 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiRL: Participant-Invariant Representation Learning for Healthcare Using Maximum Mean Discrepancy and Triplet Loss
Feb 17, 2023Due to individual heterogeneity, person-specific models are usually achieving better performance than generic (one-size-fits-all) models in data-driven health applications. However, generic models are usually preferable in real-world applications, due to the difficulties of developing person-specific models, such as new-user-adaptation issues and system complexities. To improve the performance of generic models, we propose a Participant-invariant Representation Learning (PiRL) framework, which utilizes maximum mean discrepancy (MMD) loss and domain-adversarial training to encourage the model to learn participant-invariant representations. Further, to avoid trivial solutions in the learned representations, a triplet loss based constraint is used for the model to learn the label-distinguishable embeddings. The proposed framework is evaluated on two public datasets (CLAS and Apnea-ECG), and significant performance improvements are achieved compared to the baseline models.
PiRL: Participant-Invariant Representation Learning for Healthcare
Nov 21, 2022Due to individual heterogeneity, performance gaps are observed between generic (one-size-fits-all) models and person-specific models in data-driven health applications. However, in real-world applications, generic models are usually more favorable due to new-user-adaptation issues and system complexities, etc. To improve the performance of the generic model, we propose a representation learning framework that learns participant-invariant representations, named PiRL. The proposed framework utilizes maximum mean discrepancy (MMD) loss and domain-adversarial training to encourage the model to learn participant-invariant representations. Further, a triplet loss, which constrains the model for inter-class alignment of the representations, is utilized to optimize the learned representations for downstream health applications. We evaluated our frameworks on two public datasets related to physical and mental health, for detecting sleep apnea and stress, respectively. As preliminary results, we found the proposed approach shows around a 5% increase in accuracy compared to the baseline.
