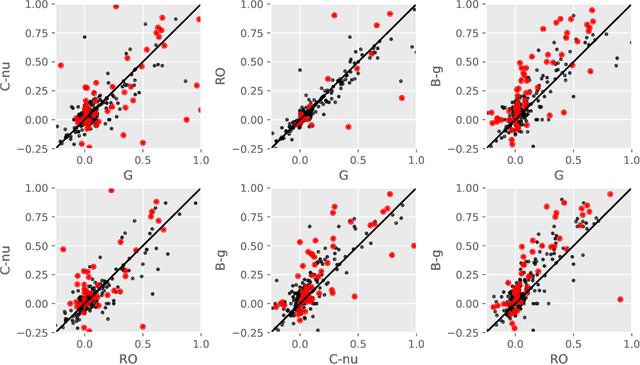
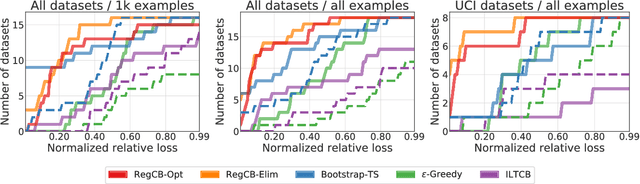
Contextual bandit algorithms are essential for solving many real-world interactive machine learning problems. Despite multiple recent successes on statistically and computationally efficient methods, the practical behavior of these algorithms is still poorly understood. We leverage the availability of large numbers of supervised learning datasets to compare and empirically optimize contextual bandit algorithms, focusing on practical methods that learn by relying on optimization oracles from supervised learning. We find that a recent method (Foster et al., 2018) using optimism under uncertainty works the best overall. A surprisingly close second is a simple greedy baseline that only explores implicitly through the diversity of contexts, followed by a variant of Online Cover (Agarwal et al., 2014) which tends to be more conservative but robust to problem specification by design. Along the way, we also evaluate and improve several internal components of contextual bandit algorithm design. Overall, this is a thorough study and review of contextual bandit methodology.
Practical Contextual Bandits with Regression Oracles
Mar 03, 2018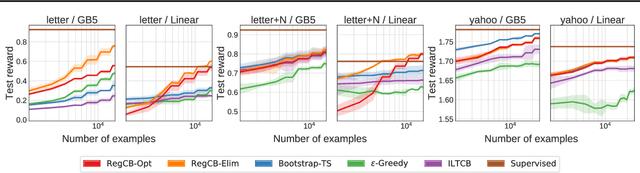
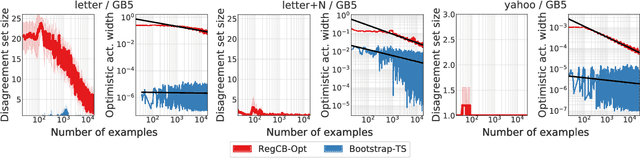
A major challenge in contextual bandits is to design general-purpose algorithms that are both practically useful and theoretically well-founded. We present a new technique that has the empirical and computational advantages of realizability-based approaches combined with the flexibility of agnostic methods. Our algorithms leverage the availability of a regression oracle for the value-function class, a more realistic and reasonable oracle than the classification oracles over policies typically assumed by agnostic methods. Our approach generalizes both UCB and LinUCB to far more expressive possible model classes and achieves low regret under certain distributional assumptions. In an extensive empirical evaluation, compared to both realizability-based and agnostic baselines, we find that our approach typically gives comparable or superior results.
