 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolution for Irregularly Sampled Temporal Point Clouds
May 01, 2021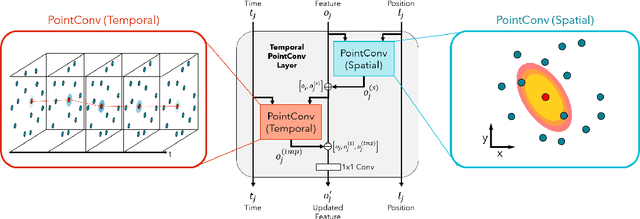

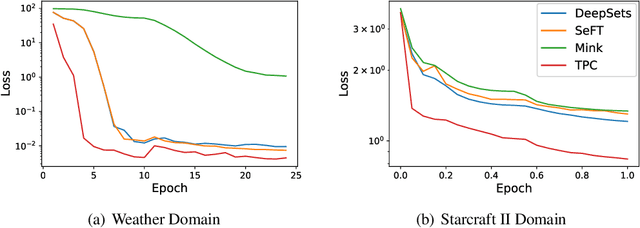

We consider the problem of modeling the dynamics of continuous spatial-temporal processes represented by irregular samples through both space and time. Such processes occur in sensor networks, citizen science, multi-robot systems, and many others. We propose a new deep model that is able to directly learn and predict over this irregularly sampled data, without voxelization, by leveraging a recent convolutional architecture for static point clouds. The model also easily incorporates the notion of multiple entities in the process. In particular, the model can flexibly answer prediction queries about arbitrary space-time points for different entities regardless of the distribution of the training or test-time data. We present experiments on real-world weather station data and battles between large armies in StarCraft II. The results demonstrate the model's flexibility in answering a variety of query types and demonstrate improved performance and efficiency compared to state-of-the-art baselines.
Optimizing Discrete Spaces via Expensive Evaluations: A Learning to Search Framework
Dec 14, 2020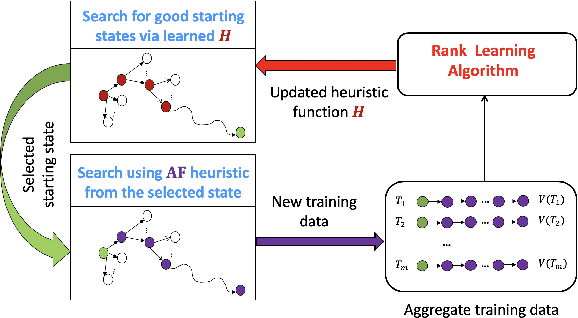
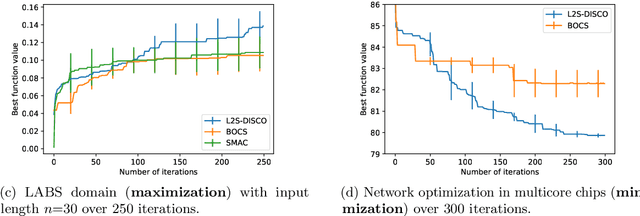
We consider the problem of optimizing expensive black-box functions over discrete spaces (e.g., sets, sequences, graphs). The key challenge is to select a sequence of combinatorial structures to evaluate, in order to identify high-performing structures as quickly as possible. Our main contribution is to introduce and evaluate a new learning-to-search framework for this problem called L2S-DISCO. The key insight is to employ search procedures guided by control knowledge at each step to select the next structure and to improve the control knowledge as new function evaluations are observed. We provide a concrete instantiation of L2S-DISCO for local search procedure and empirically evaluate it on diverse real-world benchmarks. Results show the efficacy of L2S-DISCO over state-of-the-art algorithms in solving complex optimization problems.
