 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigging Deep into the layers of CNNs: In Search of How CNNs Achieve View Invariance
Jun 20, 2016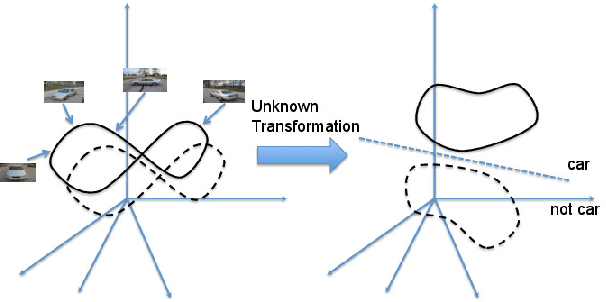
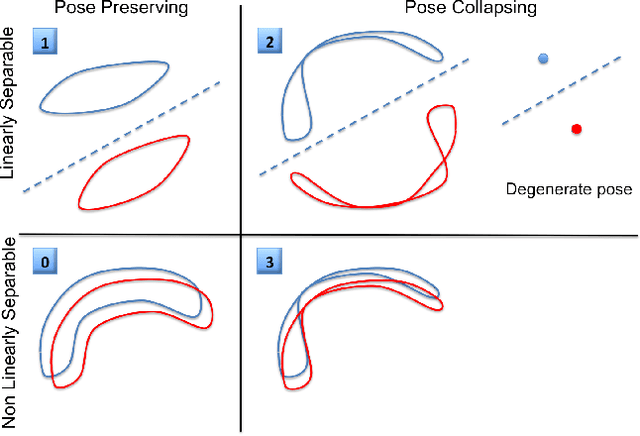
This paper is focused on studying the view-manifold structure in the feature spaces implied by the different layers of Convolutional Neural Networks (CNN). There are several questions that this paper aims to answer: Does the learned CNN representation achieve viewpoint invariance? How does it achieve viewpoint invariance? Is it achieved by collapsing the view manifolds, or separating them while preserving them? At which layer is view invariance achieved? How can the structure of the view manifold at each layer of a deep convolutional neural network be quantified experimentally? How does fine-tuning of a pre-trained CNN on a multi-view dataset affect the representation at each layer of the network? In order to answer these questions we propose a methodology to quantify the deformation and degeneracy of view manifolds in CNN layers. We apply this methodology and report interesting results in this paper that answer the aforementioned questions.
Convolutional Models for Joint Object Categorization and Pose Estimation
Apr 19, 2016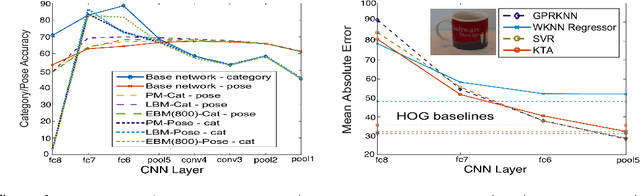
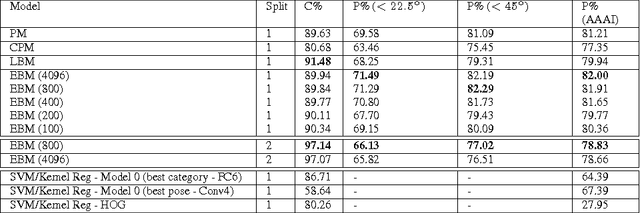
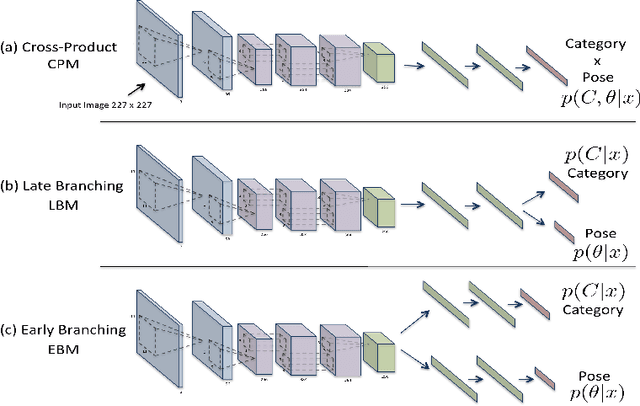

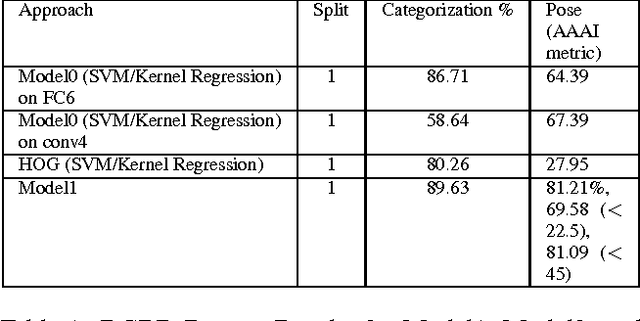
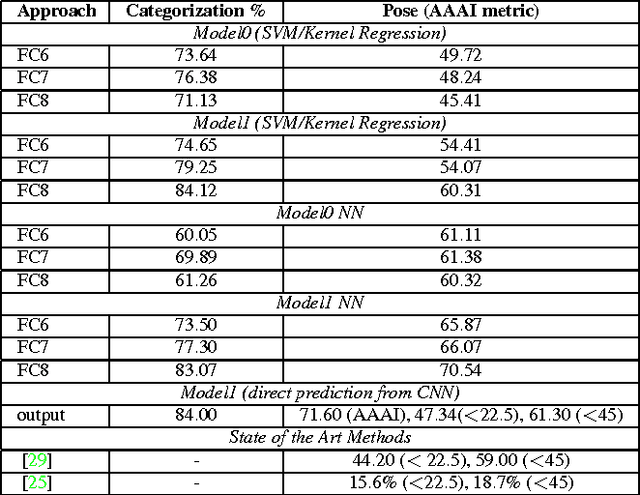
In the task of Object Recognition, there exists a dichotomy between the categorization of objects and estimating object pose, where the former necessitates a view-invariant representation, while the latter requires a representation capable of capturing pose information over different categories of objects. With the rise of deep architectures, the prime focus has been on object