Empirical Evaluation of Data Augmentations for Biobehavioral Time Series Data with Deep Learning
Oct 13, 2022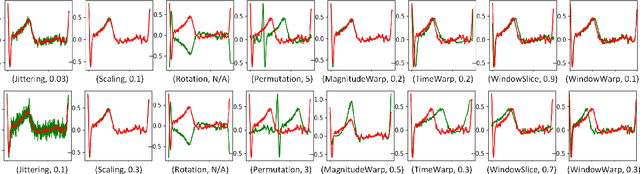
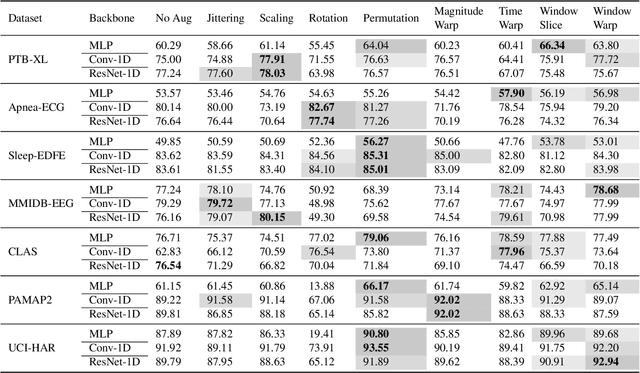
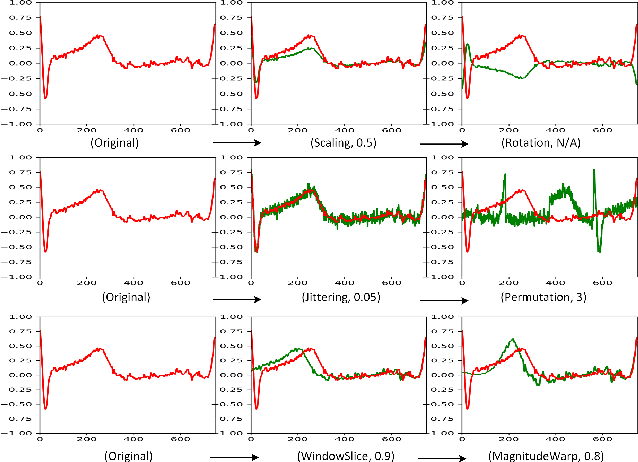
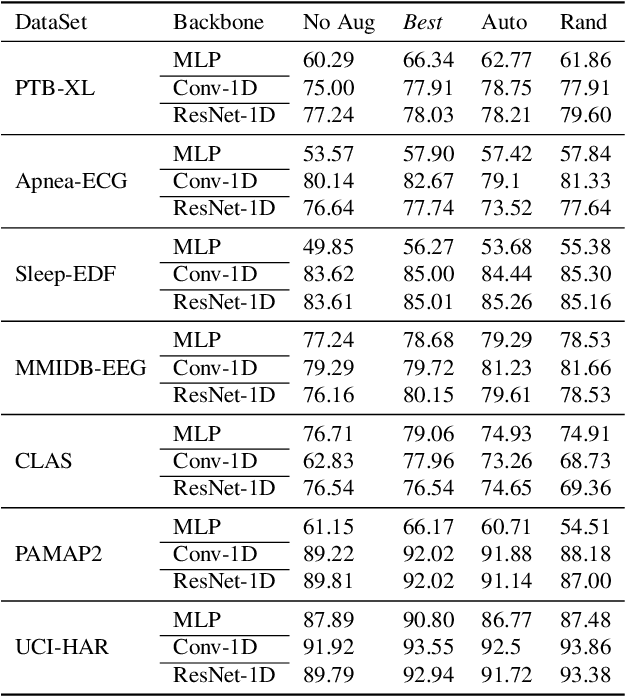
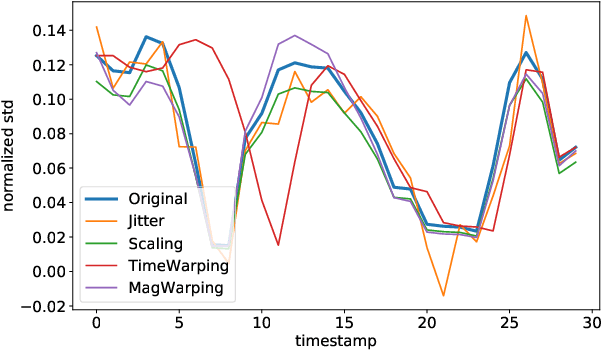
Deep learning has performed remarkably well on many tasks recently. However, the superior performance of deep models relies heavily on the availability of a large number of training data, which limits the wide adaptation of deep models on various clinical and affective computing tasks, as the labeled data are usually very limited. As an effective technique to increase the data variability and thus train deep models with better generalization, data augmentation (DA) is a critical step for the success of deep learning models on biobehavioral time series data. However, the effectiveness of various DAs for different datasets with different tasks and deep models is understudied for biobehavioral time series data. In this paper, we first systematically review eight basic DA methods for biobehavioral time series data, and evaluate the effects on seven datasets with three backbones. Next, we explore adapting more recent DA techniques (i.e., automatic augmentation, random augmentation) to biobehavioral time series data by designing a new policy architecture applicable to time series data. Last, we try to answer the question of why a DA is effective (or not) by first summarizing two desired attributes for augmentations (challenging and faithful), and then utilizing two metrics to quantitatively measure the corresponding attributes, which can guide us in the search for more effective DA for biobehavioral time series data by designing more challenging but still faithful transformations. Our code and results are available at Link.
