 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Speech Synthesis with Adversarial Networks
Sep 26, 2019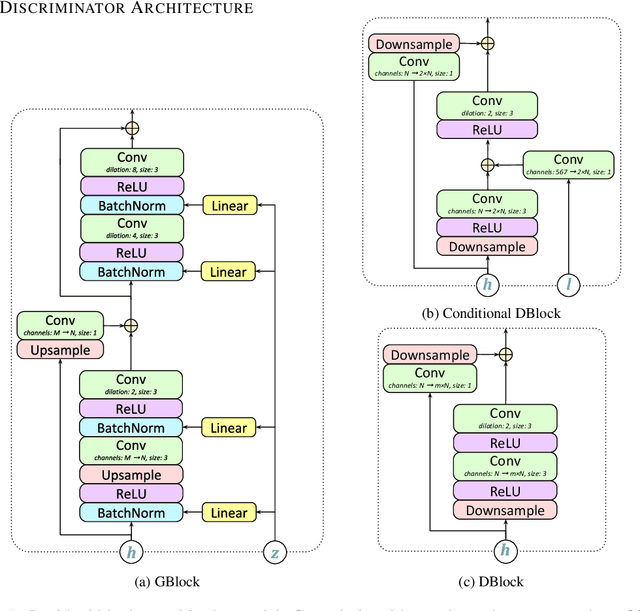
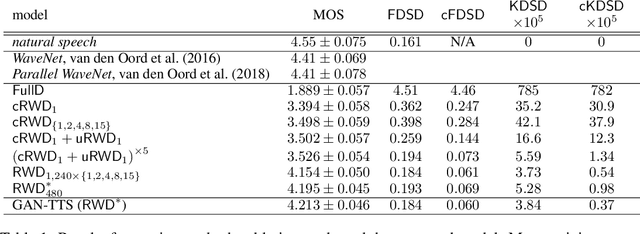
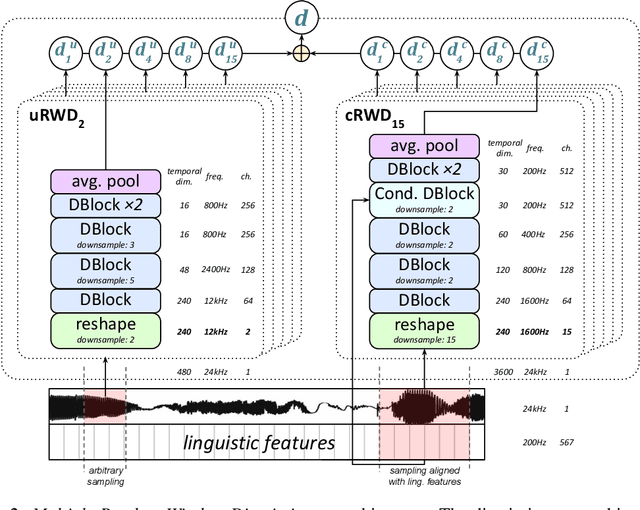
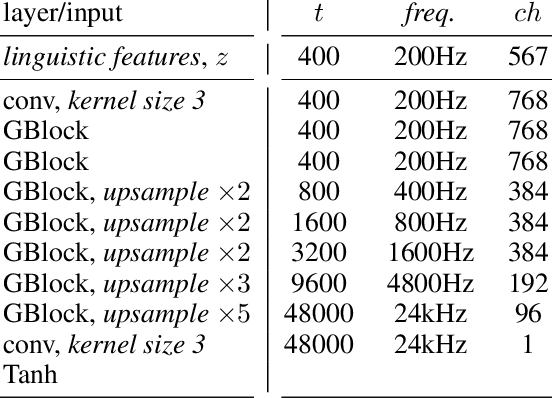
Generative adversarial networks have seen rapid development in recent years and have led to remarkable improvements in generative modelling of images. However, their application in the audio domain has received limited attention, and autoregressive models, such as WaveNet, remain the state of the art in generative modelling of audio signals such as human speech. To address this paucity, we introduce GAN-TTS, a Generative Adversarial Network for Text-to-Speech. Our architecture is composed of a conditional feed-forward generator producing raw speech audio, and an ensemble of discriminators which operate on random windows of different sizes. The discriminators analyse the audio both in terms of general realism, as well as how well the audio corresponds to the utterance that should be pronounced. To measure the performance of GAN-TTS, we employ both subjective human evaluation (MOS - Mean Opinion Score), as well as novel quantitative metrics (Fr\'echet DeepSpeech Distance and Kernel DeepSpeech Distance), which we find to be well correlated with MOS. We show that GAN-TTS is capable of generating high-fidelity speech with naturalness comparable to the state-of-the-art models, and unlike autoregressive models, it is highly parallelisable thanks to an efficient feed-forward generator. Listen to GAN-TTS reading this abstract at https://storage.googleapis.com/deepmind-media/research/abstract.wav.
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
Sep 26, 2019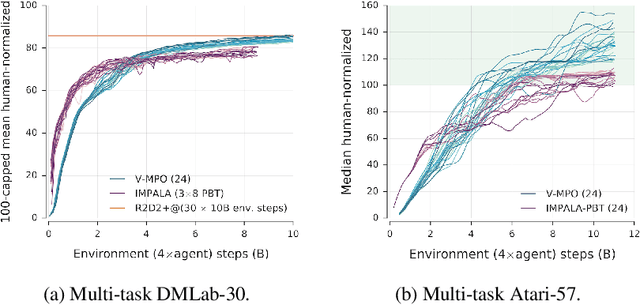
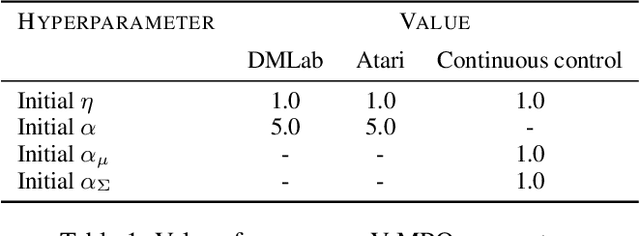
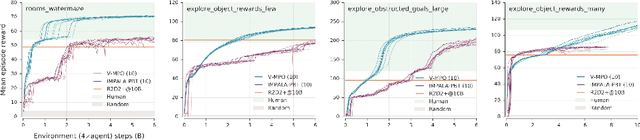

