 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of Graph Convolutional Neural Networks to Stochastic Perturbations
Jun 19, 2021


Graph convolutional neural networks (GCNNs) are nonlinear processing tools to learn representations from network data. A key property of GCNNs is their stability to graph perturbations. Current analysis considers deterministic perturbations but fails to provide relevant insights when topological changes are random. This paper investigates the stability of GCNNs to stochastic graph perturbations induced by link losses. In particular, it proves the expected output difference between the GCNN over random perturbed graphs and the GCNN over the nominal graph is upper bounded by a factor that is linear in the link loss probability. We perform the stability analysis in the graph spectral domain such that the result holds uniformly for any graph. This result also shows the role of the nonlinearity and the architecture width and depth, and allows identifying handle to improve the GCNN robustness. Numerical simulations on source localization and robot swarm control corroborate our theoretical findings.
Stability of Manifold Neural Networks to Deformations
Jun 07, 2021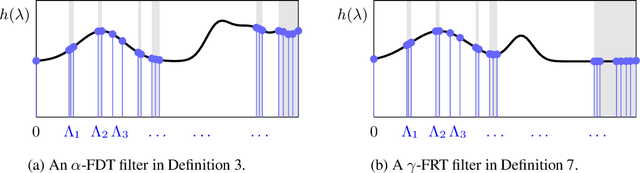
Stability is an important property of graph neural networks (GNNs) which explains their success in many problems of practical interest. Existing GNN stability results depend on the size of the graph, restricting applicability to graphs of moderate size. To understand the stability properties of GNNs on large graphs, we consider neural networks supported on manifolds. These are defined in terms of manifold diffusions mediated by the Laplace-Beltrami (LB) operator and are interpreted as limits of GNNs running on graphs of growing size. We define manifold deformations and show that they lead to perturbations of the manifold's LB operator that consist of an absolute and a relative perturbation term. We then define filters that split the infinite dimensional spectrum of the LB operator in finite partitions, and prove that manifold neural networks (MNNs) with these filters are stable to both, absolute and relative perturbations of the LB operator. Stability results are illustrated numerically in resource allocation problems in wireless networks.
Increase and Conquer: Training Graph Neural Networks on Growing Graphs
Jun 07, 2021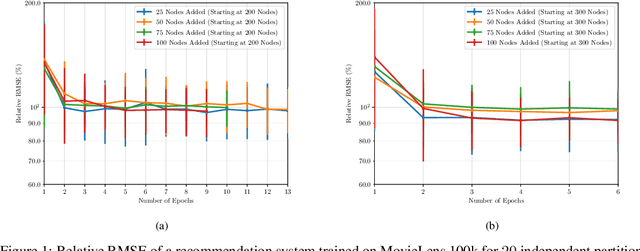
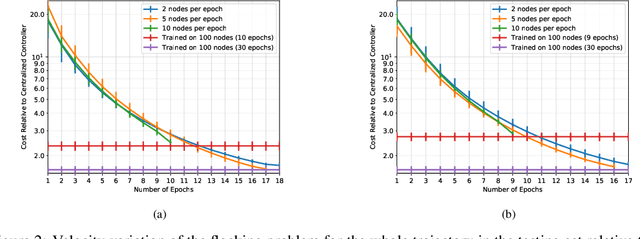
Graph neural networks (GNNs) use graph convolutions to exploit network invariances and learn meaningful features from network data. However, on large-scale graphs convolutions incur in high computational cost, leading to scalability limitations. Leveraging the graphon -- the limit object of a graph -- in this paper we consider the problem of learning a graphon neural network (WNN) -- the limit object of a GNN -- by training GNNs on graphs sampled Bernoulli from the graphon. Under smoothness conditions, we show that: (i) the expected distance between the learning steps on the GNN and on the WNN decreases asymptotically with the size of the graph, and (ii) when training on a sequence of growing graphs, gradient descent follows the learning direction of the WNN. Inspired by these results, we propose a novel algorithm to learn GNNs on large-scale graphs that, starting from a moderate number of nodes, successively increases the size of the graph during training. This algorithm is benchmarked on both a recommendation system and a decentralized control problem where it is shown to retain comparable performance, to its large-scale counterpart, at a reduced computational cost.
