 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparser, Faster, Lighter Transformer Language Models
Mar 24, 2026Scaling autoregressive large language models (LLMs) has driven unprecedented progress but comes with vast computational costs. In this work, we tackle these costs by leveraging unstructured sparsity within an LLM's feedforward layers, the components accounting for most of the model parameters and execution FLOPs. To achieve this, we introduce a new sparse packing format and a set of CUDA kernels designed to seamlessly integrate with the optimized execution pipelines of modern GPUs, enabling efficient sparse computation during LLM inference and training. To substantiate our gains, we provide a quantitative study of LLM sparsity, demonstrating that simple L1 regularization can induce over 99% sparsity with negligible impact on downstream performance. When paired with our kernels, we show that these sparsity levels translate into substantial throughput, energy efficiency, and memory usage benefits that increase with model scale. We will release all code and kernels under an open-source license to promote adoption and accelerate research toward establishing sparsity as a practical axis for improving the efficiency and scalability of modern foundation models.
CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
Aug 29, 2023



Approximate Nearest Neighbor Search (ANNS) plays a critical role in various disciplines spanning data mining and artificial intelligence, from information retrieval and computer vision to natural language processing and recommender systems. Data volumes have soared in recent years and the computational cost of an exhaustive exact nearest neighbor search is often prohibitive, necessitating the adoption of approximate techniques. The balanced performance and recall of graph-based approaches have more recently garnered significant attention in ANNS algorithms, however, only a few studies have explored harnessing the power of GPUs and multi-core processors despite the widespread use of massively parallel and general-purpose computing. To bridge this gap, we introduce a novel parallel computing hardware-based proximity graph and search algorithm. By leveraging the high-performance capabilities of modern hardware, our approach achieves remarkable efficiency gains. In particular, our method surpasses existing CPU and GPU-based methods in constructing the proximity graph, demonstrating higher throughput in both large- and small-batch searches while maintaining compatible accuracy. In graph construction time, our method, CAGRA, is 2.2~27x faster than HNSW, which is one of the CPU SOTA implementations. In large-batch query throughput in the 90% to 95% recall range, our method is 33~77x faster than HNSW, and is 3.8~8.8x faster than the SOTA implementations for GPU. For a single query, our method is 3.4~53x faster than HNSW at 95% recall.
Scalable and Practical Natural Gradient for Large-Scale Deep Learning
Feb 13, 2020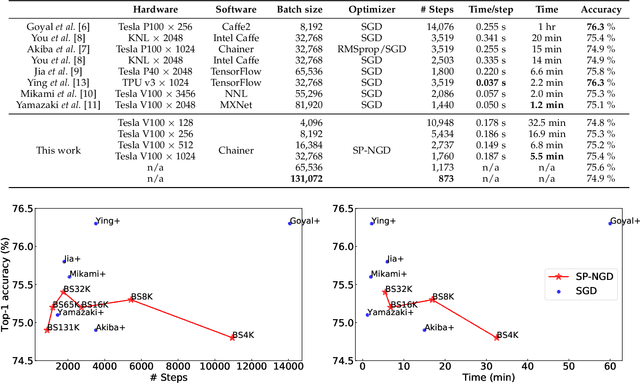
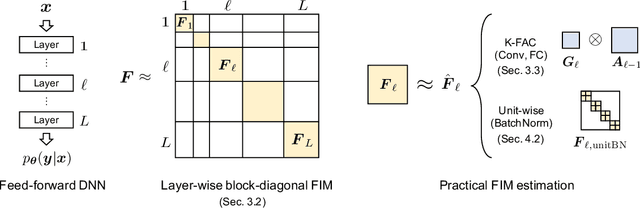

Large-scale distributed training of deep neural networks results in models with worse generalization performance as a result of the increase in the effective mini-batch size. Previous approaches attempt to address this problem by varying the learning rate and batch size over epochs and layers, or ad hoc modifications of batch normalization. We propose Scalable and Practical Natural Gradient Descent (SP-NGD), a principled approach for training models that allows them to attain similar generalization performance to models trained with first-order optimization methods, but with accelerated convergence. Furthermore, SP-NGD scales to large mini-batch sizes with a negligible computational overhead as compared to first-order methods. We evaluated SP-NGD on a benchmark task where highly optimized first-order methods are available as references: training a ResNet-50 model for image classification on ImageNet. We demonstrate convergence to a top-1 validation accuracy of 75.4% in 5.5 minutes using a mini-batch size of 32,768 with 1,024 GPUs, as well as an accuracy of 74.9% with an extremely large mini-batch size of 131,072 in 873 steps of SP-NGD.
Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs
Dec 05, 2018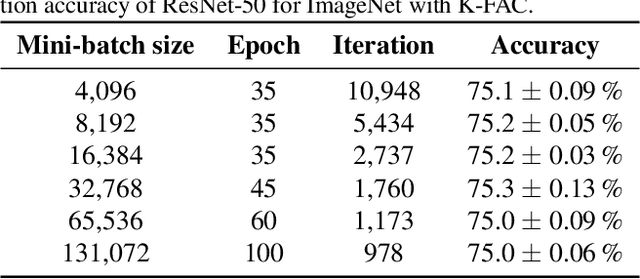
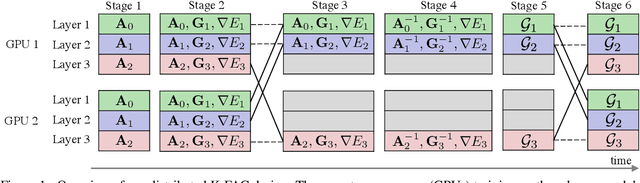
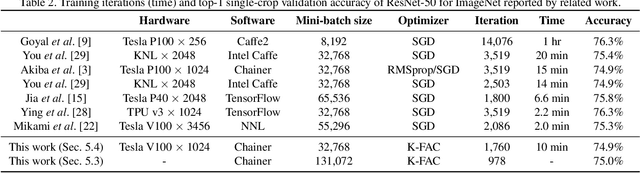
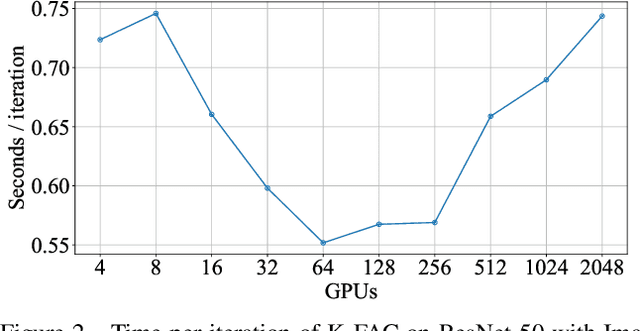
Large-scale distributed training of deep neural networks suffer from the generalization gap caused by the increase in the effective mini-batch size. Previous approaches try to solve this problem by varying the learning rate and batch size over epochs and layers, or some ad hoc modification of the batch normalization. We propose an alternative approach using a second-order optimization method that shows similar generalization capability to first-order methods, but converges faster and can handle larger mini-batches. To test our method on a benchmark where highly optimized first-order methods are available as references, we train ResNet-50 on ImageNet. We converged to 75% Top-1 validation accuracy in 35 epochs for mini-batch sizes under 16,384, and achieved 75% even with a mini-batch size of 131,072, which took 100 epochs.