Some of the most successful applications of deep reinforcement learning to challenging domains in discrete and continuous control have used policy gradient methods in the on-policy setting. However, policy gradients can suffer from large variance that may limit performance, and in practice require carefully tuned entropy regularization to prevent policy collapse. As an alternative to policy gradient algorithms, we introduce V-MPO, an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) that performs policy iteration based on a learned state-value function. We show that V-MPO surpasses previously reported scores for both the Atari-57 and DMLab-30 benchmark suites in the multi-task setting, and does so reliably without importance weighting, entropy regularization, or population-based tuning of hyperparameters. On individual DMLab and Atari levels, the proposed algorithm can achieve scores that are substantially higher than has previously been reported. V-MPO is also applicable to problems with high-dimensional, continuous action spaces, which we demonstrate in the context of learning to control simulated humanoids with 22 degrees of freedom from full state observations and 56 degrees of freedom from pixel observations, as well as example OpenAI Gym tasks where V-MPO achieves substantially higher asymptotic scores than previously reported.
Efficient Video Generation on Complex Datasets
Jul 15, 2019
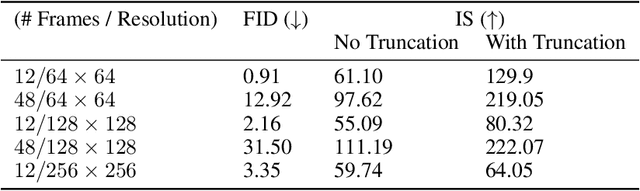

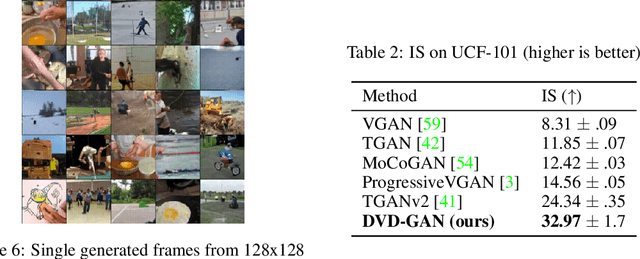
Generative models of natural images have progressed towards high fidelity samples by the strong leveraging of scale. We attempt to carry this success to the field of video modeling by showing that large Generative Adversarial Networks trained on the complex Kinetics-600 dataset are able to produce video samples of substantially higher complexity than previous work. Our proposed network, Dual Video Discriminator GAN (DVD-GAN), scales to longer and higher resolution videos by leveraging a computationally efficient decomposition of its discriminator. We evaluate on the related tasks of video synthesis and video prediction, and achieve new state of the art Frechet Inception Distance on prediction for Kinetics-600, as well as state of the art Inception Score for synthesis on the UCF-101 dataset, alongside establishing a number of strong baselines on Kinetics-600.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019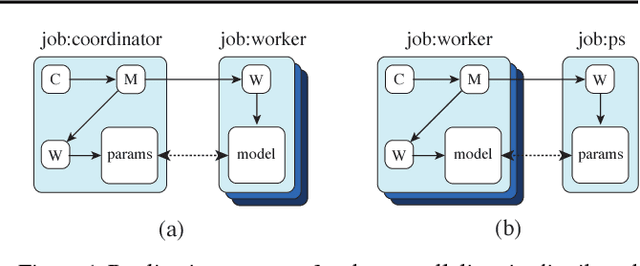

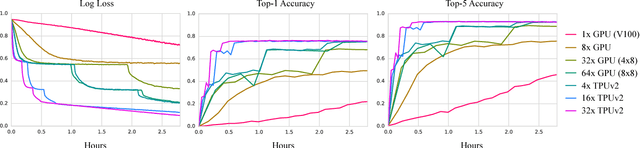
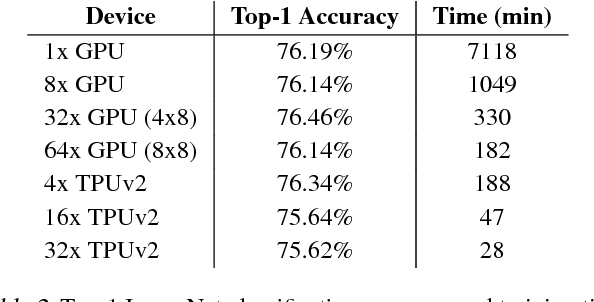
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).