 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds Model Selection
Jun 29, 2022We study the problem of model selection in bandit scenarios in the presence of nested policy classes, with the goal of obtaining simultaneous adversarial and stochastic ("best of both worlds") high-probability regret guarantees. Our approach requires that each base learner comes with a candidate regret bound that may or may not hold, while our meta algorithm plays each base learner according to a schedule that keeps the base learner's candidate regret bounds balanced until they are detected to violate their guarantees. We develop careful mis-specification tests specifically designed to blend the above model selection criterion with the ability to leverage the (potentially benign) nature of the environment. We recover the model selection guarantees of the CORRAL algorithm for adversarial environments, but with the additional benefit of achieving high probability regret bounds, specifically in the case of nested adversarial linear bandits. More importantly, our model selection results also hold simultaneously in stochastic environments under gap assumptions. These are the first theoretical results that achieve best of both world (stochastic and adversarial) guarantees while performing model selection in (linear) bandit scenarios.
Joint Representation Training in Sequential Tasks with Shared Structure
Jun 24, 2022Classical theory in reinforcement learning (RL) predominantly focuses on the single task setting, where an agent learns to solve a task through trial-and-error experience, given access to data only from that task. However, many recent empirical works have demonstrated the significant practical benefits of leveraging a joint representation trained across multiple, related tasks. In this work we theoretically analyze such a setting, formalizing the concept of task relatedness as a shared state-action representation that admits linear dynamics in all the tasks. We introduce the Shared-MatrixRL algorithm for the setting of Multitask MatrixRL. In the presence of $P$ episodic tasks of dimension $d$ sharing a joint $r \ll d$ low-dimensional representation, we show the regret on the the $P$ tasks can be improved from $O(PHd\sqrt{NH})$ to $O((Hd\sqrt{rP} + HP\sqrt{rd})\sqrt{NH})$ over $N$ episodes of horizon $H$. These gains coincide with those observed in other linear models in contextual bandits and RL. In contrast with previous work that have studied multi task RL in other function approximation models, we show that in the presence of bilinear optimization oracle and finite state action spaces there exists a computationally efficient algorithm for multitask MatrixRL via a reduction to quadratic programming. We also develop a simple technique to shave off a $\sqrt{H}$ factor from the regret upper bounds of some episodic linear problems.
Online Nonsubmodular Minimization with Delayed Costs: From Full Information to Bandit Feedback
May 15, 2022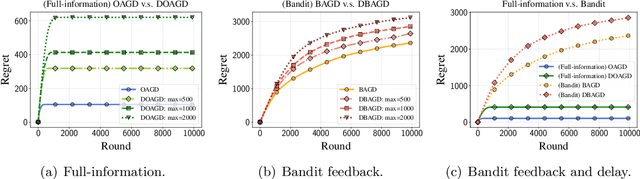
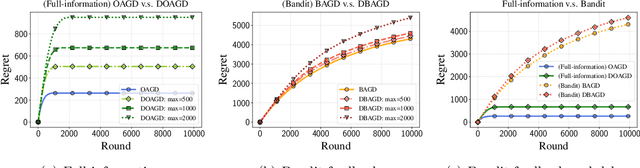
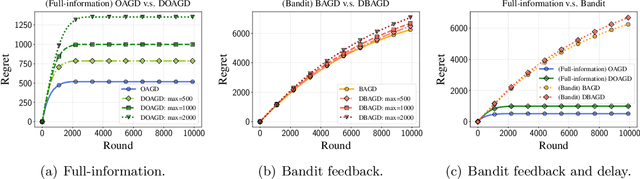
Motivated by applications to online learning in sparse estimation and Bayesian optimization, we consider the problem of online unconstrained nonsubmodular minimization with delayed costs in both full information and bandit feedback settings. In contrast to previous works on online unconstrained submodular minimization, we focus on a class of nonsubmodular functions with special structure, and prove regret guarantees for several variants of the online and approximate online bandit gradient descent algorithms in static and delayed scenarios. We derive bounds for the agent's regret in the full information and bandit feedback setting, even if the delay between choosing a decision and receiving the incurred cost is unbounded. Key to our approach is the notion of $(\alpha, \beta)$-regret and the extension of the generic convex relaxation model from~\citet{El-2020-Optimal}, the analysis of which is of independent interest. We conduct and showcase several simulation studies to demonstrate the efficacy of our algorithms.