Training Robust Graph Neural Networks with Topology Adaptive Edge Dropping
Jun 05, 2021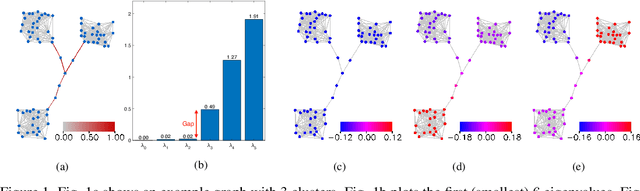
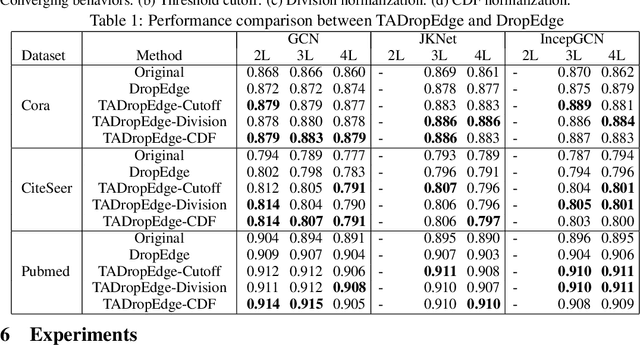
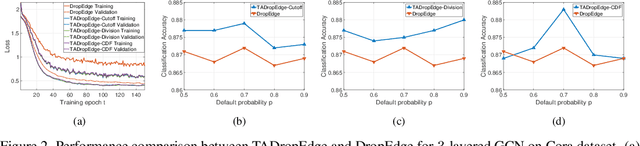
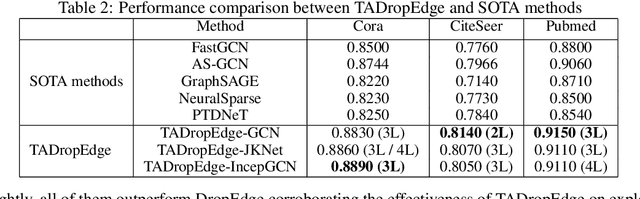
Graph neural networks (GNNs) are processing architectures that exploit graph structural information to model representations from network data. Despite their success, GNNs suffer from sub-optimal generalization performance given limited training data, referred to as over-fitting. This paper proposes Topology Adaptive Edge Dropping (TADropEdge) method as an adaptive data augmentation technique to improve generalization performance and learn robust GNN models. We start by explicitly analyzing how random edge dropping increases the data diversity during training, while indicating i.i.d. edge dropping does not account for graph structural information and could result in noisy augmented data degrading performance. To overcome this issue, we consider graph connectivity as the key property that captures graph topology. TADropEdge incorporates this factor into random edge dropping such that the edge-dropped subgraphs maintain similar topology as the underlying graph, yielding more satisfactory data augmentation. In particular, TADropEdge first leverages the graph spectrum to assign proper weights to graph edges, which represent their criticality for establishing the graph connectivity. It then normalizes the edge weights and drops graph edges adaptively based on their normalized weights. Besides improving generalization performance, TADropEdge reduces variance for efficient training and can be applied as a generic method modular to different GNN models. Intensive experiments on real-life and synthetic datasets corroborate theory and verify the effectiveness of the proposed method.
Graph Neural Networks for Decentralized Multi-Robot Submodular Action Selection
May 18, 2021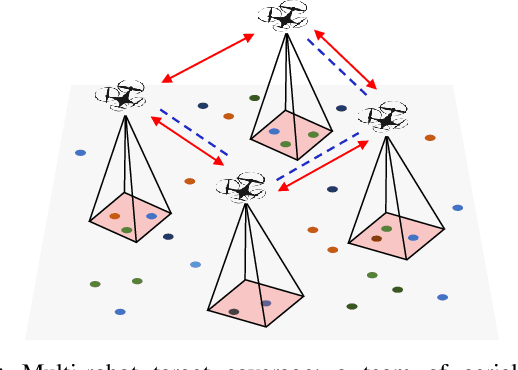
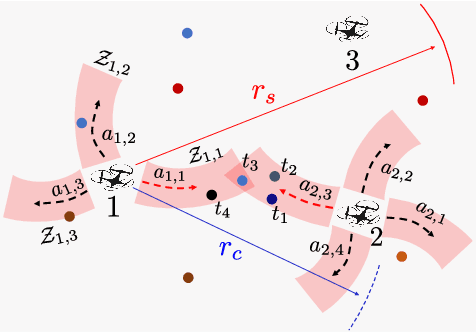
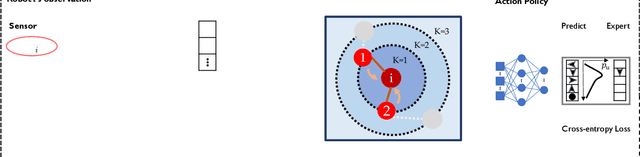
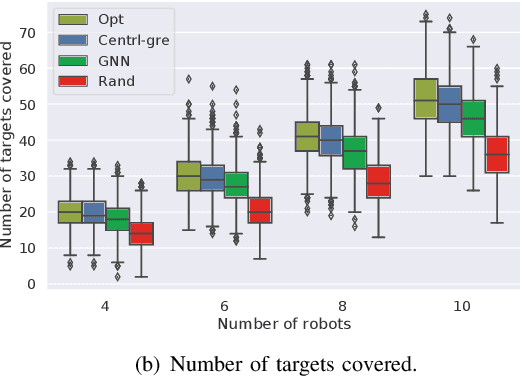