LEAVES: Learning Views for Time-Series Data in Contrastive Learning
Oct 13, 2022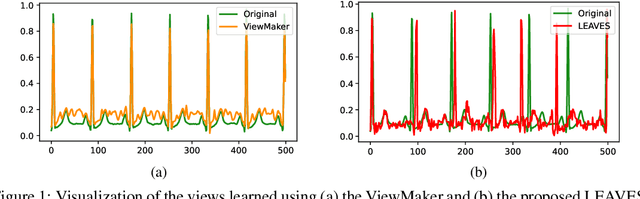

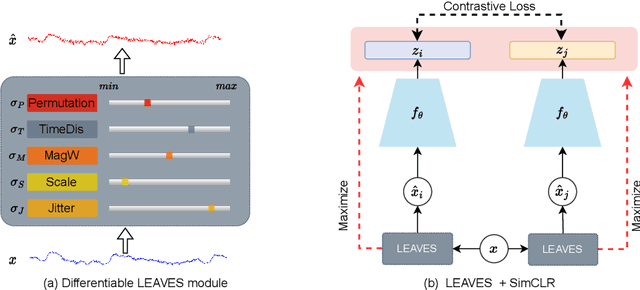

Contrastive learning, a self-supervised learning method that can learn representations from unlabeled data, has been developed promisingly. Many methods of contrastive learning depend on data augmentation techniques, which generate different views from the original signal. However, tuning policies and hyper-parameters for more effective data augmentation methods in contrastive learning is often time and resource-consuming. Researchers have designed approaches to automatically generate new views for some input signals, especially on the image data. But the view-learning method is not well developed for time-series data. In this work, we propose a simple but effective module for automating view generation for time-series data in contrastive learning, named learning views for time-series data (LEAVES). The proposed module learns the hyper-parameters for augmentations using adversarial training in contrastive learning. We validate the effectiveness of the proposed method using multiple time-series datasets. The experiments demonstrate that the proposed method is more effective in finding reasonable views and performs downstream tasks better than the baselines, including manually tuned augmentation-based contrastive learning methods and SOTA methods.
Bias Reducing Multitask Learning on Mental Health Prediction
Aug 07, 2022



There has been an increase in research in developing machine learning models for mental health detection or prediction in recent years due to increased mental health issues in society. Effective use of mental health prediction or detection models can help mental health practitioners re-define mental illnesses more objectively than currently done, and identify illnesses at an earlier stage when interventions may be more effective. However, there is still a lack of standard in evaluating bias in such machine learning models in the field, which leads to challenges in providing reliable predictions and in addressing disparities. This lack of standards persists due to factors such as technical difficulties, complexities of high dimensional clinical health data, etc., which are especially true for physiological signals. This along with prior evidence of relations between some physiological signals with certain demographic identities restates the importance of exploring bias in mental health prediction models that utilize physiological signals. In this work, we aim to perform a fairness analysis and implement a multi-task learning based bias mitigation method on anxiety prediction models using ECG data. Our method is based on the idea of epistemic uncertainty and its relationship with model weights and feature space representation. Our analysis showed that our anxiety prediction base model introduced some bias with regards to age, income, ethnicity, and whether a participant is born in the U.S. or not, and our bias mitigation method performed better at reducing the bias in the model, when compared to the reweighting mitigation technique. Our analysis on feature importance also helped identify relationships between heart rate variability and multiple demographic groupings.