Meta Learning MDPs with Linear Transition Models
Jan 21, 2022We study meta-learning in Markov Decision Processes (MDP) with linear transition models in the undiscounted episodic setting. Under a task sharedness metric based on model proximity we study task families characterized by a distribution over models specified by a bias term and a variance component. We then propose BUC-MatrixRL, a version of the UC-Matrix RL algorithm, and show it can meaningfully leverage a set of sampled training tasks to quickly solve a test task sampled from the same task distribution by learning an estimator of the bias parameter of the task distribution. The analysis leverages and extends results in the learning to learn linear regression and linear bandit setting to the more general case of MDP's with linear transition models. We prove that compared to learning the tasks in isolation, BUC-Matrix RL provides significant improvements in the transfer regret for high bias low variance task distributions.
Neural Pseudo-Label Optimism for the Bank Loan Problem
Dec 03, 2021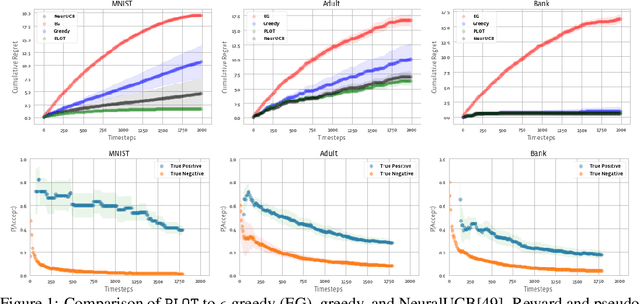
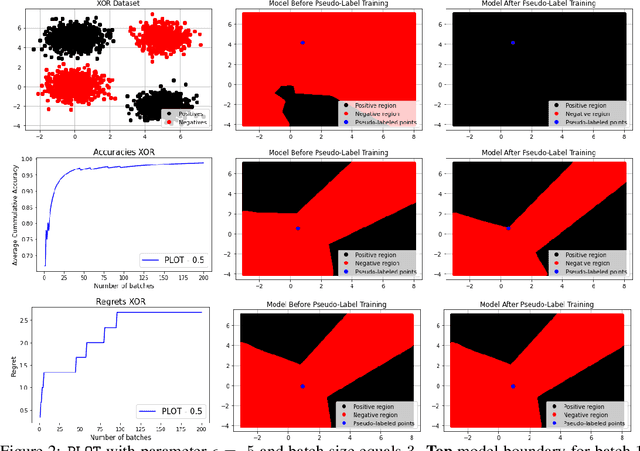
We study a class of classification problems best exemplified by the \emph{bank loan} problem, where a lender decides whether or not to issue a loan. The lender only observes whether a customer will repay a loan if the loan is issued to begin with, and thus modeled decisions affect what data is available to the lender for future decisions. As a result, it is possible for the lender's algorithm to ``get stuck'' with a self-fulfilling model. This model never corrects its false negatives, since it never sees the true label for rejected data, thus accumulating infinite regret. In the case of linear models, this issue can be addressed by adding optimism directly into the model predictions. However, there are few methods that extend to the function approximation case using Deep Neural Networks. We present Pseudo-Label Optimism (PLOT), a conceptually and computationally simple method for this setting applicable to DNNs. \PLOT{} adds an optimistic label to the subset of decision points the current model is deciding on, trains the model on all data so far (including these points along with their optimistic labels), and finally uses the resulting \emph{optimistic} model for decision making. \PLOT{} achieves competitive performance on a set of three challenging benchmark problems, requiring minimal hyperparameter tuning. We also show that \PLOT{} satisfies a logarithmic regret guarantee, under a Lipschitz and logistic mean label model, and under a separability condition on the data.