In this paper, we develop a learning-based approach for decentralized submodular maximization. We focus on applications where robots are required to jointly select actions, e.g., motion primitives, to maximize team submodular objectives with local communications only. Such applications are essential for large-scale multi-robot coordination such as multi-robot motion planning for area coverage, environment exploration, and target tracking. But the current decentralized submodular maximization algorithms either require assumptions on the inter-robot communication or lose some suboptimal guarantees. In this work, we propose a general-purpose learning architecture towards submodular maximization at scale, with decentralized communications. Particularly, our learning architecture leverages a graph neural network (GNN) to capture local interactions of the robots and learns decentralized decision-making for the robots. We train the learning model by imitating an expert solution and implement the resulting model for decentralized action selection involving local observations and communications only. We demonstrate the performance of our GNN-based learning approach in a scenario of active target coverage with large networks of robots. The simulation results show our approach nearly matches the coverage performance of the expert algorithm, and yet runs several orders faster with more than 30 robots. The results also exhibit our approach's generalization capability in previously unseen scenarios, e.g., larger environments and larger networks of robots.
Composable Learning with Sparse Kernel Representations
Mar 29, 2021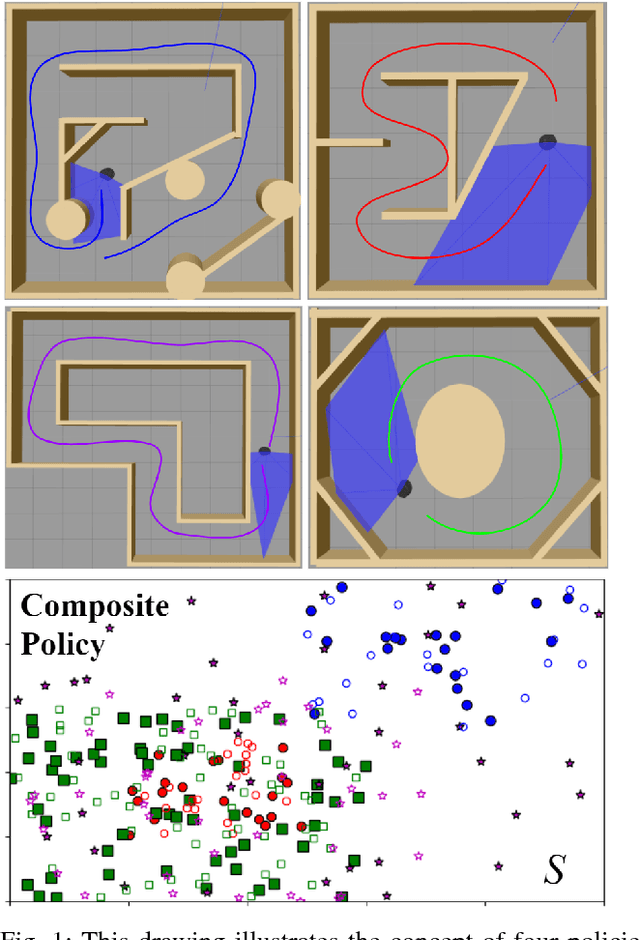


We present a reinforcement learning algorithm for learning sparse non-parametric controllers in a Reproducing Kernel Hilbert Space. We improve the sample complexity of this approach by imposing a structure of the state-action function through a normalized advantage function (NAF). This representation of the policy enables efficiently composing multiple learned models without additional training samples or interaction with the environment. We demonstrate the performance of this algorithm on learning obstacle-avoidance policies in multiple simulations of a robot equipped with a laser scanner while navigating in a 2D environment. We apply the composition operation to various policy combinations and test them to show that the composed policies retain the performance of their components. We also transfer the composed policy directly to a physical platform operating in an arena with obstacles in order to demonstrate a degree of generalization.