category recognition. Deep learning methods have achieved wide success in this task. In contrast, object pose regression using these approaches has received relatively much less attention. In this paper we show how deep architectures, specifically Convolutional Neural Networks (CNN), can be adapted to the task of simultaneous categorization and pose estimation of objects. We investigate and analyze the layers of various CNN models and extensively compare between them with the goal of discovering how the layers of distributed representations of CNNs represent object pose information and how this contradicts with object category representations. We extensively experiment on two recent large and challenging multi-view datasets. Our models achieve better than state-of-the-art performance on both datasets.
Automatic Annotation of Structured Facts in Images
Apr 08, 2016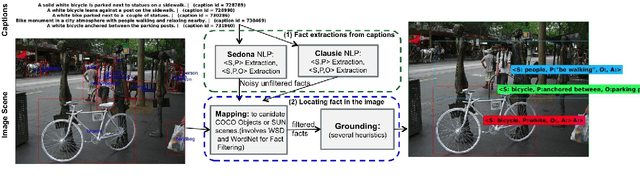

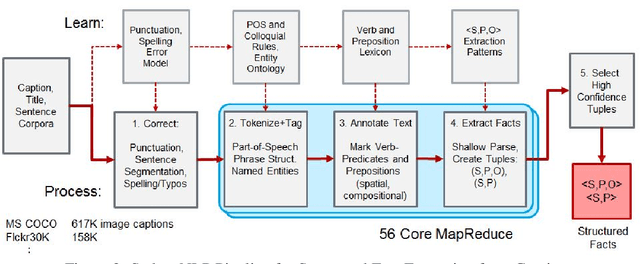

Motivated by the application of fact-level image understanding, we present an automatic method for data collection of structured visual facts from images with captions. Example structured facts include attributed objects (e.g., <flower, red>), actions (e.g., <baby, smile>), interactions (e.g., <man, walking, dog>), and positional information (e.g., <vase, on, table>). The collected annotations are in the form of fact-image pairs (e.g.,<man, walking, dog> and an image region containing this fact). With a language approach, the proposed method is able to collect hundreds of thousands of visual fact annotations with accuracy of 83% according to human judgment. Our method automatically collected more than 380,000 visual fact annotations and more than 110,000 unique visual facts from images with captions and localized them in images in less than one day of processing time on standard CPU platforms.