* 9 pages, 8 figures
Structured Attention Graphs for Understanding Deep Image Classifications
Dec 08, 2020

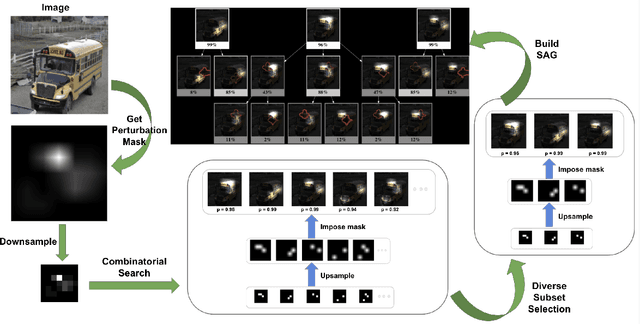

Attention maps are a popular way of explaining the decisions of convolutional networks for image classification. Typically, for each image of interest, a single attention map is produced, which assigns weights to pixels based on their importance to the classification. A single attention map, however, provides an incomplete understanding since there are often many other maps that explain a classification equally well. In this paper, we introduce structured attention graphs (SAGs), which compactly represent sets of attention maps for an image by capturing how different combinations of image regions impact a classifier's confidence. We propose an approach to compute SAGs and a visualization for SAGs so that deeper insight can be gained into a classifier's decisions. We conduct a user study comparing the use of SAGs to traditional attention maps for answering counterfactual questions about image classifications. Our results show that the users are more correct when answering comparative counterfactual questions based on SAGs compared to the baselines.
Learning Task Space Actions for Bipedal Locomotion
Nov 09, 2020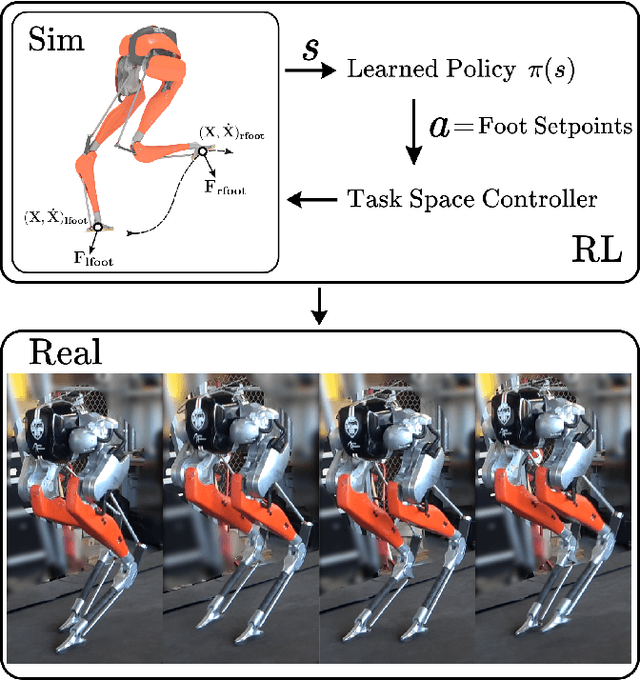
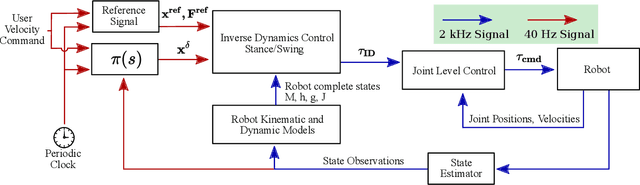
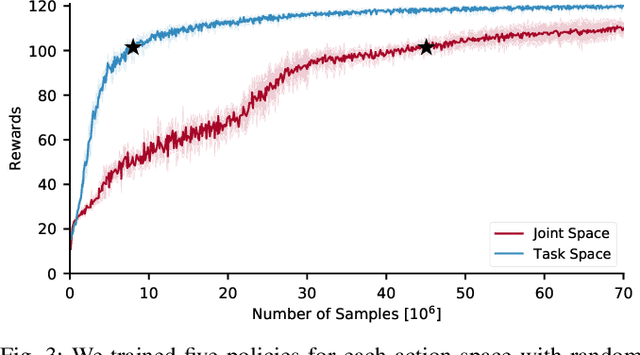
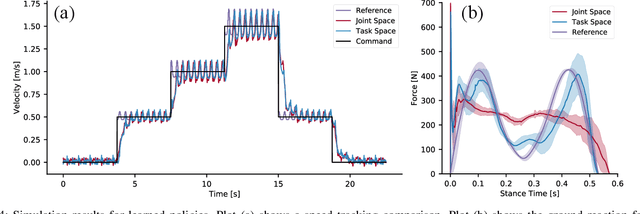