Constrained Learning with Non-Convex Losses
Mar 08, 2021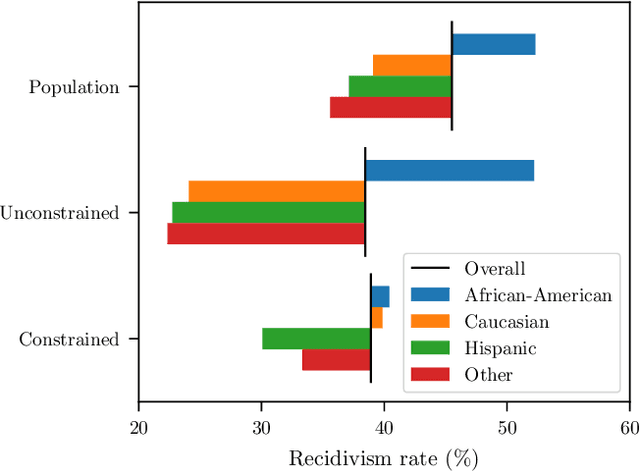
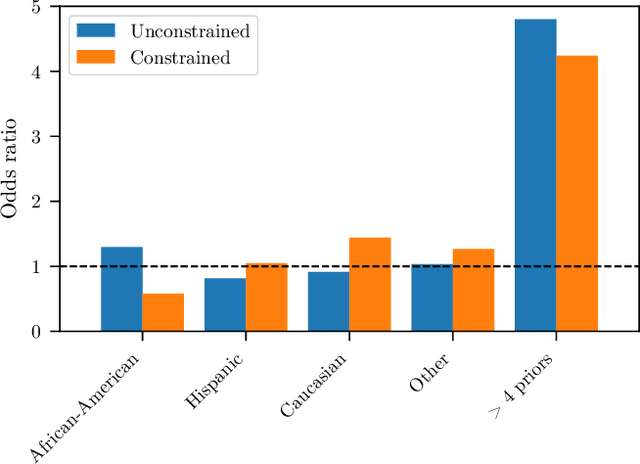
Though learning has become a core technology of modern information processing, there is now ample evidence that it can lead to biased, unsafe, and prejudiced solutions. The need to impose requirements on learning is therefore paramount, especially as it reaches critical applications in social, industrial, and medical domains. However, the non-convexity of most modern learning problems is only exacerbated by the introduction of constraints. Whereas good unconstrained solutions can often be learned using empirical risk minimization (ERM), even obtaining a model that satisfies statistical constraints can be challenging, all the more so a good one. In this paper, we overcome this issue by learning in the empirical dual domain, where constrained statistical learning problems become unconstrained, finite dimensional, and deterministic. We analyze the generalization properties of this approach by bounding the empirical duality gap, i.e., the difference between our approximate, tractable solution and the solution of the original (non-convex)~statistical problem, and provide a practical constrained learning algorithm. These results establish a constrained counterpart of classical learning theory and enable the explicit use of constraints in learning. We illustrate this algorithm and theory in rate-constrained learning applications.