An Instance-Dependent Analysis for the Cooperative Multi-Player Multi-Armed Bandit
Nov 08, 2021
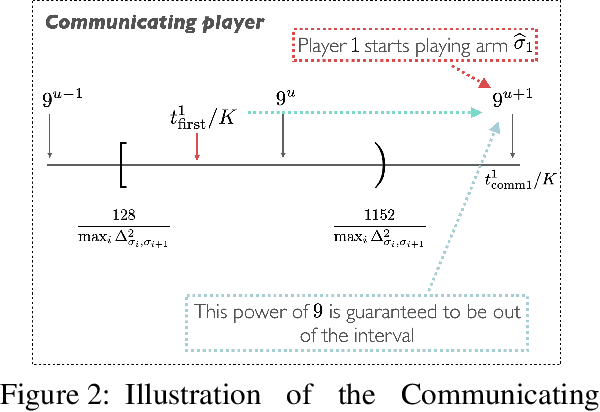
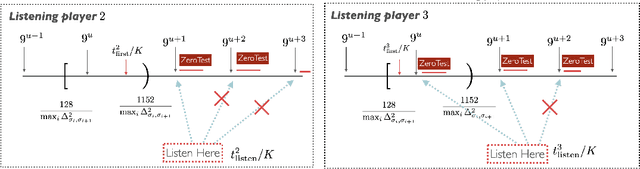
We study the problem of information sharing and cooperation in Multi-Player Multi-Armed bandits. We propose the first algorithm that achieves logarithmic regret for this problem. Our results are based on two innovations. First, we show that a simple modification to a successive elimination strategy can be used to allow the players to estimate their suboptimality gaps, up to constant factors, in the absence of collisions. Second, we leverage the first result to design a communication protocol that successfully uses the small reward of collisions to coordinate among players, while preserving meaningful instance-dependent logarithmic regret guarantees.
Dueling RL: Reinforcement Learning with Trajectory Preferences
Nov 08, 2021We consider the problem of preference based reinforcement learning (PbRL), where, unlike traditional reinforcement learning, an agent receives feedback only in terms of a 1 bit (0/1) preference over a trajectory pair instead of absolute rewards for them. The success of the traditional RL framework crucially relies on the underlying agent-reward model, which, however, depends on how accurately a system designer can express an appropriate reward function and often a non-trivial task. The main novelty of our framework is the ability to learn from preference-based trajectory feedback that eliminates the need to hand-craft numeric reward models. This paper sets up a formal framework for the PbRL problem with non-markovian rewards, where the trajectory preferences are encoded by a generalized linear model of dimension $d$. Assuming the transition model is known, we then propose an algorithm with almost optimal regret guarantee of $\tilde {\mathcal{O}}\left( SH d \log (T / \delta) \sqrt{T} \right)$. We further, extend the above algorithm to the case of unknown transition dynamics, and provide an algorithm with near optimal regret guarantee $\widetilde{\mathcal{O}}((\sqrt{d} + H^2 + |\mathcal{S}|)\sqrt{dT} +\sqrt{|\mathcal{S}||\mathcal{A}|TH} )$. To the best of our knowledge, our work is one of the first to give tight regret guarantees for preference based RL problems with trajectory preferences.
Towards an Understanding of Default Policies in Multitask Policy Optimization
Nov 06, 2021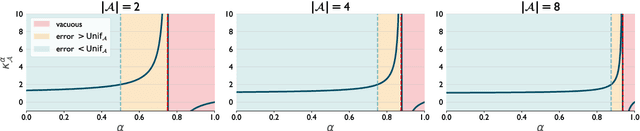


Much of the recent success of deep reinforcement learning has been driven by regularized policy optimization (RPO) algorithms, with strong performance across multiple domains. In this family of methods, agents are trained to maximize cumulative reward while penalizing deviation in behavior from some reference, or default policy. In addition to empirical success, there is a strong theoretical foundation for understanding RPO methods applied to single tasks, with connections to natural gradient, trust region, and variational approaches. However, there is limited formal understanding of desirable properties for default policies in the multitask setting, an increasingly important domain as the field shifts towards training more generally capable agents. Here, we take a first step towards filling this gap by formally linking the quality of the default policy to its effect on optimization. Using these results, we then derive a principled RPO algorithm for multitask learning with strong performance guarantees.
