 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel selection for contextual bandits
Jun 03, 2019We introduce the problem of model selection for contextual bandits, wherein a learner must adapt to the complexity of the optimal policy while balancing exploration and exploitation. Our main result is a new model selection guarantee for linear contextual bandits. We work in the stochastic realizable setting with a sequence of nested linear policy classes of dimension $d_1 < d_2 < \ldots$, where the $m^\star$-th class contains the optimal policy, and we design an algorithm that achieves $\tilde{O}(T^{2/3}d^{1/3}_{m^\star})$ regret with no prior knowledge of the optimal dimension $d_{m^\star}$. The algorithm also achieves regret $\tilde{O}(T^{3/4} + \sqrt{Td_{m^\star}})$, which is optimal for $d_{m^{\star}}\geq{}\sqrt{T}$. This is the first contextual bandit model selection result with non-vacuous regret for all values of $d_{m^\star}$ and, to the best of our knowledge, is the first guarantee of its type in any contextual bandit setting. The core of the algorithm is a new estimator for the gap in best loss achievable by two linear policy classes, which we show admits a convergence rate faster than what is required to learn either class.
Contextual Bandits with Continuous Actions: Smoothing, Zooming, and Adapting
Feb 05, 2019
We study contextual bandit learning with an abstract policy class and continuous action space. We obtain two qualitatively different regret bounds: one competes with a smoothed version of the policy class under no continuity assumptions, while the other requires standard Lipschitz assumptions. Both bounds exhibit data-dependent "zooming" behavior and, with no tuning, yield improved guarantees for benign problems. We also study adapting to unknown smoothness parameters, establishing a price-of-adaptivity and deriving optimal adaptive algorithms that require no additional information.
Provably efficient RL with Rich Observations via Latent State Decoding
Jan 25, 2019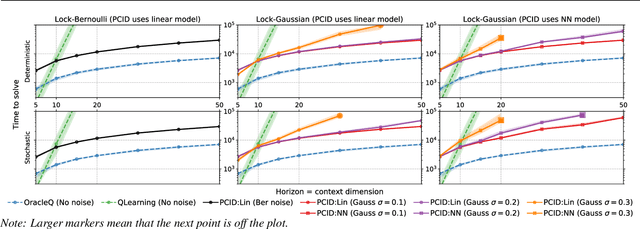
We study the exploration problem in episodic MDPs with rich observations generated from a small number of latent states. Under certain identifiability assumptions, we demonstrate how to estimate a mapping from the observations to latent states inductively through a sequence of regression and clustering steps---where previously decoded latent states provide labels for later regression problems---and use it to construct good exploration policies. We provide finite-sample guarantees on the quality of the learned state decoding function and exploration policies, and complement our theory with an empirical evaluation on a class of hard exploration problems. Our method exponentially improves over $Q$-learning with na\"ive exploration, even when $Q$-learning has cheating access to latent states.
Model-Based Reinforcement Learning in Contextual Decision Processes
Nov 21, 2018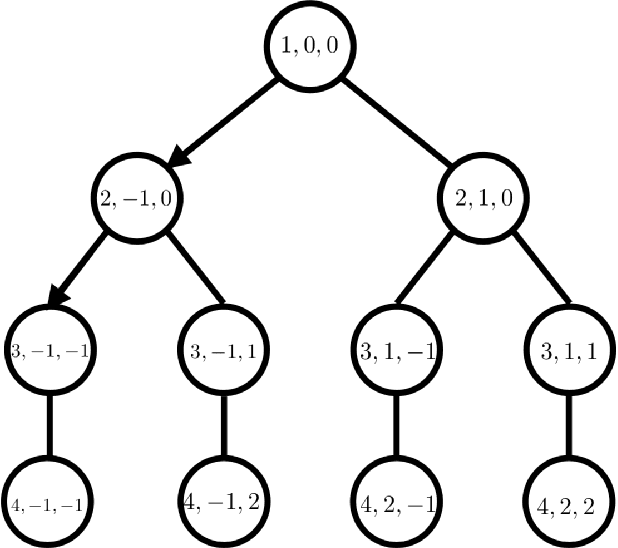
We study the sample complexity of model-based reinforcement learning in general contextual decision processes. We design new algorithms for RL with an abstract model class and analyze their statistical properties. Our algorithms have sample complexity governed by a new structural parameter called the witness rank, which we show to be small in several settings of interest, including Factored MDPs and reactive POMDPs. We also show that the witness rank of a problem is never larger than the recently proposed Bellman rank parameter governing the sample complexity of the model-free algorithm OLIVE (Jiang et al., 2017), the only other provably sample efficient algorithm at this level of generality. Focusing on the special case of Factored MDPs, we prove an exponential lower bound for all model-free approaches, including OLIVE, which when combined with our algorithmic results demonstrates exponential separation between model-based and model-free RL in some rich-observation settings.
