 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoNLU: Detecting, root-causing, and fixing NLU model errors
Oct 12, 2021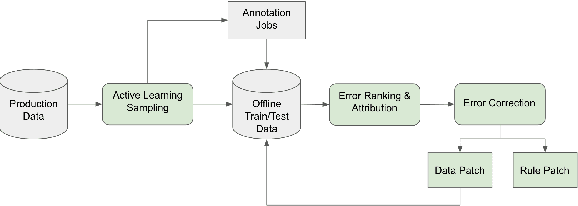


Improving the quality of Natural Language Understanding (NLU) models, and more specifically, task-oriented semantic parsing models, in production is a cumbersome task. In this work, we present a system called AutoNLU, which we designed to scale the NLU quality improvement process. It adds automation to three key steps: detection, attribution, and correction of model errors, i.e., bugs. We detected four times more failed tasks than with random sampling, finding that even a simple active learning sampling method on an uncalibrated model is surprisingly effective for this purpose. The AutoNLU tool empowered linguists to fix ten times more semantic parsing bugs than with prior manual processes, auto-correcting 65% of all identified bugs.
Assessing Data Efficiency in Task-Oriented Semantic Parsing
Jul 10, 2021
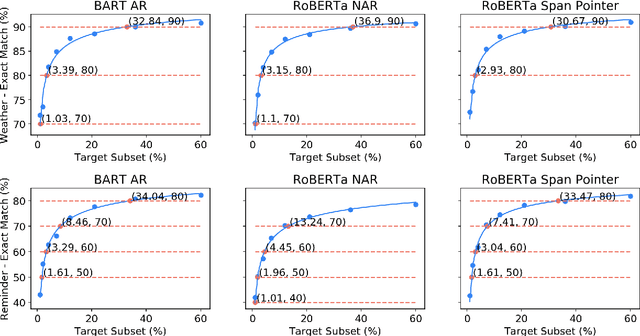

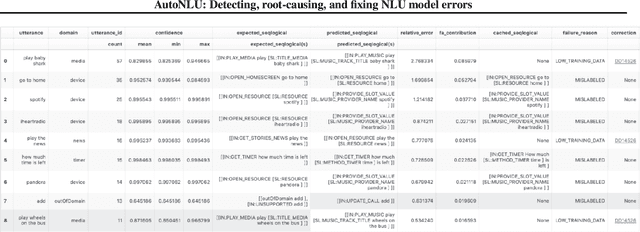
Data efficiency, despite being an attractive characteristic, is often challenging to measure and optimize for in task-oriented semantic parsing; unlike exact match, it can require both model- and domain-specific setups, which have, historically, varied widely across experiments. In our work, as a step towards providing a unified solution to data-efficiency-related questions, we introduce a four-stage protocol which gives an approximate measure of how much in-domain, "target" data a parser requires to achieve a certain quality bar. Specifically, our protocol consists of (1) sampling target subsets of different cardinalities, (2) fine-tuning parsers on each subset, (3) obtaining a smooth curve relating target subset (%) vs. exact match (%), and (4) referencing the curve to mine ad-hoc (target subset, exact match) points. We apply our protocol in two real-world case studies -- model generalizability and intent complexity -- illustrating its flexibility and applicability to practitioners in task-oriented semantic parsing.