Recent work has demonstrated the success of reinforcement learning (RL) for training bipedal locomotion policies for real robots. This prior work, however, has focused on learning joint-coordination controllers based on an objective of following joint trajectories produced by already available controllers. As such, it is difficult to train these approaches to achieve higher-level goals of legged locomotion, such as simply specifying the desired end-effector foot movement or ground reaction forces. In this work, we propose an approach for integrating knowledge of the robot system into RL to allow for learning at the level of task space actions in terms of feet setpoints. In particular, we integrate learning a task space policy with a model-based inverse dynamics controller, which translates task space actions into joint-level controls. With this natural action space for learning locomotion, the approach is more sample efficient and produces desired task space dynamics compared to learning purely joint space actions. We demonstrate the approach in simulation and also show that the learned policies are able to transfer to the real bipedal robot Cassie. This result encourages further research towards incorporating bipedal control techniques into the structure of the learning process to enable dynamic behaviors.
Sim-to-Real Learning of All Common Bipedal Gaits via Periodic Reward Composition
Nov 02, 2020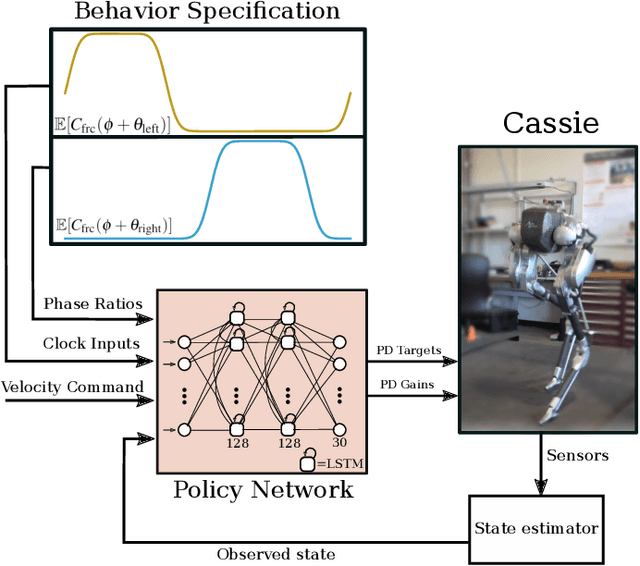
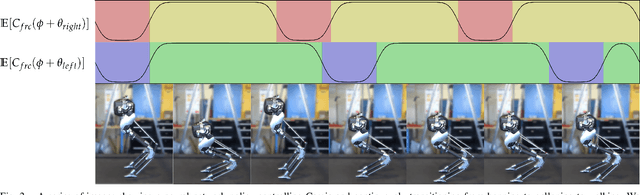
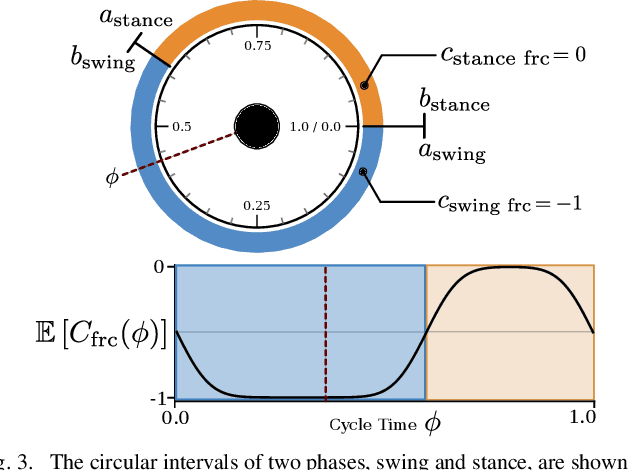
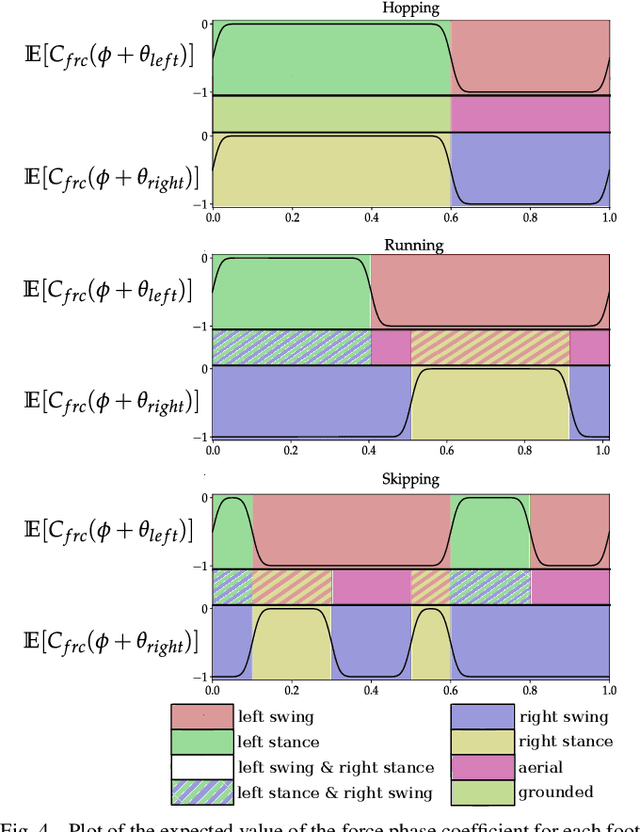
We study the problem of realizing the full spectrum of bipedal locomotion on a real robot with sim-to-real reinforcement learning (RL). A key challenge of learning legged locomotion is describing different gaits, via reward functions, in a way that is intuitive for the designer and specific enough to reliably learn the gait across different initial