Reinforcement Learning in Linear MDPs: Constant Regret and Representation Selection
Oct 27, 2021
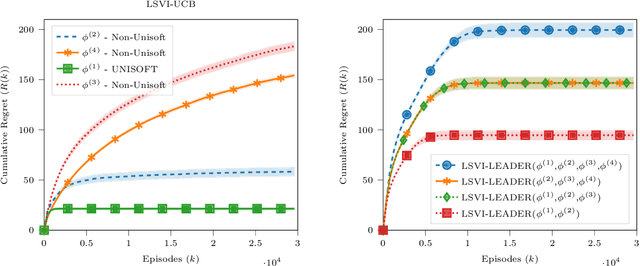

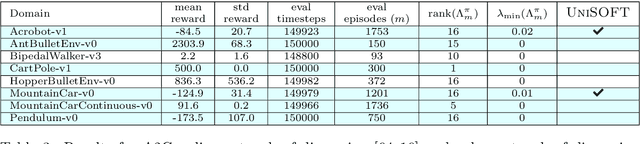
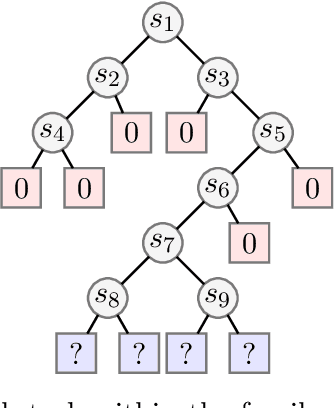
We study the role of the representation of state-action value functions in regret minimization in finite-horizon Markov Decision Processes (MDPs) with linear structure. We first derive a necessary condition on the representation, called universally spanning optimal features (UNISOFT), to achieve constant regret in any MDP with linear reward function. This result encompasses the well-known settings of low-rank MDPs and, more generally, zero inherent Bellman error (also known as the Bellman closure assumption). We then demonstrate that this condition is also sufficient for these classes of problems by deriving a constant regret bound for two optimistic algorithms (LSVI-UCB and ELEANOR). Finally, we propose an algorithm for representation selection and we prove that it achieves constant regret when one of the given representations, or a suitable combination of them, satisfies the UNISOFT condition.
Sample Efficient Reinforcement Learning In Continuous State Spaces: A Perspective Beyond Linearity
Jun 15, 2021
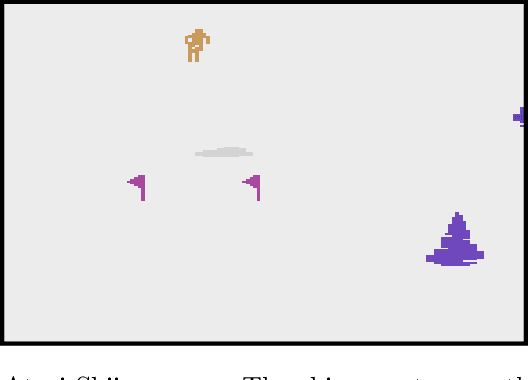
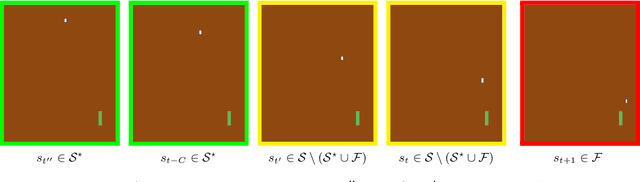
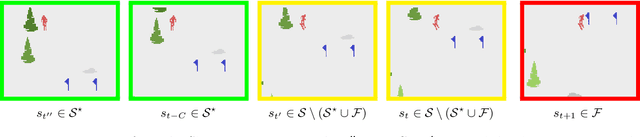
Reinforcement learning (RL) is empirically successful in complex nonlinear Markov decision processes (MDPs) with continuous state spaces. By contrast, the majority of theoretical RL literature requires the MDP to satisfy some form of linear structure, in order to guarantee sample efficient RL. Such efforts typically assume the transition dynamics or value function of the MDP are described by linear functions of the state features. To resolve this discrepancy between theory and practice, we introduce the Effective Planning Window (EPW) condition, a structural condition on MDPs that makes no linearity assumptions. We demonstrate that the EPW condition permits sample efficient RL, by providing an algorithm which provably solves MDPs satisfying this condition. Our algorithm requires minimal assumptions on the policy class, which can include multi-layer neural networks with nonlinear activation functions. Notably, the EPW condition is directly motivated by popular gaming benchmarks, and we show that many classic Atari games satisfy this condition. We additionally show the necessity of conditions like EPW, by demonstrating that simple MDPs with slight nonlinearities cannot be solved sample efficiently.