Latency-Aware Neural Architecture Search with Multi-Objective Bayesian Optimization
Jun 25, 2021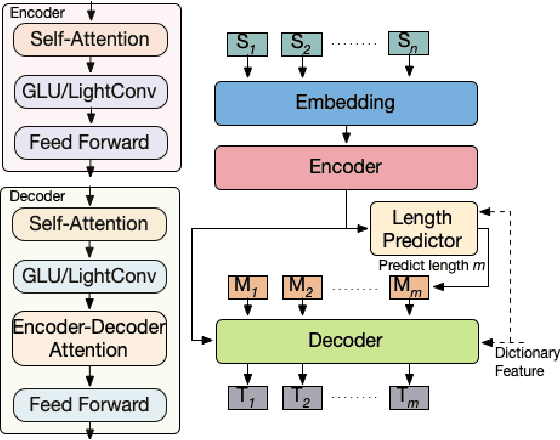

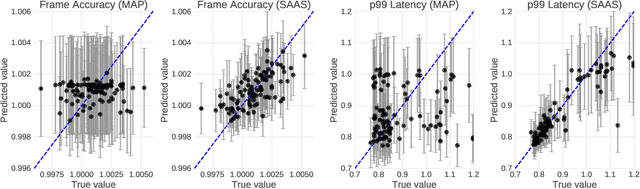
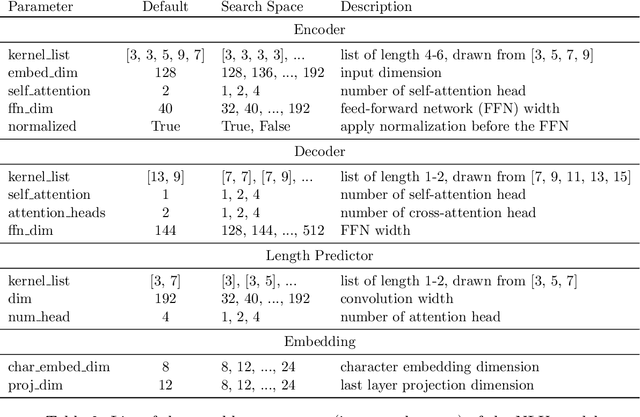
When tuning the architecture and hyperparameters of large machine learning models for on-device deployment, it is desirable to understand the optimal trade-offs between on-device latency and model accuracy. In this work, we leverage recent methodological advances in Bayesian optimization over high-dimensional search spaces and multi-objective Bayesian optimization to efficiently explore these trade-offs for a production-scale on-device natural language understanding model at Facebook.
Diagnosing Transformers in Task-Oriented Semantic Parsing
May 27, 2021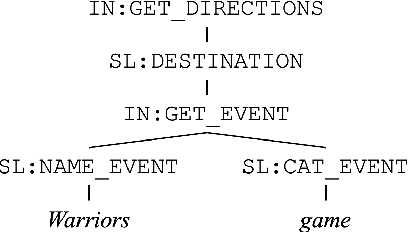
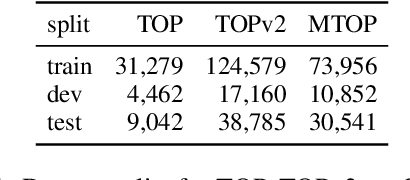

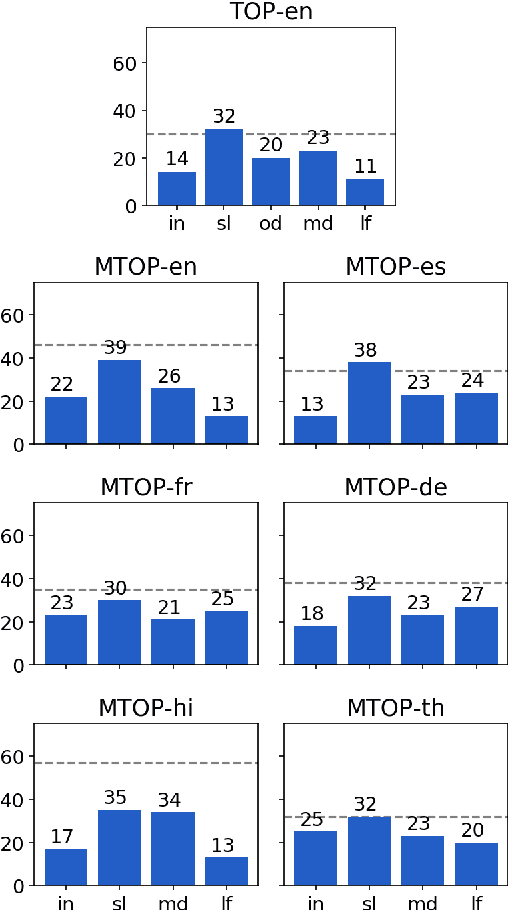
Modern task-oriented semantic parsing approaches typically use seq2seq transformers to map textual utterances to semantic frames comprised of intents and slots. While these