random seeds or hyperparameters. A common approach is to use reference motions (e.g. trajectories of joint positions) to guide learning. However, finding high-quality reference motions can be difficult and the trajectories themselves narrowly constrain the space of learned motion. At the other extreme, reference-free reward functions are often underspecified (e.g. move forward) leading to massive variance in policy behavior, or are the product of significant reward-shaping via trial-and-error, making them exclusive to specific gaits. In this work, we propose a reward-specification framework based on composing simple probabilistic periodic costs on basic forces and velocities. We instantiate this framework to define a parametric reward function with intuitive settings for all common bipedal gaits - standing, walking, hopping, running, and skipping. Using this function we demonstrate successful sim-to-real transfer of the learned gaits to the bipedal robot Cassie, as well as a generic policy that can transition between all of the two-beat gaits.
Learning Spring Mass Locomotion: Guiding Policies with a Reduced-Order Model
Oct 21, 2020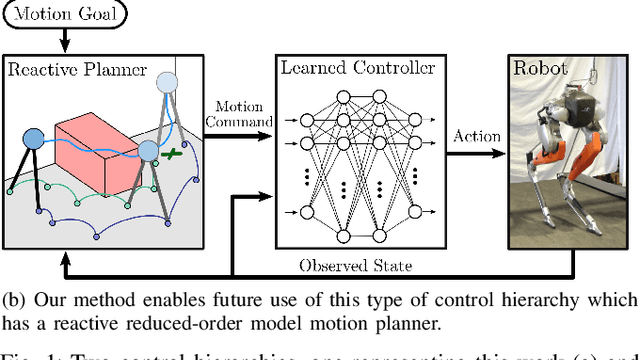
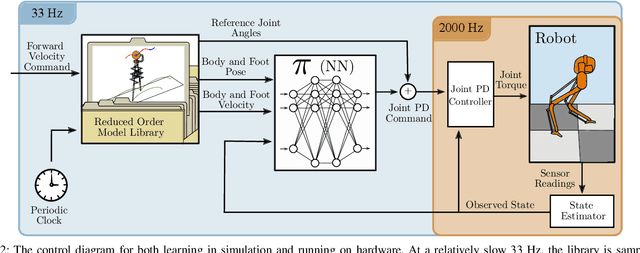

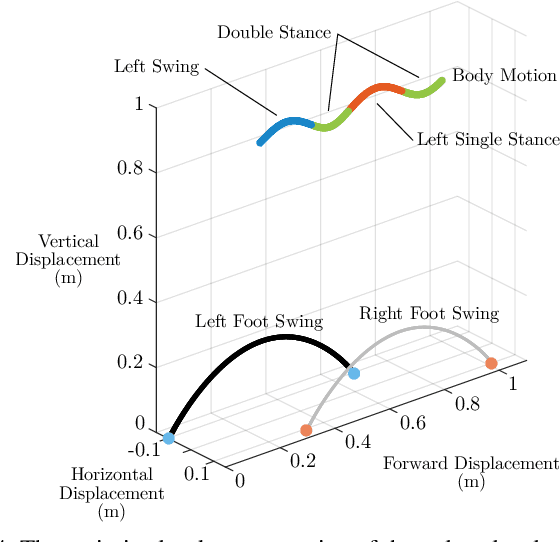
In this paper, we describe an approach to achieve dynamic legged locomotion on physical robots which combines existing methods for control with reinforcement learning. Specifically, our goal is a control hierarchy in which highest-level behaviors are planned through reduced-order models, which describe the fundamental physics of legged locomotion, and lower level controllers utilize a learned policy that can bridge