Active Learning for Cost-Sensitive Classification
Nov 13, 2017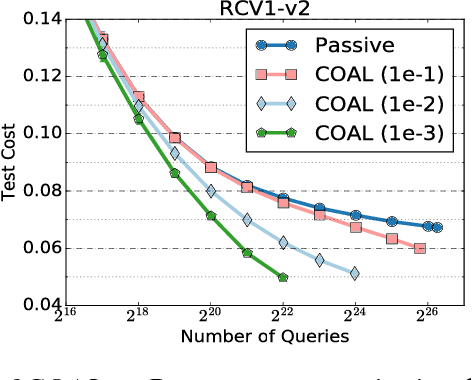
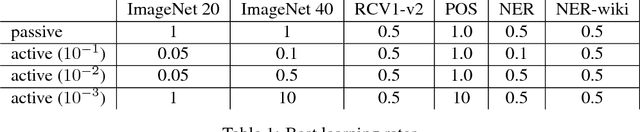
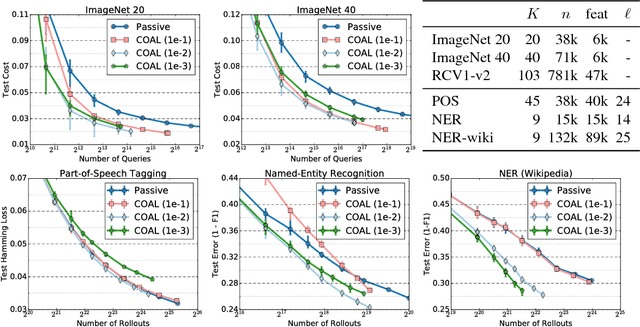
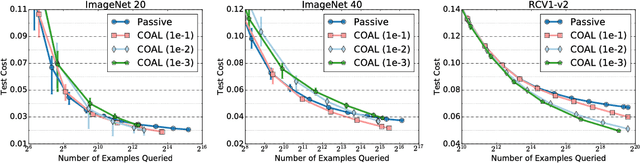
We design an active learning algorithm for cost-sensitive multiclass classification: problems where different errors have different costs. Our algorithm, COAL, makes predictions by regressing to each label's cost and predicting the smallest. On a new example, it uses a set of regressors that perform well on past data to estimate possible costs for each label. It queries only the labels that could be the best, ignoring the sure losers. We prove COAL can be efficiently implemented for any regression family that admits squared loss optimization; it also enjoys strong guarantees with respect to predictive performance and labeling effort. We empirically compare COAL to passive learning and several active learning baselines, showing significant improvements in labeling effort and test cost on real-world datasets.
Optimal and Adaptive Off-policy Evaluation in Contextual Bandits
Nov 11, 2017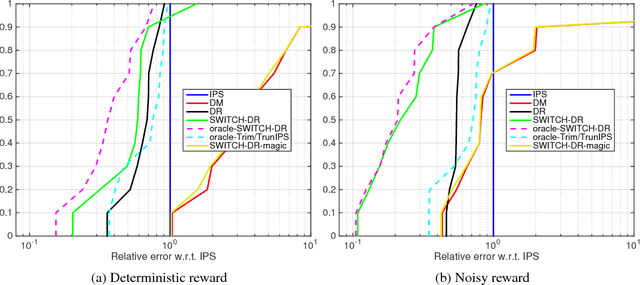
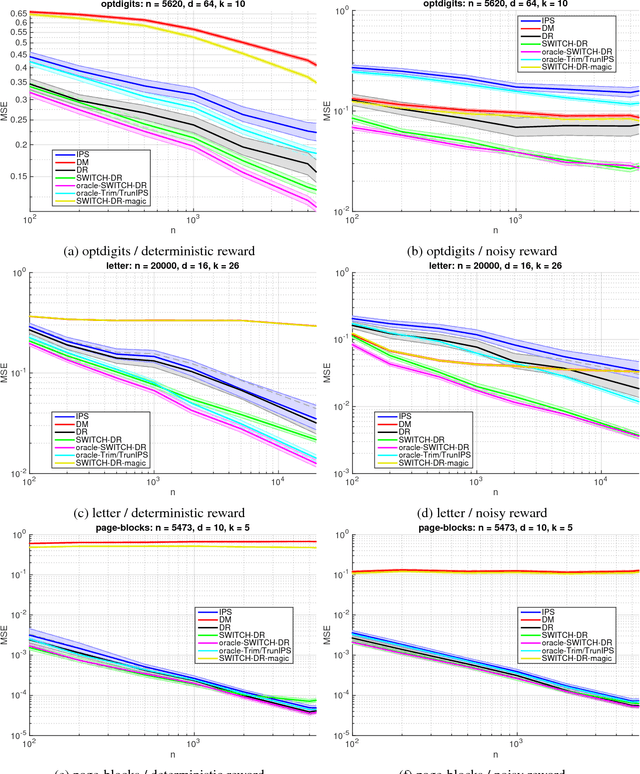
We study the off-policy evaluation problem---estimating the value of a target policy using data collected by another policy---under the contextual bandit model. We consider the general (agnostic) setting without access to a consistent model of rewards and establish a minimax lower bound on the mean squared error (MSE). The bound is matched up to constants by the inverse propensity scoring (IPS) and doubly robust (DR) estimators. This highlights the difficulty of the agnostic contextual setting, in contrast with multi-armed bandits and contextual bandits with access to a consistent reward model, where IPS is suboptimal. We then propose the SWITCH estimator, which can use an existing reward model (not necessarily consistent) to achieve a better bias-variance tradeoff than IPS and DR. We prove an upper bound on its MSE and demonstrate its benefits empirically on a diverse collection of data sets, often outperforming prior work by orders of magnitude.