models are empirically strong, their specific strengths and weaknesses have largely remained unexplored. In this work, we study BART and XLM-R, two state-of-the-art parsers, across both monolingual and multilingual settings. Our experiments yield several key results: transformer-based parsers struggle not only with disambiguating intents/slots, but surprisingly also with producing syntactically-valid frames. Though pre-training imbues transformers with syntactic inductive biases, we find the ambiguity of copying utterance spans into frames often leads to tree invalidity, indicating span extraction is a major bottleneck for current parsers. However, as a silver lining, we show transformer-based parsers give sufficient indicators for whether a frame is likely to be correct or incorrect, making them easier to deploy in production settings.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021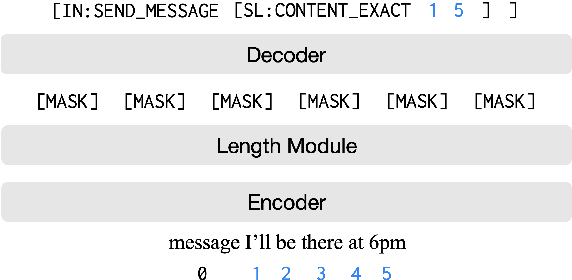

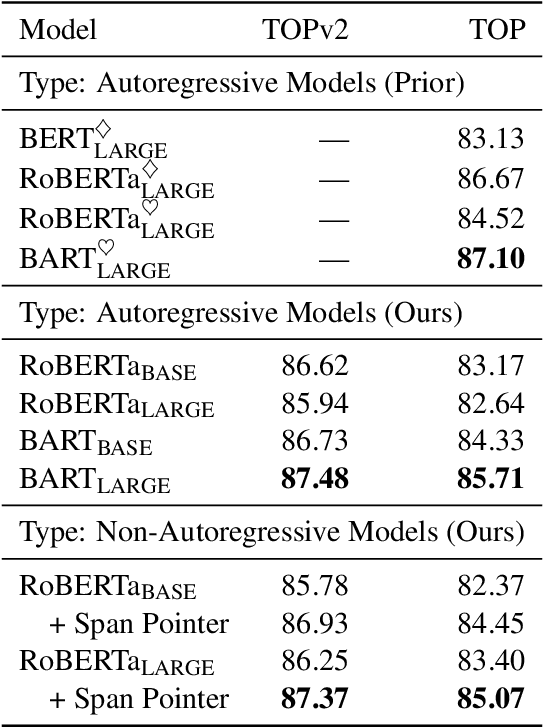
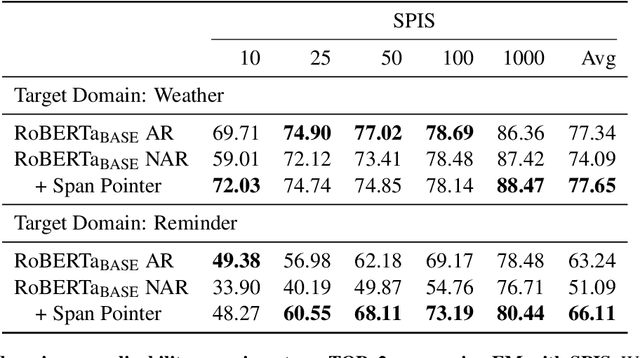
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.