Contextual bandits with surrogate losses: Margin bounds and efficient algorithms
Nov 04, 2018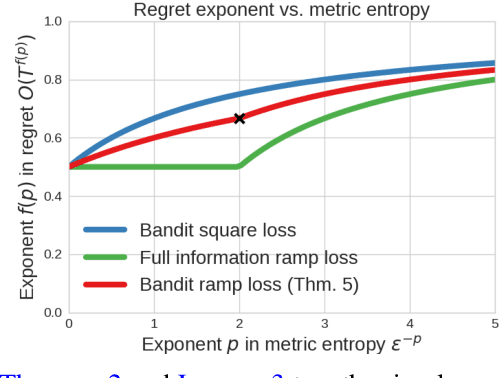
We use surrogate losses to obtain several new regret bounds and new algorithms for contextual bandit learning. Using the ramp loss, we derive new margin-based regret bounds in terms of standard sequential complexity measures of a benchmark class of real-valued regression functions. Using the hinge loss, we derive an efficient algorithm with a $\sqrt{dT}$-type mistake bound against benchmark policies induced by $d$-dimensional regressors. Under realizability assumptions, our results also yield classical regret bounds.
On Oracle-Efficient PAC RL with Rich Observations
Oct 31, 2018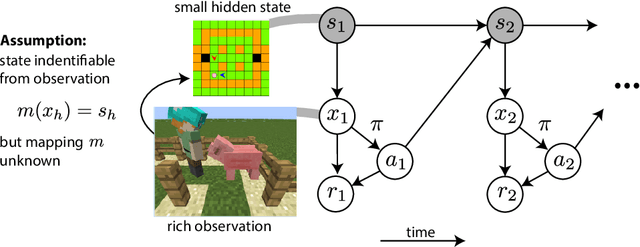
We study the computational tractability of PAC reinforcement learning with rich observations. We present new provably sample-efficient algorithms for environments with deterministic hidden state dynamics and stochastic rich observations. These methods operate in an oracle model of computation -- accessing policy and value function classes exclusively through standard optimization primitives -- and therefore represent computationally efficient alternatives to prior algorithms that require enumeration. With stochastic hidden state dynamics, we prove that the only known sample-efficient algorithm, OLIVE, cannot be implemented in the oracle model. We also present several examples that illustrate fundamental challenges of tractable PAC reinforcement learning in such general settings.
Semiparametric Contextual Bandits
Jul 16, 2018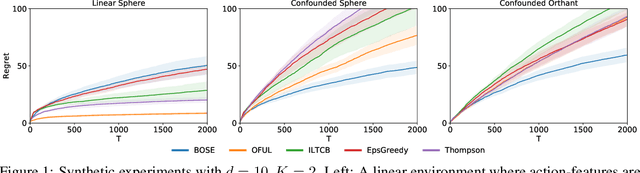
This paper studies semiparametric contextual bandits, a generalization of the linear stochastic bandit problem where the reward for an action is modeled as a linear function of known action features confounded by an non-linear action-independent term. We design new algorithms that achieve $\tilde{O}(d\sqrt{T})$ regret over $T$ rounds, when the linear function is $d$-dimensional, which matches the best known bounds for the simpler unconfounded case and improves on a recent result of Greenewald et al. (2017). Via an empirical evaluation, we show that our algorithms outperform prior approaches when there are non-linear confounding effects on the rewards. Technically, our algorithms use a new reward estimator inspired by doubly-robust approaches and our proofs require new concentration inequalities for self-normalized martingales.
Myopic Bayesian Design of Experiments via Posterior Sampling and Probabilistic Programming
May 25, 2018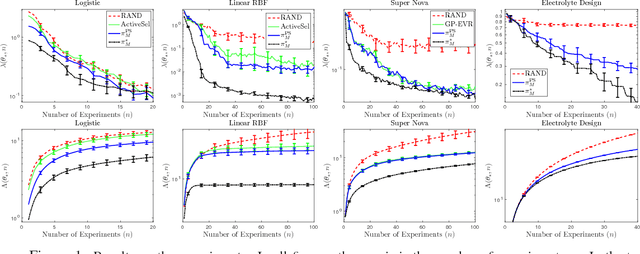
We design a new myopic strategy for a wide class of sequential design of experiment (DOE) problems, where the goal is to collect data in order to to fulfil a certain problem specific goal. Our approach, Myopic Posterior Sampling (MPS), is inspired by the classical posterior (Thompson) sampling algorithm for multi-armed bandits and leverages the flexibility of probabilistic programming and approximate Bayesian inference to address a broad set of problems. Empirically, this general-purpose strategy is competitive with more specialised methods in a wide array of DOE tasks, and more importantly, enables addressing complex DOE goals where no existing method seems applicable. On the theoretical side, we leverage ideas from adaptive submodularity and reinforcement learning to derive conditions under which MPS achieves sublinear regret against natural benchmark policies.