the gap between the idealized, simple model and the complex, full order robot. The high-level planner can use a model of the environment and be task specific, while the low-level learned controller can execute a wide range of motions so that it applies to many different tasks. In this letter we describe this learned dynamic walking controller and show that a range of walking motions from reduced-order models can be used as the command and primary training signal for learned policies. The resulting policies do not attempt to naively track the motion (as a traditional trajectory tracking controller would) but instead balance immediate motion tracking with long term stability. The resulting controller is demonstrated on a human scale, unconstrained, untethered bipedal robot at speeds up to 1.2 m/s. This letter builds the foundation of a generic, dynamic learned walking controller that can be applied to many different tasks.
Dream and Search to Control: Latent Space Planning for Continuous Control
Oct 19, 2020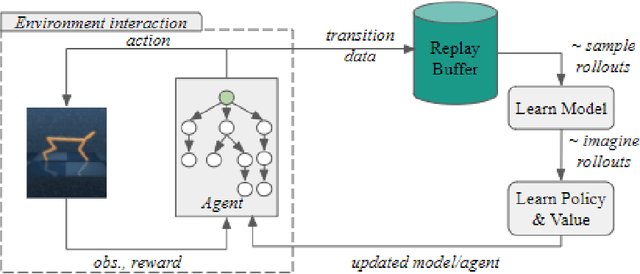
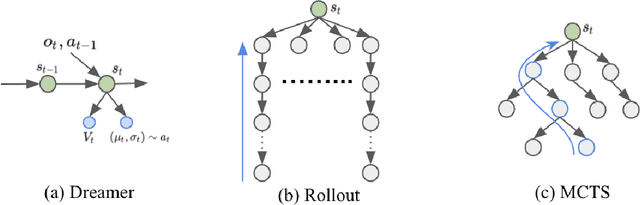
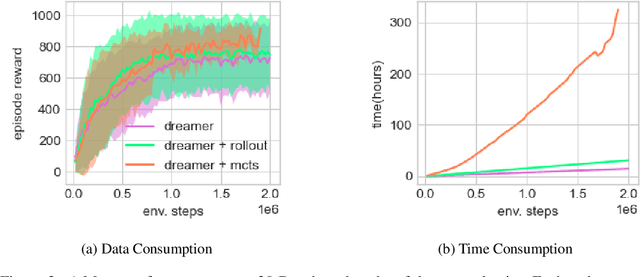
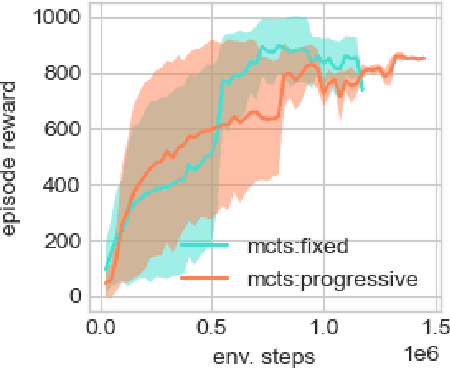
Learning and planning with latent space dynamics has been shown to be useful for sample efficiency in model-based reinforcement learning (MBRL) for discrete and continuous control tasks. In particular, recent work, for discrete action spaces, demonstrated the effectiveness of latent-space planning via Monte-Carlo Tree Search (MCTS) for bootstrapping MBRL during learning and at test time. However, the potential gains from latent-space tree search have not yet been demonstrated for environments with