Off-policy evaluation for slate recommendation
Nov 06, 2017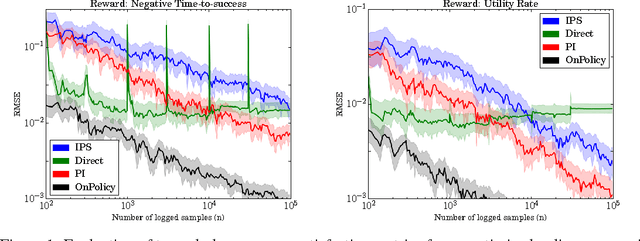
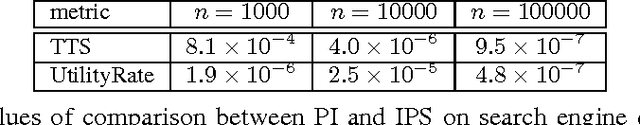
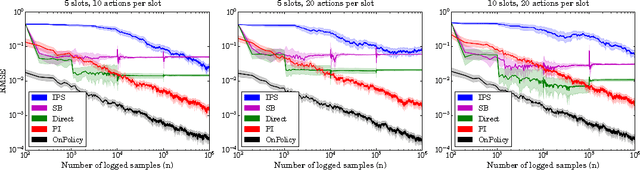
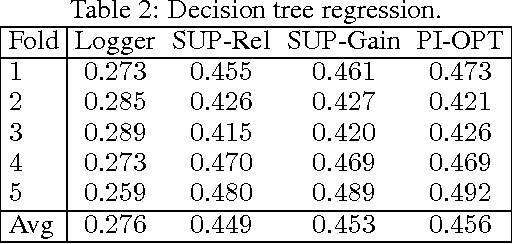
This paper studies the evaluation of policies that recommend an ordered set of items (e.g., a ranking) based on some context---a common scenario in web search, ads, and recommendation. We build on techniques from combinatorial bandits to introduce a new practical estimator that uses logged data to estimate a policy's performance. A thorough empirical evaluation on real-world data reveals that our estimator is accurate in a variety of settings, including as a subroutine in a learning-to-rank task, where it achieves competitive performance. We derive conditions under which our estimator is unbiased---these conditions are weaker than prior heuristics for slate evaluation---and experimentally demonstrate a smaller bias than parametric approaches, even when these conditions are violated. Finally, our theory and experiments also show exponential savings in the amount of required data compared with general unbiased estimators.