Sherlock: Scalable Fact Learning in Images
Apr 02, 2016
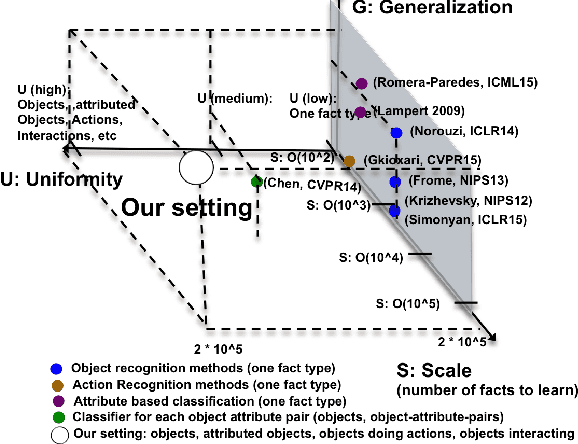
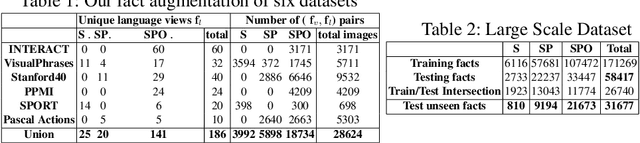
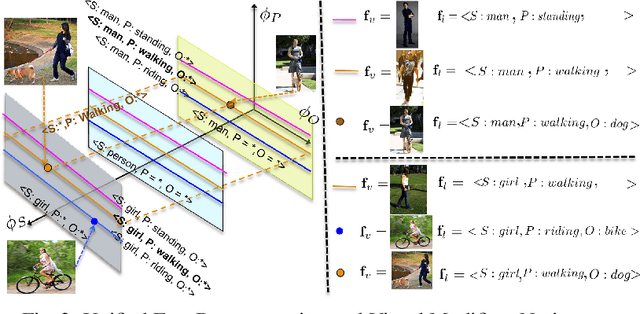
We study scalable and uniform understanding of facts in images. Existing visual recognition systems are typically modeled differently for each fact type such as objects, actions, and interactions. We propose a setting where all these facts can be modeled simultaneously with a capacity to understand unbounded number of facts in a structured way. The training data comes as structured facts in images, including (1) objects (e.g., $<$boy$>$), (2) attributes (e.g., $<$boy, tall$>$), (3) actions (e.g., $<$boy, playing$>$), and (4) interactions (e.g., $<$boy, riding, a horse $>$). Each fact has a semantic language view (e.g., $<$ boy, playing$>$) and a visual view (an image with this fact). We show that learning visual facts in a structured way enables not only a uniform but also generalizable visual understanding. We propose and investigate recent and strong approaches from the multiview learning literature and also introduce two learning representation models as potential baselines. We applied the investigated methods on several datasets that we augmented with structured facts and a large scale dataset of more than 202,000 facts and 814,000 images. Our experiments show the advantage of relating facts by the structure by the proposed models compared to the designed baselines on bidirectional fact retrieval.