Learning Connectivity for Data Distribution in Robot Teams
Mar 08, 2021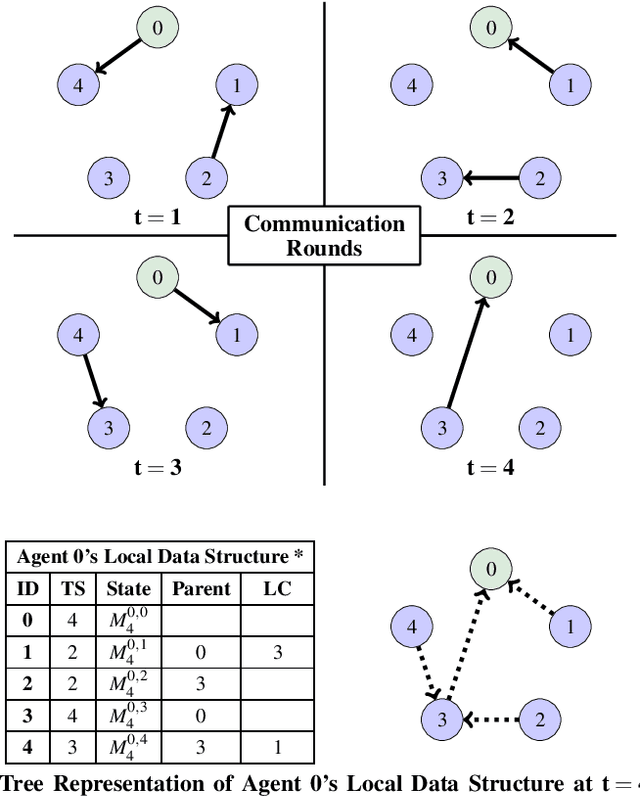

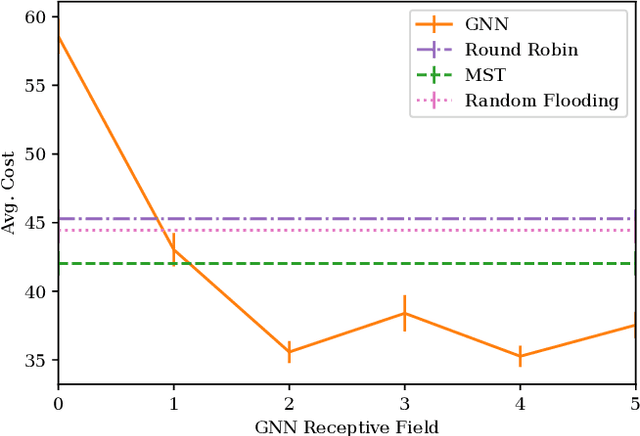
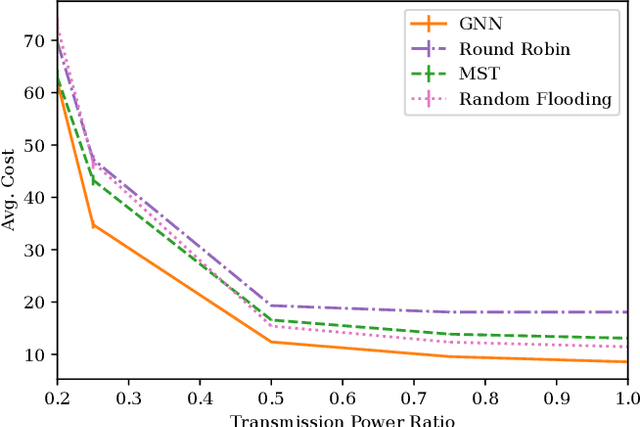
Many algorithms for control of multi-robot teams operate under the assumption that low-latency, global state information necessary to coordinate agent actions can readily be disseminated among the team. However, in harsh environments with no existing communication infrastructure, robots must form ad-hoc networks, forcing the team to operate in a distributed fashion. To overcome this challenge, we propose a task-agnostic, decentralized, low-latency method for data distribution in ad-hoc networks using Graph Neural Networks (GNN). Our approach enables multi-agent algorithms based on global state information to function by ensuring it is available at each robot. To do this, agents glean information about the topology of the network from packet transmissions and feed it to a GNN running locally which instructs the agent when and where to transmit the latest state information. We train the distributed GNN communication policies via reinforcement learning using the average Age of Information as the reward function and show that it improves training stability compared to task-specific reward functions. Our approach performs favorably compared to industry-standard methods for data distribution such as random flooding and round robin. We also show that the trained policies generalize to larger teams of both static and mobile agents.