Efficient Second Order Online Learning by Sketching
Oct 17, 2017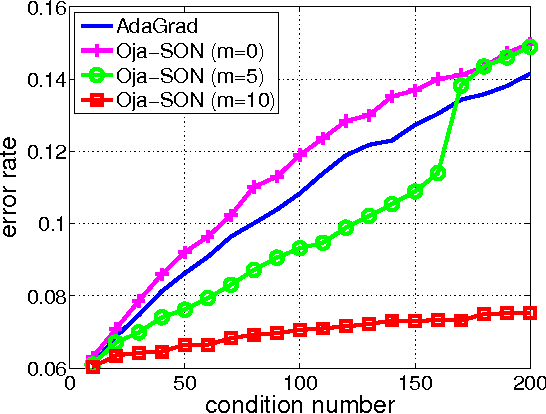
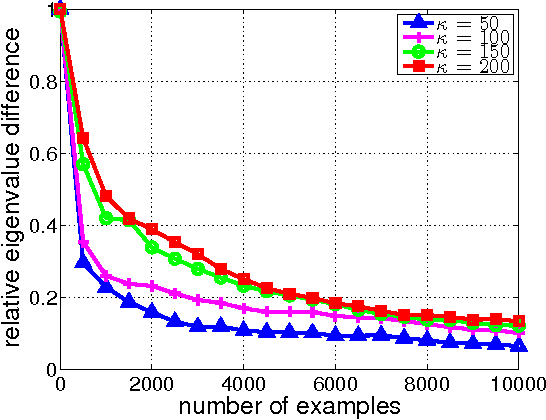
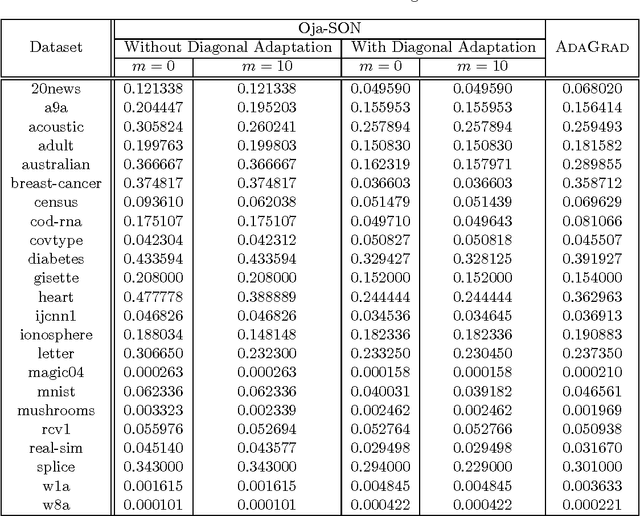
We propose Sketched Online Newton (SON), an online second order learning algorithm that enjoys substantially improved regret guarantees for ill-conditioned data. SON is an enhanced version of the Online Newton Step, which, via sketching techniques enjoys a running time linear in the dimension and sketch size. We further develop sparse forms of the sketching methods (such as Oja's rule), making the computation linear in the sparsity of features. Together, the algorithm eliminates all computational obstacles in previous second order online learning approaches.
Corralling a Band of Bandit Algorithms
Jun 06, 2017
We study the problem of combining multiple bandit algorithms (that is, online learning algorithms with partial feedback) with the goal of creating a master algorithm that performs almost as well as the best base algorithm if it were to be run on its own. The main challenge is that when run with a master, base algorithms unavoidably receive much less feedback and it is thus critical that the master not starve a base algorithm that might perform uncompetitively initially but would eventually outperform others if given enough feedback. We address this difficulty by devising a version of Online Mirror Descent with a special mirror map together with a sophisticated learning rate scheme. We show that this approach manages to achieve a more delicate balance between exploiting and exploring base algorithms than previous works yielding superior regret bounds. Our results are applicable to many settings, such as multi-armed bandits, contextual bandits, and convex bandits. As examples, we present two main applications. The first is to create an algorithm that enjoys worst-case robustness while at the same time performing much better when the environment is relatively easy. The second is to create an algorithm that works simultaneously under different assumptions of the environment, such as different priors or different loss structures.