Disagreement-based combinatorial pure exploration: Efficient algorithms and an analysis with localization
Nov 30, 2017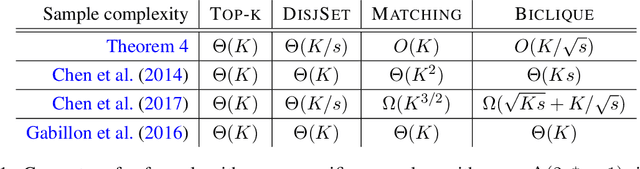
We design new algorithms for the combinatorial pure exploration problem in the multi-arm bandit framework. In this problem, we are given K distributions and a collection of subsets $\mathcal{V} \subset 2^K$ of these distributions, and we would like to find the subset $v \in \mathcal{V}$ that has largest cumulative mean, while collecting, in a sequential fashion, as few samples from the distributions as possible. We study both the fixed budget and fixed confidence settings, and our algorithms essentially achieve state-of-the-art performance in all settings, improving on previous guarantees for structures like matchings and submatrices that have large augmenting sets. Moreover, our algorithms can be implemented efficiently whenever the decision set V admits linear optimization. Our analysis involves precise concentration-of-measure arguments and a new algorithm for linear programming with exponentially many constraints.
Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning
Nov 15, 2017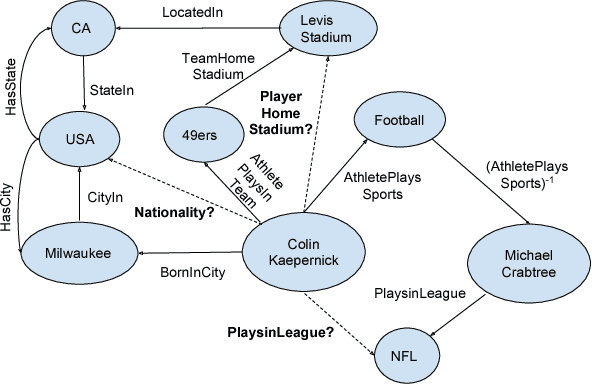
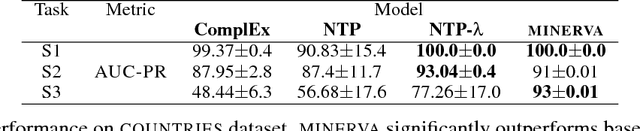
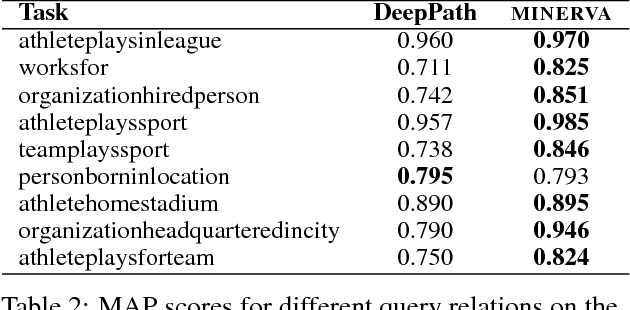
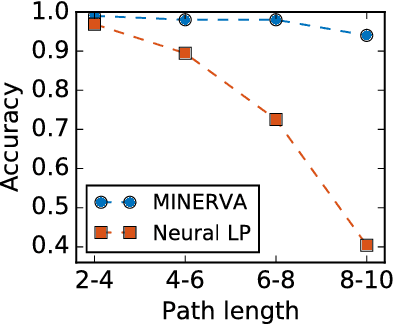
Knowledge bases (KB), both automatically and manually constructed, are often incomplete --- many valid facts can be inferred from the KB by synthesizing existing information. A popular approach to KB completion is to infer new relations by combinatory reasoning over the information found along other paths connecting a pair of entities. Given the enormous size of KBs and the exponential number of paths, previous path-based models have considered only the problem of predicting a missing relation given two entities or evaluating the truth of a proposed triple. Additionally, these methods have traditionally used random paths between fixed entity pairs or more recently learned to pick paths between them. We propose a new algorithm MINERVA, which addresses the much more difficult and practical task of answering questions where the relation is known, but only one entity. Since random walks are impractical in a setting with combinatorially many destinations from a start node, we present a neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths. Empirically, this approach obtains state-of-the-art results on several datasets, significantly outperforming prior methods.