continuous action spaces. In this work, we propose and explore an MBRL approach for continuous action spaces based on tree-based planning over learned latent dynamics. We show that it is possible to demonstrate the types of bootstrapping benefits as previously shown for discrete spaces. In particular, the approach achieves improved sample efficiency and performance on a majority of challenging continuous-control benchmarks compared to the state-of-the-art.
DeepAveragers: Offline Reinforcement Learning by Solving Derived Non-Parametric MDPs
Oct 18, 2020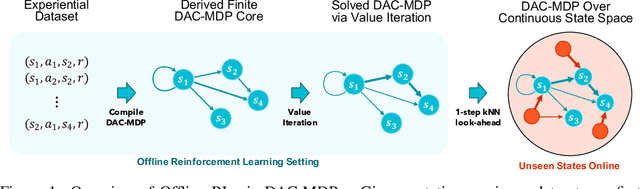

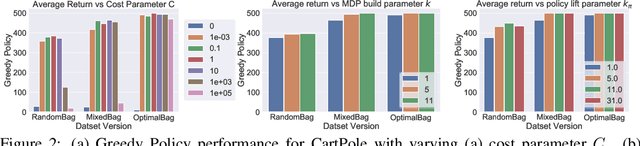
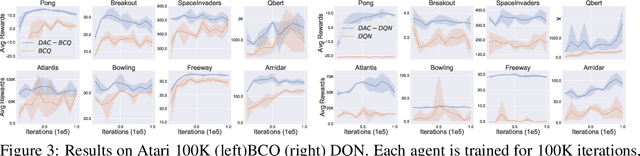
We study an approach to offline reinforcement learning (RL) based on optimally solving finitely-represented MDPs derived from a static dataset of experience. This approach can be applied on top of any learned representation and has the potential to easily support multiple solution objectives as well as zero-shot adjustment to changing environments and goals. Our main contribution is to introduce the Deep Averagers with Costs MDP (DAC-MDP) and to investigate its solutions for offline RL. DAC-MDPs are a non-parametric model that can leverage deep representations and account for limited data by introducing costs for exploiting under-represented parts of the model. In theory, we show conditions that allow for lower-bounding the performance of DAC-MDP solutions. We also investigate the empirical behavior in a number of environments, including those with image-based observations. Overall, the experiments demonstrate that the framework can work in practice and scale to large complex offline RL problems.