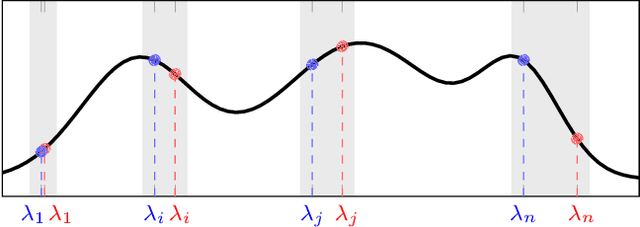
Stability of Neural Networks on Riemannian Manifolds
Mar 03, 2021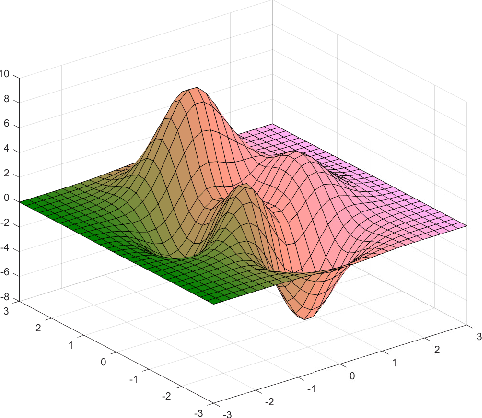
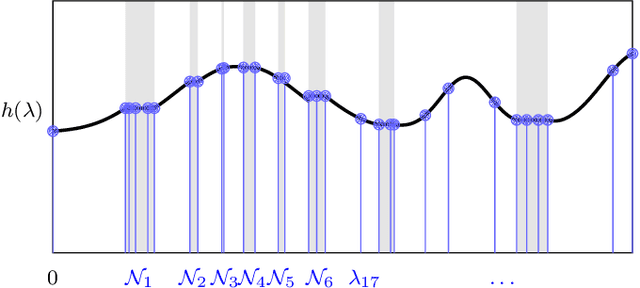
Convolutional Neural Networks (CNNs) have been applied to data with underlying non-Euclidean structures and have achieved impressive successes. This brings the stability analysis of CNNs on non-Euclidean domains into notice because CNNs have been proved stable on Euclidean domains. This paper focuses on the stability of CNNs on Riemannian manifolds. By taking the Laplace-Beltrami operators into consideration, we construct an $\alpha$-frequency difference threshold filter to help separate the spectrum of the operator with an infinite dimensionality. We further construct a manifold neural network architecture with these filters. We prove that both the manifold filters and neural networks are stable under absolute perturbations to the operators. The results also implicate a trade-off between the stability and discriminability of manifold neural networks. Finally we verify our conclusions with numerical experiments in a wireless adhoc network scenario.
State Augmented Constrained Reinforcement Learning: Overcoming the Limitations of Learning with Rewards
Feb 23, 2021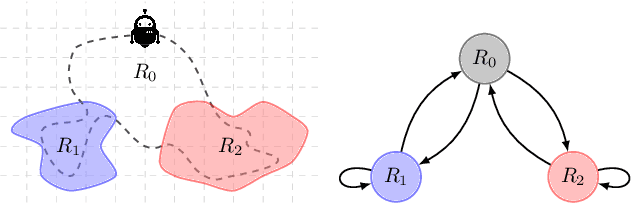
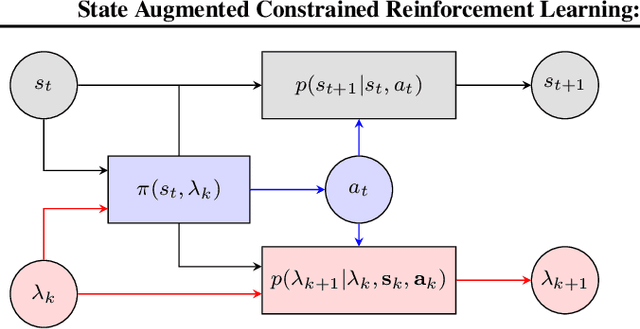
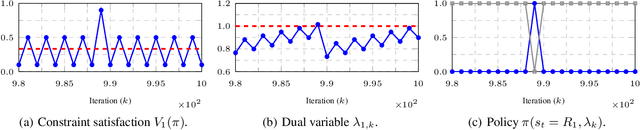
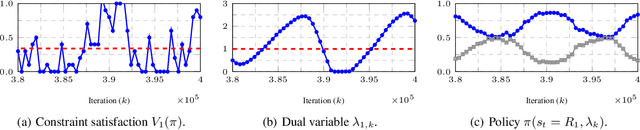
Constrained reinforcement learning involves multiple rewards that must individually accumulate to given thresholds. In this class of problems, we show a simple example in which the desired optimal policy cannot be induced by any linear combination of rewards. Hence, there exist constrained reinforcement learning problems for which neither regularized nor classical primal-dual methods yield optimal policies. This work addresses this shortcoming by augmenting the state with Lagrange multipliers and reinterpreting primal-dual methods as the portion of the dynamics that drives the multipliers evolution. This approach provides a systematic state augmentation procedure that is guaranteed to solve reinforcement learning problems with constraints. Thus, while primal-dual methods can fail at finding optimal policies, running the dual dynamics while executing the augmented policy yields an algorithm that provably samples actions from the optimal policy.