Exploiting Social Graph Networks for Emotion Prediction
Jul 12, 2022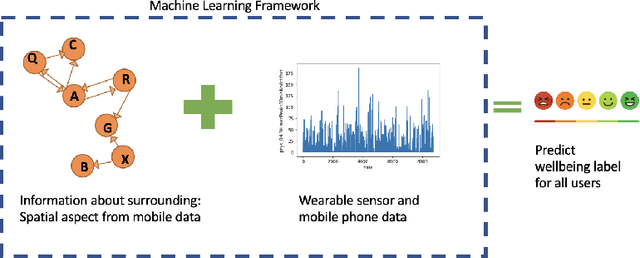
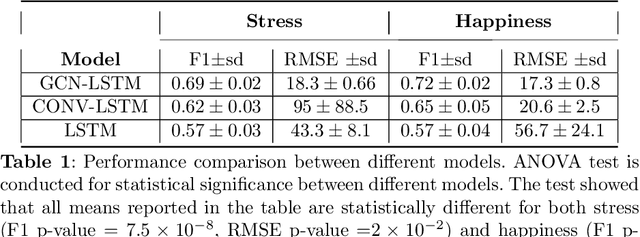
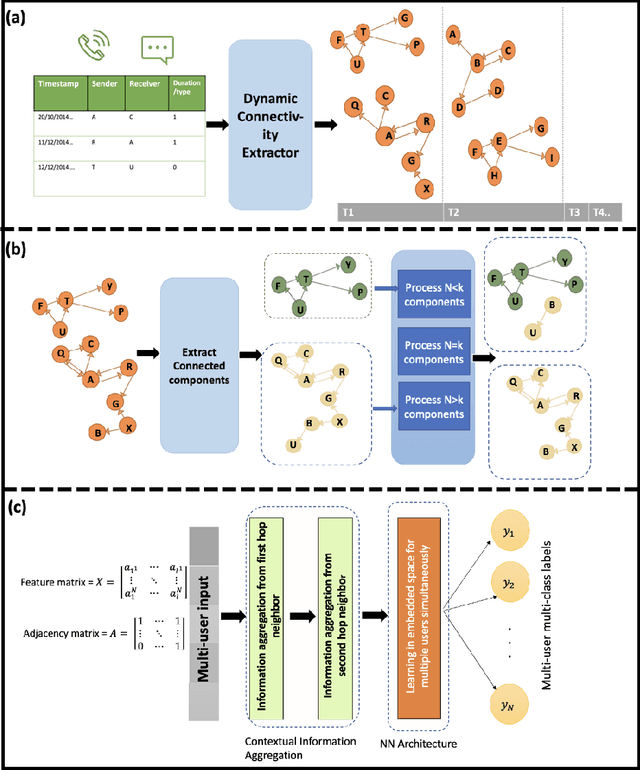
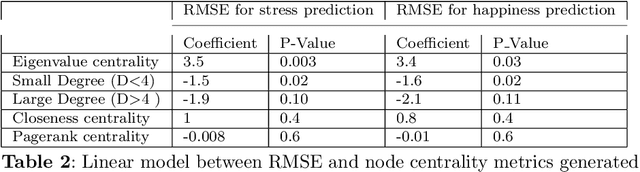
Emotion prediction plays an essential role in mental health and emotion-aware computing. The complex nature of emotion resulting from its dependency on a person's physiological health, mental state, and his surroundings makes its prediction a challenging task. In this work, we utilize mobile sensing data to predict happiness and stress. In addition to a person's physiological features, we also incorporate the environment's impact through weather and social network. To this end, we leverage phone data to construct social networks and develop a machine learning architecture that aggregates information from multiple users of the graph network and integrates it with the temporal dynamics of data to predict emotion for all the users. The construction of social networks does not incur additional cost in terms of EMAs or data collection from users and doesn't raise privacy concerns. We propose an architecture that automates the integration of a user's social network affect prediction, is capable of dealing with the dynamic distribution of real-life social networks, making it scalable to large-scale networks. Our extensive evaluation highlights the improvement provided by the integration of social networks. We further investigate the impact of graph topology on model's performance.
Psychotic Relapse Prediction in Schizophrenia Patients using A Mobile Sensing-based Supervised Deep Learning Model
May 24, 2022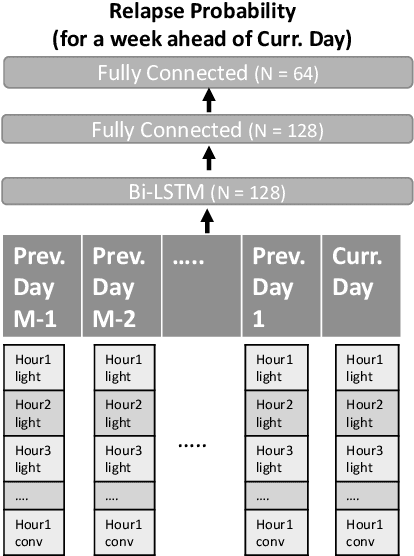
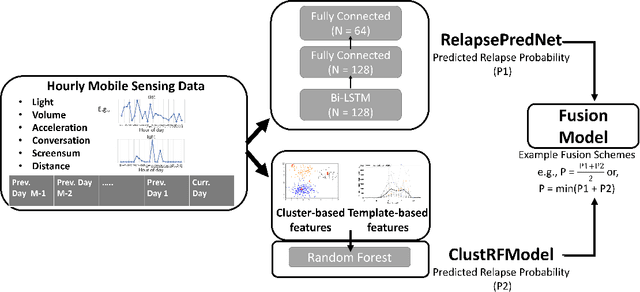
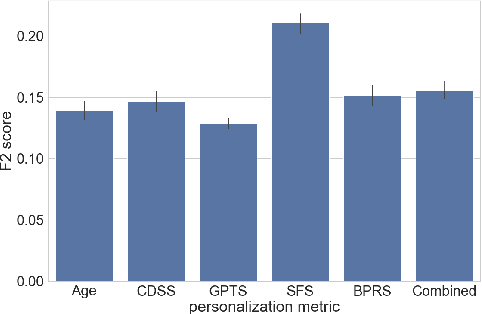
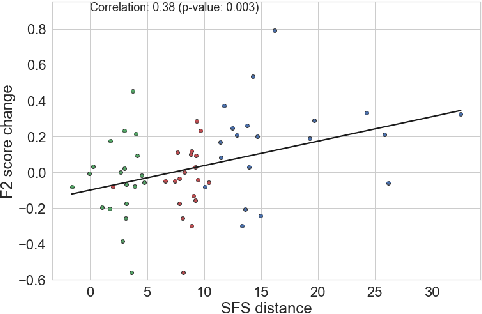
Mobile sensing-based modeling of behavioral changes could predict an oncoming psychotic relapse in schizophrenia patients for timely interventions. Deep learning models could complement existing non-deep learning models for relapse prediction by modeling latent behavioral features relevant to the prediction. However, given the inter-individual behavioral differences, model personalization might be required for a predictive model. In this work, we propose RelapsePredNet, a Long Short-Term Memory (LSTM) neural network-based model for relapse prediction. The model is personalized for a particular patient by training using data from patients