Contrastive Explanations for Reinforcement Learning via Embedded Self Predictions
Oct 11, 2020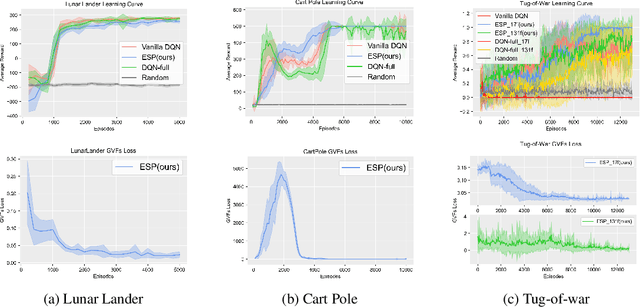
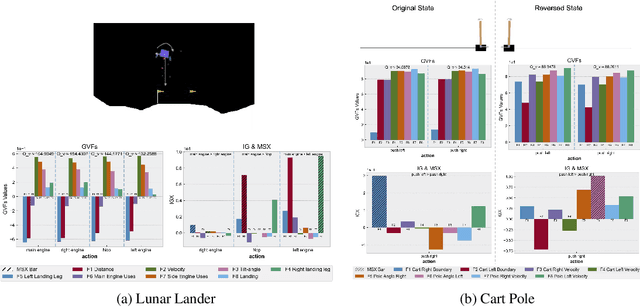
We investigate a deep reinforcement learning (RL) architecture that supports explaining why a learned agent prefers one action over another. The key idea is to learn action-values that are directly represented via human-understandable properties of expected futures. This is realized via the embedded self-prediction (ESP)model, which learns said properties in terms of human provided features. Action preferences can then be explained by contrasting the future properties predicted for each action. To address cases where there are a large number of features, we develop a novel method for computing minimal sufficient explanations from anESP. Our case studies in three domains, including a complex strategy game, show that ESP models can be effectively learned and support insightful explanations.
Understanding Finite-State Representations of Recurrent Policy Networks
Jun 06, 2020
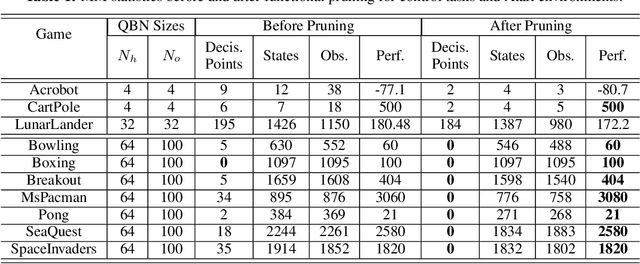
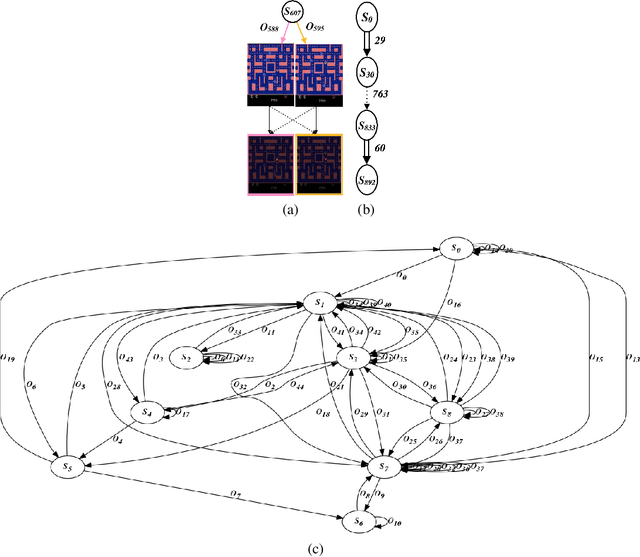
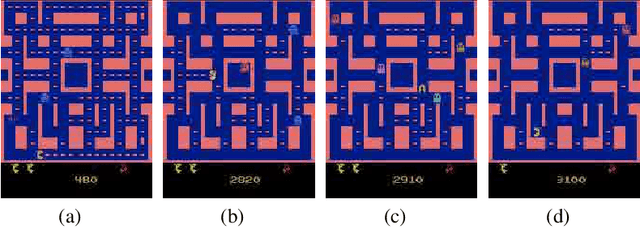
We introduce an approach for understanding finite-state machine (FSM) representations of recurrent policy networks. Recent work focused on minimizing FSMs to gain high-level insight, however, minimization can obscure a deeper understanding by merging states that are semantically distinct. Conversely, our approach starts with an unminimized machine and applies more-interpretable reductions that preserve the key decision points of the policy. We also contribute a saliency tool to attain a deeper understanding of the role of observations in the decisions. Our case studies on policies from 7 Atari games and 3 control benchmarks demonstrate that the approach can reveal insights that have not been noticed in prior work.