 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust compressed sensing of generative models
Jun 18, 2020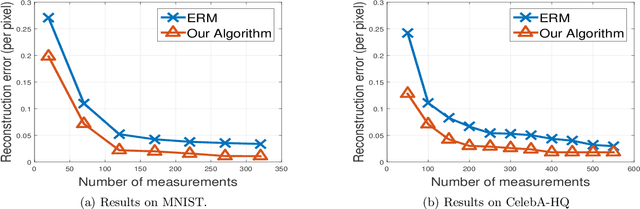
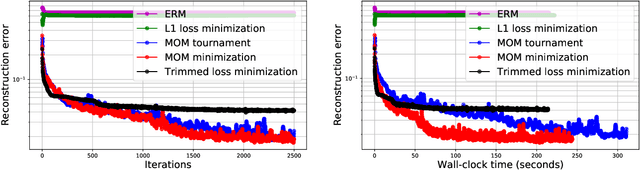

The goal of compressed sensing is to estimate a high dimensional vector from an underdetermined system of noisy linear equations. In analogy to classical compressed sensing, here we assume a generative model as a prior, that is, we assume the vector is represented by a deep generative model $G: \mathbb{R}^k \rightarrow \mathbb{R}^n$. Classical recovery approaches such as empirical risk minimization (ERM) are guaranteed to succeed when the measurement matrix is sub-Gaussian. However, when the measurement matrix and measurements are heavy-tailed or have outliers, recovery may fail dramatically. In this paper we propose an algorithm inspired by the Median-of-Means (MOM). Our algorithm guarantees recovery for heavy-tailed data, even in the presence of outliers. Theoretically, our results show our novel MOM-based algorithm enjoys the same sample complexity guarantees as ERM under sub-Gaussian assumptions. Our experiments validate both aspects of our claims: other algorithms are indeed fragile and fail under heavy-tailed and/or corrupted data, while our approach exhibits the predicted robustness.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020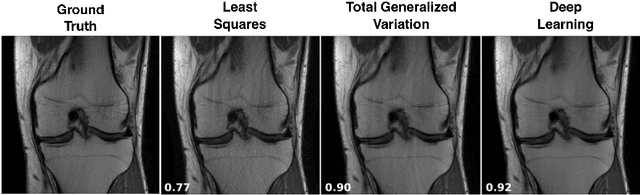
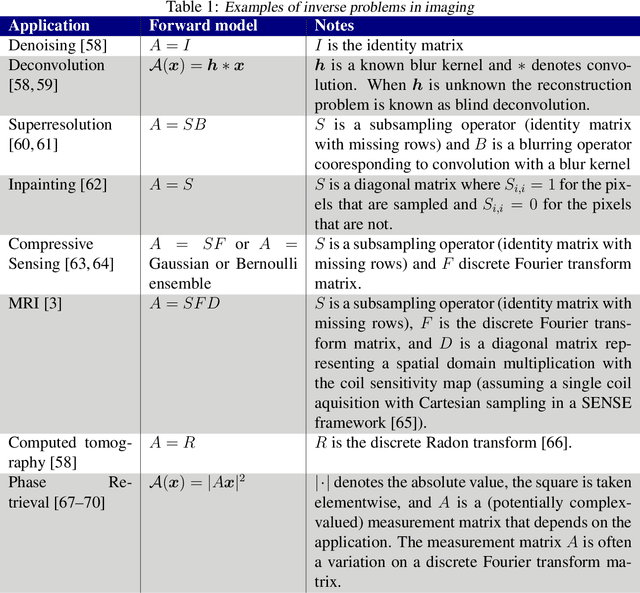