The Role of Typicality in Object Classification: Improving The Generalization Capacity of Convolutional Neural Networks
Feb 09, 2016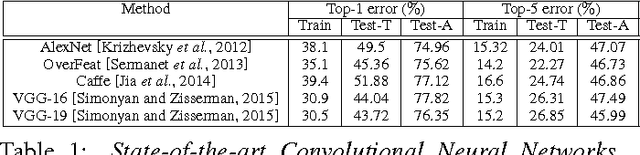


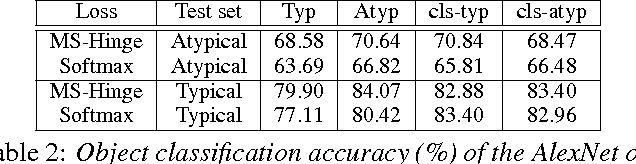
Deep artificial neural networks have made remarkable progress in different tasks in the field of computer vision. However, the empirical analysis of these models and investigation of their failure cases has received attention recently. In this work, we show that deep learning models cannot generalize to atypical images that are substantially different from training images. This is in contrast to the superior generalization ability of the visual system in the human brain. We focus on Convolutional Neural Networks (CNN) as the state-of-the-art models in object recognition and classification; investigate this problem in more detail, and hypothesize that training CNN models suffer from unstructured loss minimization. We propose computational models to improve the generalization capacity of CNNs by considering how typical a training image looks like. By conducting an extensive set of experiments we show that involving a typicality measure can improve the classification results on a new set of images by a large margin. More importantly, this significant improvement is achieved without fine-tuning the CNN model on the target image set.
Manifold-Kernels Comparison in MKPLS for Visual Speech Recognition
Jan 22, 2016
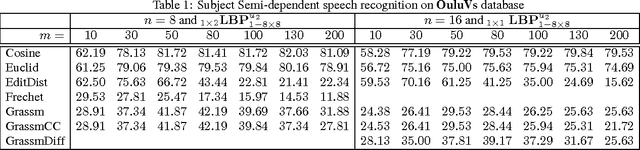
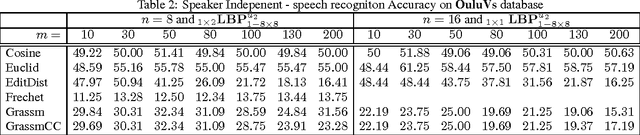
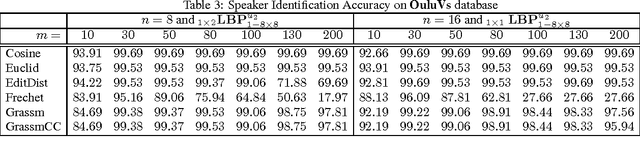
Speech recognition is a challenging problem. Due to the acoustic limitations, using visual information is essential for improving the recognition accuracy in real-life unconstraint situations. One common approach is to model the visual recognition as nonlinear optimization problem. Measuring the distances between visual units is essential for solving this problem. Embedding the visual units on a manifold and using manifold kernels is one way to measure these distances. This work is intended to evaluate the performance of several manifold kernels for solving the problem of visual speech recognition. We show the theory behind each kernel. We apply manifold kernel partial least squares framework to OuluVs and AvLetters databases, and show empirical comparison between all kernels. This framework provides convenient way to explore different kernels.