most similar to the given patient. Several demographics and baseline mental health scores were considered as personalization metrics to define patient similarity. We investigated the effect of personalization on training dataset characteristics, learned embeddings, and relapse prediction performance. We compared RelapsePredNet with a deep learning-based anomaly detection model for relapse prediction. Further, we investigated if RelapsePredNet could complement ClusterRFModel (a random forest model leveraging clustering and template features proposed in prior work) in a fusion model, by identifying latent behavioral features relevant for relapse prediction. The CrossCheck dataset consisting of continuous mobile sensing data obtained from 63 schizophrenia patients, each monitored for up to a year, was used for our evaluations. The proposed RelapsePredNet outperformed the deep learning-based anomaly detection model for relapse prediction. The F2 score for prediction were 0.21 and 0.52 in the full test set and the Relapse Test Set (consisting of data from patients who have had relapse only), respectively. These corresponded to a 29.4% and 38.8% improvement compared to the existing deep learning-based model for relapse prediction.
Semi-Supervised Learning and Data Augmentation in Wearable-based Momentary Stress Detection in the Wild
Feb 22, 2022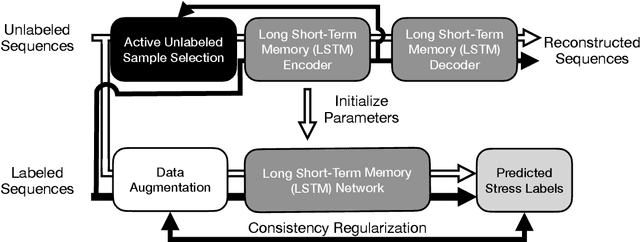
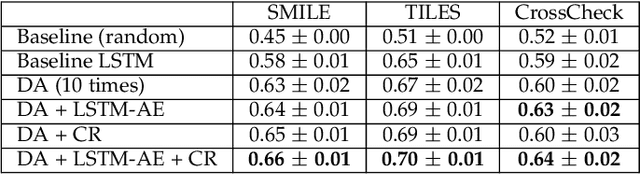
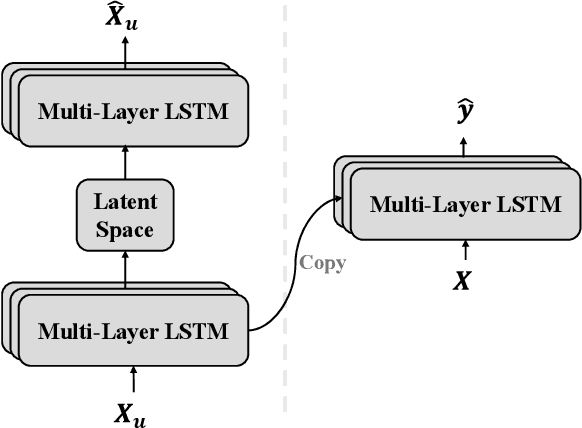
Physiological and behavioral data collected from wearable or mobile sensors have been used to estimate self-reported stress levels. Since the stress annotation usually relies on self-reports during the study, a limited amount of labeled data can be an obstacle in developing accurate and generalized stress predicting models. On the other hand, the sensors can continuously capture signals without annotations. This work investigates leveraging unlabeled wearable sensor data for stress detection in the wild. We first applied data augmentation techniques on the physiological and behavioral data to improve the robustness of supervised stress detection models. Using an auto-encoder with actively selected unlabeled sequences, we pre-trained the supervised model structure to leverage the information learned from unlabeled samples. Then, we developed a semi-supervised learning framework to leverage the unlabeled data sequences. We combined data augmentation techniques with consistency regularization, which enforces the consistency of prediction output based on augmented and original unlabeled data. We validated these methods using three wearable/mobile sensor datasets collected in the wild. Our results showed that combining the proposed methods improved stress classification performance by 7.7% to 13.8% on the evaluated datasets, compared to the baseline supervised learning models.