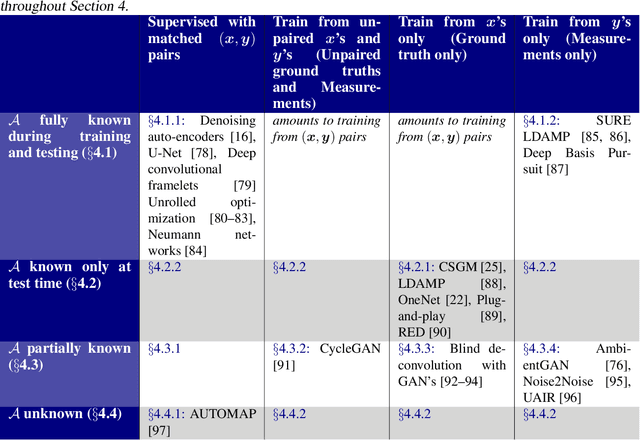
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
Inverting Deep Generative models, One layer at a time
Jun 19, 2019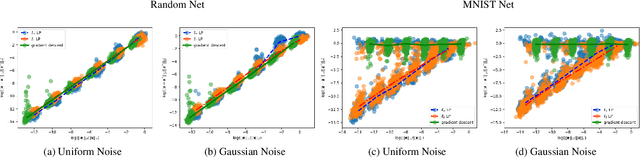

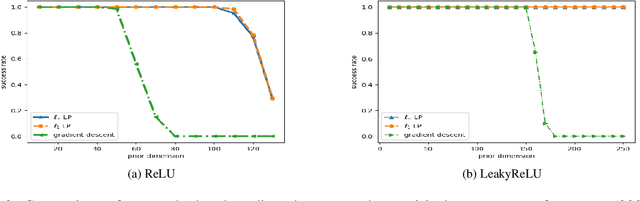

We study the problem of inverting a deep generative model with ReLU activations. Inversion corresponds to finding a latent code vector that explains observed measurements as much as possible. In most prior works this is performed by attempting to solve a non-convex optimization problem involving the generator. In this paper we obtain several novel theoretical results for the inversion problem. We show that for the realizable case, single layer inversion can be performed exactly in polynomial time, by solving a linear program. Further, we show that for multiple layers, inversion is NP-hard and the pre-image set can be non-convex. For generative models of arbitrary depth, we show that exact recovery is possible in polynomial time with high probability, if the layers are expanding and the weights are randomly selected. Very recent work analyzed the same problem for gradient descent inversion. Their analysis requires significantly higher expansion (logarithmic in the latent dimension) while our proposed algorithm can provably reconstruct even with constant factor expansion. We also provide provable error bounds for different norms for reconstructing noisy observations. Our empirical validation demonstrates that we obtain better reconstructions when the latent dimension is large.
Compressed Sensing with Deep Image Prior and Learned Regularization
Jun 17, 2018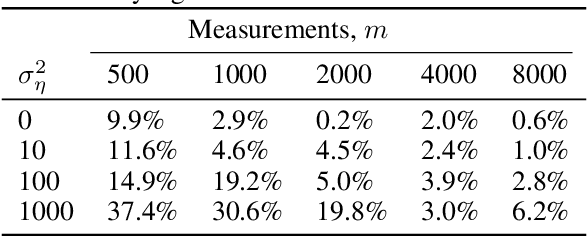
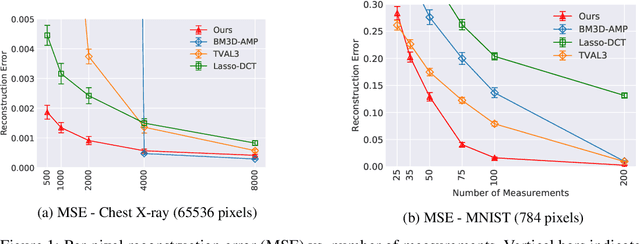

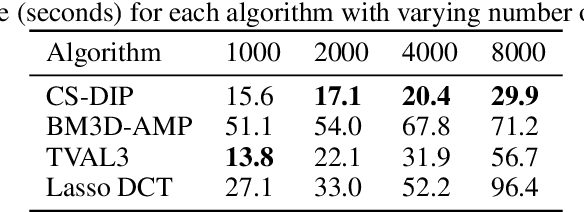
We propose a novel method for compressed sensing recovery using untrained deep generative models. Our method is based on the recently proposed Deep Image Prior (DIP), wherein the convolutional weights of the network are optimized to match the observed measurements. We show that this approach can be applied to solve any differentiable inverse problem. We also introduce a novel learned regularization technique which incorporates a small amount of prior information, further reducing the number of measurements required for a given reconstruction error. Our algorithm requires approximately 4-6x fewer measurements than classical Lasso methods. Unlike previous approaches based on generative models, our method does not require the model to be pre-trained. As such, we can apply our method to various medical imaging datasets for which data acquisition is expensive and no known generative models exist.
The Robust Manifold Defense: Adversarial Training using Generative Models
Dec 26, 2017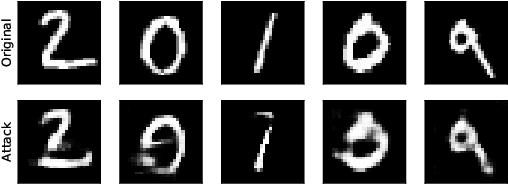
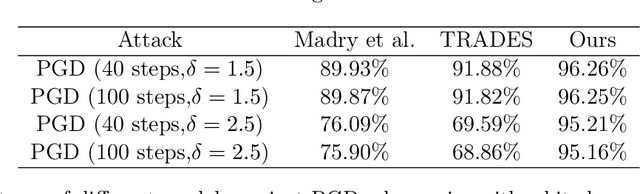