Learning Kernels for Structured Prediction using Polynomial Kernel Transformations
Jan 07, 2016
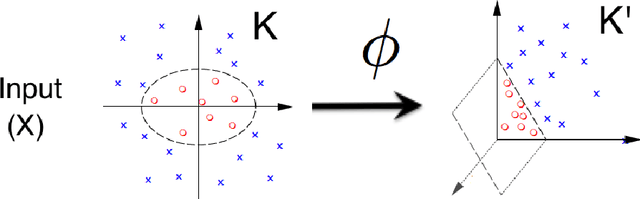
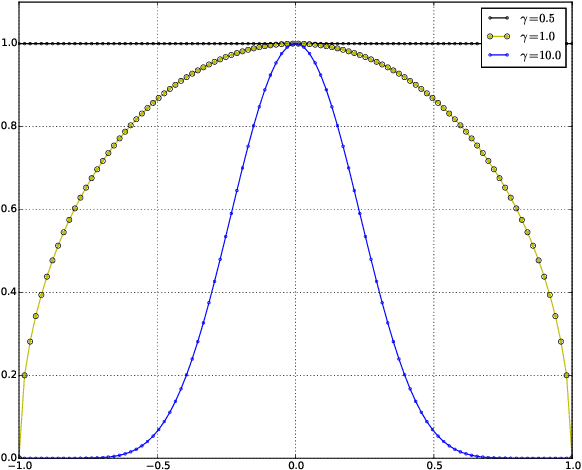
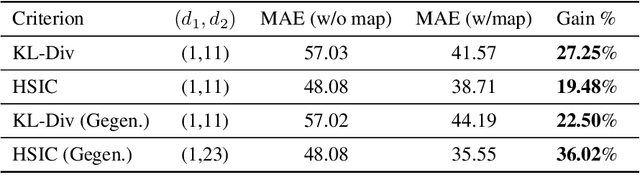
Learning the kernel functions used in kernel methods has been a vastly explored area in machine learning. It is now widely accepted that to obtain 'good' performance, learning a kernel function is the key challenge. In this work we focus on learning kernel representations for structured regression. We propose use of polynomials expansion of kernels, referred to as Schoenberg transforms and Gegenbaur transforms, which arise from the seminal result of Schoenberg (1938). These kernels can be thought of as polynomial combination of input features in a high dimensional reproducing kernel Hilbert space (RKHS). We learn kernels over input and output for structured data, such that, dependency between kernel features is maximized. We use Hilbert-Schmidt Independence Criterion (HSIC) to measure this. We also give an efficient, matrix decomposition-based algorithm to learn these kernel transformations, and demonstrate state-of-the-art results on several real-world datasets.
Supervised Dimensionality Reduction via Distance Correlation Maximization
Jan 03, 2016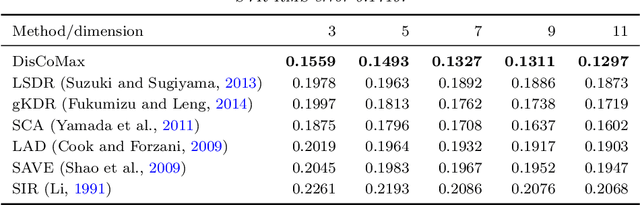
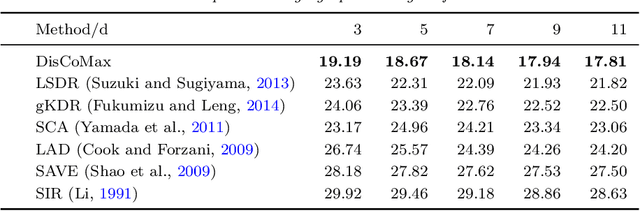
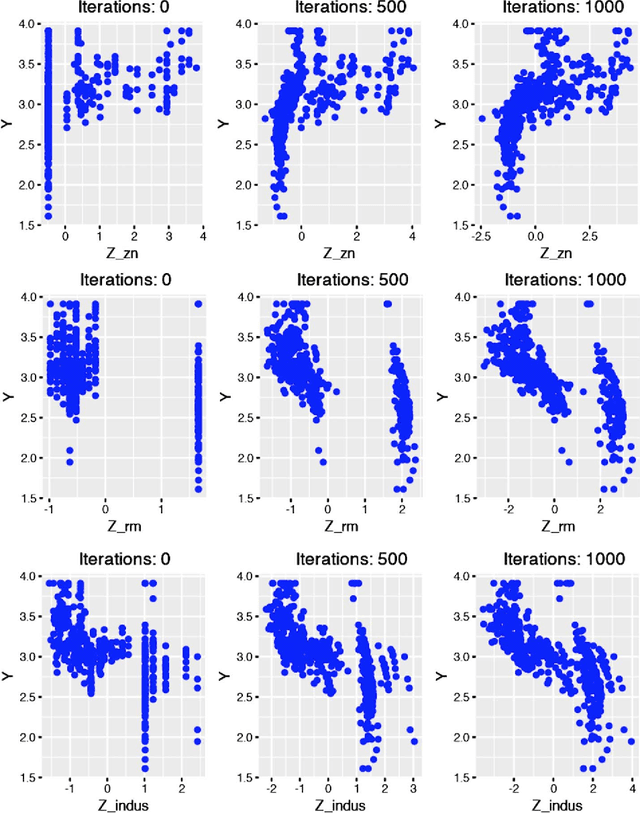
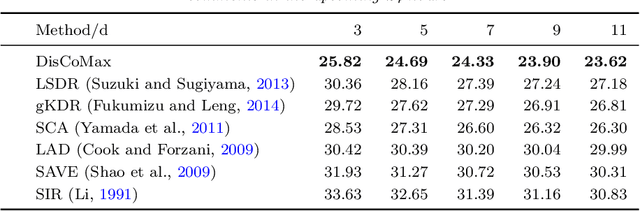
In our work, we propose a novel formulation for supervised dimensionality reduction based on a nonlinear dependency criterion called Statistical Distance Correlation, Szekely et. al. (2007). We propose an objective which is free of distributional assumptions on regression variables and regression model assumptions. Our proposed formulation is based on learning a low-dimensional feature representation $\mathbf{z}$, which maximizes the squared sum of Distance Correlations between low dimensional features $\mathbf{z}$ and response $y$, and also between features $\mathbf{z}$ and covariates $\mathbf{x}$. We propose a novel algorithm to optimize our proposed objective using the Generalized Minimization Maximizaiton method of \Parizi et. al. (2015). We show superior empirical results on multiple datasets proving the effectiveness of our proposed approach over several relevant state-of-the-art supervised dimensionality reduction methods.