More to Less : Enhanced Health Recognition in the Wild with Reduced Modality of Wearable Sensors
Feb 16, 2022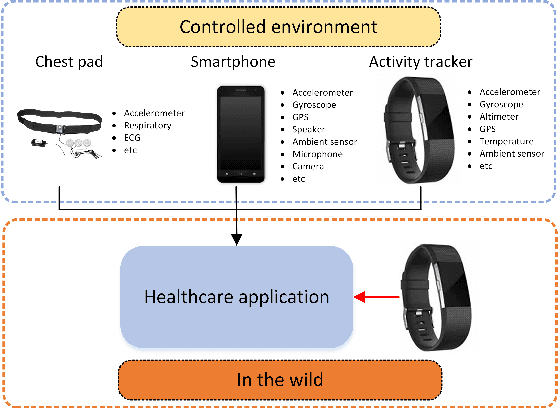
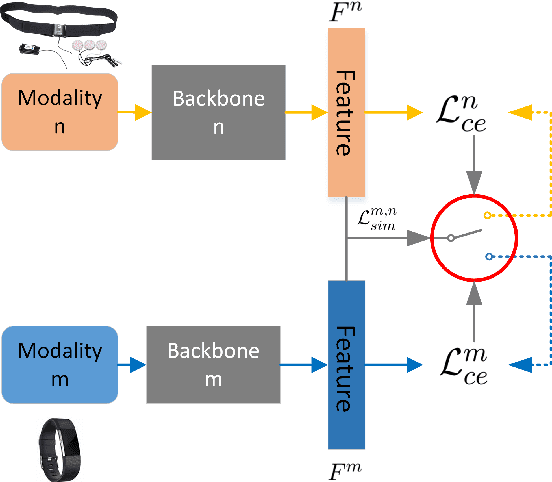
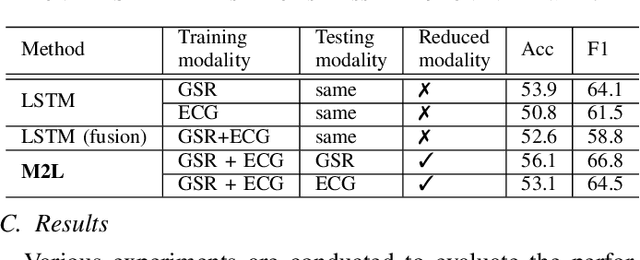
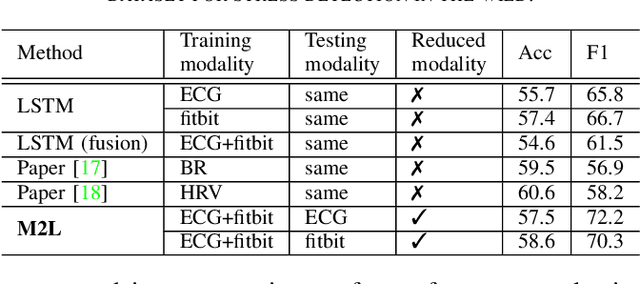
Accurately recognizing health-related conditions from wearable data is crucial for improved healthcare outcomes. To improve the recognition accuracy, various approaches have focused on how to effectively fuse information from multiple sensors. Fusing multiple sensors is a common scenario in many applications, but may not always be feasible in real-world scenarios. For example, although combining bio-signals from multiple sensors (i.e., a chest pad sensor and a wrist wearable sensor) has been proved effective for improved performance, wearing multiple devices might be impractical in the free-living context. To solve the challenges, we propose an effective more to less (M2L) learning framework to improve testing performance with reduced sensors through leveraging the complementary information of multiple modalities during training. More specifically, different sensors may carry different but complementary information, and our model is designed to enforce collaborations among different modalities, where positive knowledge transfer is encouraged and negative knowledge transfer is suppressed, so that better representation is learned for individual modalities. Our experimental results show that our framework achieves comparable performance when compared with the full modalities. Our code and results will be available at https://github.com/compwell-org/More2Less.git.