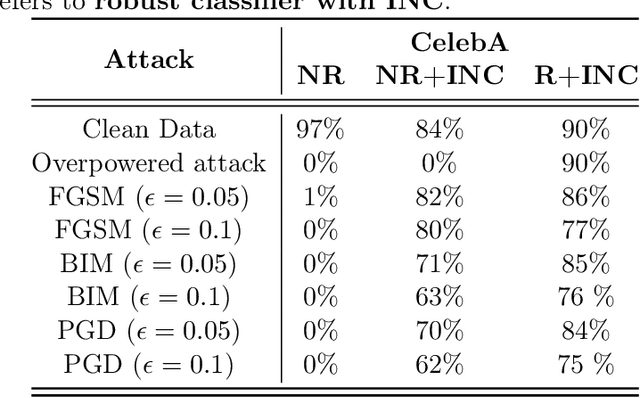
Deep neural networks are demonstrating excellent performance on several classical vision problems. However, these networks are vulnerable to adversarial examples, minutely modified images that induce arbitrary attacker-chosen output from the network. We propose a mechanism to protect against these adversarial inputs based on a generative model of the data. We introduce a pre-processing step that projects on the range of a generative model using gradient descent before feeding an input into a classifier. We show that this step provides the classifier with robustness against first-order, substitute model, and combined adversarial attacks. Using a min-max formulation, we show that there may exist adversarial examples even in the range of the generator, natural-looking images extremely close to the decision boundary for which the classifier has unjustifiedly high confidence. We show that adversarial training on the generative manifold can be used to make a classifier that is robust to these attacks. Finally, we show how our method can be applied even without a pre-trained generative model using a recent method called the deep image prior. We evaluate our method on MNIST, CelebA and Imagenet and show robustness against the current state of the art attacks.
Compressed Sensing using Generative Models
Mar 09, 2017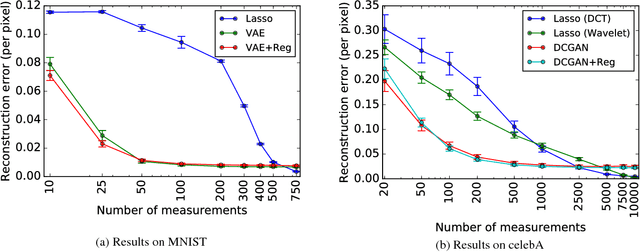
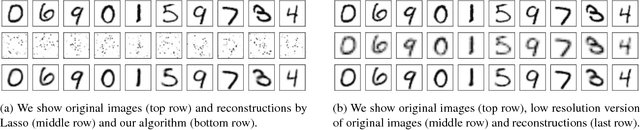


The goal of compressed sensing is to estimate a vector from an underdetermined system of noisy linear measurements, by making use of prior knowledge on the structure of vectors in the relevant domain. For almost all results in this literature, the structure is represented by sparsity in a well-chosen basis. We show how to achieve guarantees similar to standard compressed sensing but without employing sparsity at all. Instead, we suppose that vectors lie near the range of a generative model $G: \mathbb{R}^k \to \mathbb{R}^n$. Our main theorem is that, if $G$ is $L$-Lipschitz, then roughly $O(k \log L)$ random Gaussian measurements suffice for an $\ell_2/\ell_2$ recovery guarantee. We demonstrate our results using generative models from published variational autoencoder and generative adversarial networks. Our method can use $5$-$10$x fewer measurements than Lasso for the same accuracy.