Zero-Shot Event Detection by Multimodal Distributional Semantic Embedding of Videos
Dec 16, 2015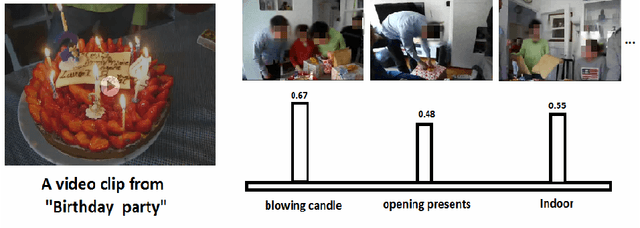

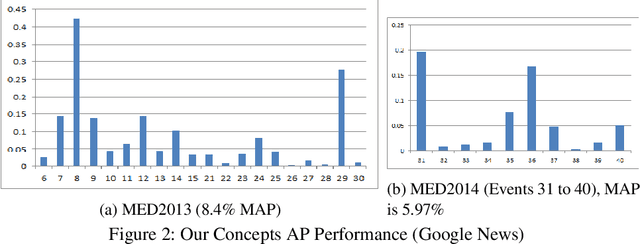

We propose a new zero-shot Event Detection method by Multi-modal Distributional Semantic embedding of videos. Our model embeds object and action concepts as well as other available modalities from videos into a distributional semantic space. To our knowledge, this is the first Zero-Shot event detection model that is built on top of distributional semantics and extends it in the following directions: (a) semantic embedding of multimodal information in videos (with focus on the visual modalities), (b) automatically determining relevance of concepts/attributes to a free text query, which could be useful for other applications, and (c) retrieving videos by free text event query (e.g., "changing a vehicle tire") based on their content. We embed videos into a distributional semantic space and then measure the similarity between videos and the event query in a free text form. We validated our method on the large TRECVID MED (Multimedia Event Detection) challenge. Using only the event title as a query, our method outperformed the state-of-the-art that uses big descriptions from 12.6% to 13.5% with MAP metric and 0.73 to 0.83 with ROC-AUC metric. It is also an order of magnitude faster.
Toward a Taxonomy and Computational Models of Abnormalities in Images
Dec 04, 2015


The human visual system can spot an abnormal image, and reason about what makes it strange. This task has not received enough attention in computer vision. In this paper we study various types of atypicalities in images in a more comprehensive way than has been done before. We propose a new dataset of abnormal images showing a wide range of atypicalities. We design human subject experiments to discover a coarse taxonomy of the reasons for abnormality. Our experiments reveal three major categories of abnormality: object-centric, scene-centric, and contextual. Based on this taxonomy, we propose a comprehensive computational model that can predict all different types of abnormality in images and outperform prior arts in abnormality recognition.