Making Contextual Decisions with Low Technical Debt
May 09, 2017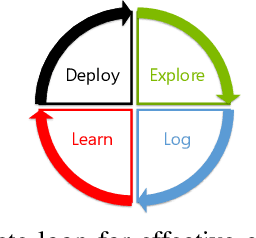
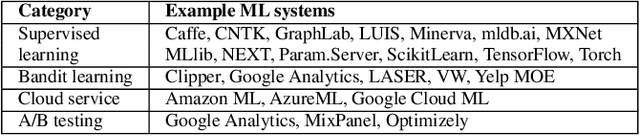

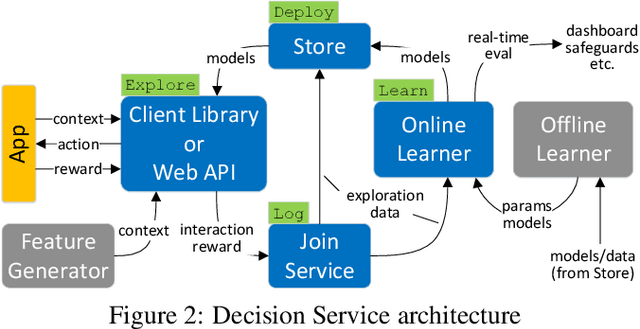
Applications and systems are constantly faced with decisions that require picking from a set of actions based on contextual information. Reinforcement-based learning algorithms such as contextual bandits can be very effective in these settings, but applying them in practice is fraught with technical debt, and no general system exists that supports them completely. We address this and create the first general system for contextual learning, called the Decision Service. Existing systems often suffer from technical debt that arises from issues like incorrect data collection and weak debuggability, issues we systematically address through our ML methodology and system abstractions. The Decision Service enables all aspects of contextual bandit learning using four system abstractions which connect together in a loop: explore (the decision space), log, learn, and deploy. Notably, our new explore and log abstractions ensure the system produces correct, unbiased data, which our learner uses for online learning and to enable real-time safeguards, all in a fully reproducible manner. The Decision Service has a simple user interface and works with a variety of applications: we present two live production deployments for content recommendation that achieved click-through improvements of 25-30%, another with 18% revenue lift in the landing page, and ongoing applications in tech support and machine failure handling. The service makes real-time decisions and learns continuously and scalably, while significantly lowering technical debt.
Contextual Decision Processes with Low Bellman Rank are PAC-Learnable
Dec 01, 2016
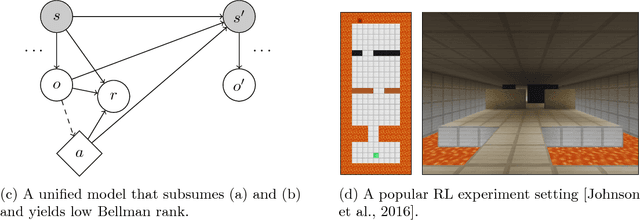
This paper studies systematic exploration for reinforcement learning with rich observations and function approximation. We introduce a new model called contextual decision processes, that unifies and generalizes most prior settings. Our first contribution is a complexity measure, the Bellman rank, that we show enables tractable learning of near-optimal behavior in these processes and is naturally small for many well-studied reinforcement learning settings. Our second contribution is a new reinforcement learning algorithm that engages in systematic exploration to learn contextual decision processes with low Bellman rank. Our algorithm provably learns near-optimal behavior with a number of samples that is polynomial in all relevant parameters but independent of the number of unique observations. The approach uses Bellman error minimization with optimistic exploration and provides new insights into efficient exploration for reinforcement learning with function approximation.
Contextual Semibandits via Supervised Learning Oracles
Nov 04, 2016
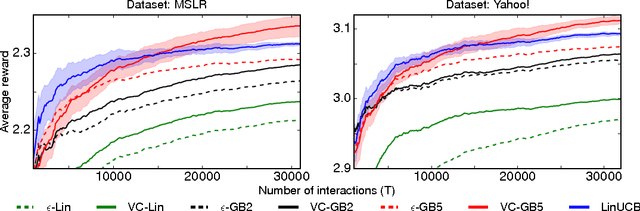
We study an online decision making problem where on each round a learner chooses a list of items based on some side information, receives a scalar feedback value for each individual item, and a reward that is linearly related to this feedback. These problems, known as contextual semibandits, arise in crowdsourcing, recommendation, and many other domains. This paper reduces contextual semibandits to supervised learning, allowing us to leverage powerful supervised learning methods in this partial-feedback setting. Our first reduction applies when the mapping from feedback to reward is known and leads to a computationally efficient algorithm with near-optimal regret. We show that this algorithm outperforms state-of-the-art approaches on real-world learning-to-rank datasets, demonstrating the advantage of oracle-based algorithms. Our second reduction applies to the previously unstudied setting when the linear mapping from feedback to reward is unknown. Our regret guarantees are superior to prior techniques that ignore the feedback.