Modality Fusion Network and Personalized Attention in Momentary Stress Detection in the Wild
Jul 21, 2021
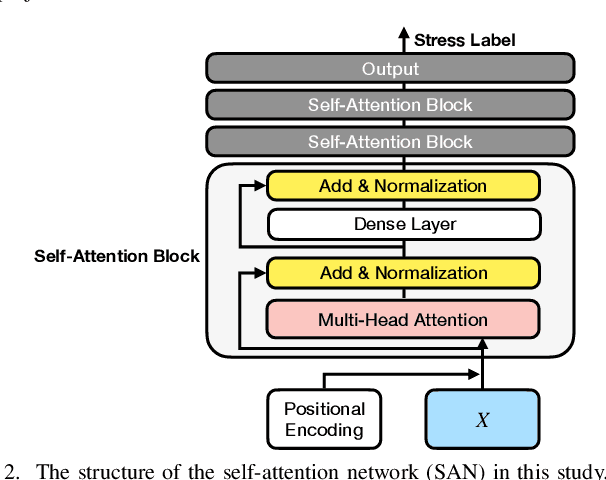
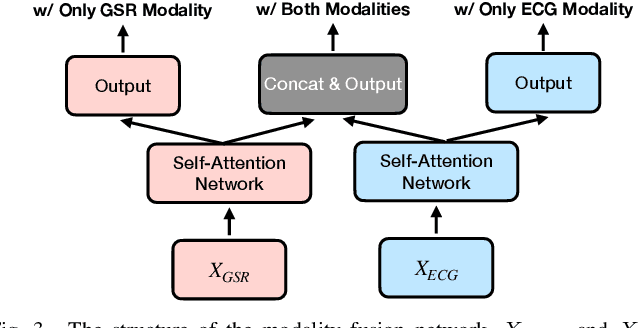
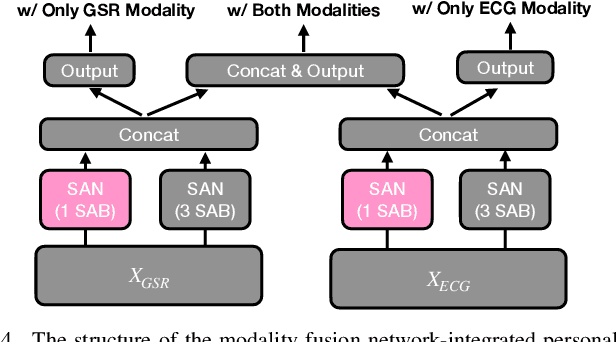
Multimodal wearable physiological data in daily life have been used to estimate self-reported stress labels. However, missing data modalities in data collection makes it challenging to leverage all the collected samples. Besides, heterogeneous sensor data and labels among individuals add challenges in building robust stress detection models. In this paper, we proposed a modality fusion network (MFN) to train models and infer self-reported binary stress labels under both complete and incomplete modality conditions. In addition, we applied personalized attention (PA) strategy to leverage personalized representation along with the generalized one-size-fits-all model. We evaluated our methods on a multimodal wearable sensor dataset (N=41) including galvanic skin response (GSR) and electrocardiogram (ECG). Compared to the baseline method using the samples with complete modalities, the performance of the MFN improved by 1.6% in f1-scores. On the other hand, the proposed PA strategy showed a 2.3% higher stress detection f1-score and approximately up to 70% reduction in personalized model parameter size (9.1 MB) compared to the previous state-of-the-art transfer learning strategy (29.3 MB).