Low-Resource Task-Oriented Semantic Parsing via Intrinsic Modeling
Apr 15, 2021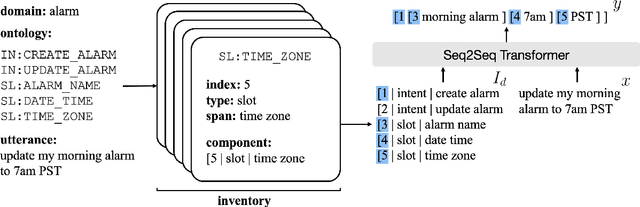
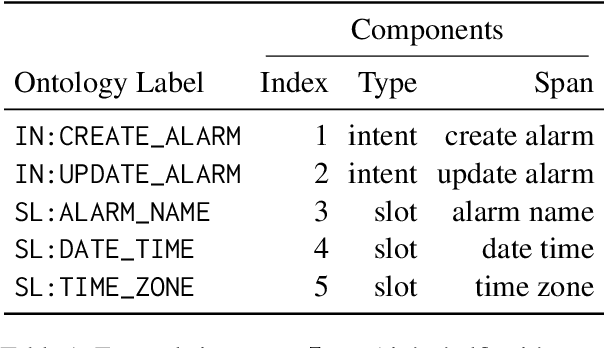
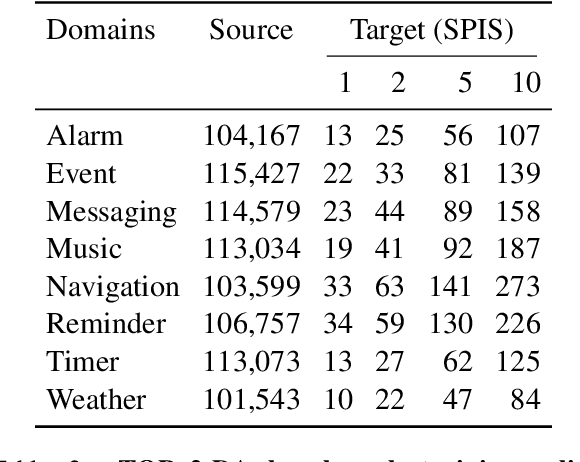
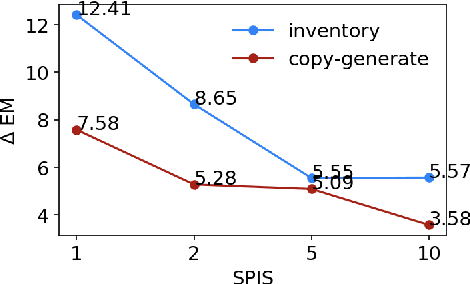
Task-oriented semantic parsing models typically have high resource requirements: to support new ontologies (i.e., intents and slots), practitioners crowdsource thousands of samples for supervised fine-tuning. Partly, this is due to the structure of de facto copy-generate parsers; these models treat ontology labels as discrete entities, relying on parallel data to extrinsically derive their meaning. In our work, we instead exploit what we intrinsically know about ontology labels; for example, the fact that SL:TIME_ZONE has the categorical type "slot" and language-based span "time zone". Using this motivation, we build our approach with offline and online stages. During preprocessing, for each ontology label, we extract its intrinsic properties into a component, and insert each component into an inventory as a cache of sorts. During training, we fine-tune a seq2seq, pre-trained transformer to map utterances and inventories to frames, parse trees comprised of utterance and ontology tokens. Our formulation encourages the model to consider ontology labels as a union of its intrinsic properties, therefore substantially bootstrapping learning in low-resource settings. Experiments show our model is highly sample efficient: using a low-resource benchmark derived from TOPv2, our inventory parser outperforms a copy-generate parser by +15 EM absolute (44% relative) when fine-tuning on 10 samples from an unseen domain.
Non-Autoregressive Semantic Parsing for Compositional Task-Oriented Dialog
Apr 11, 2021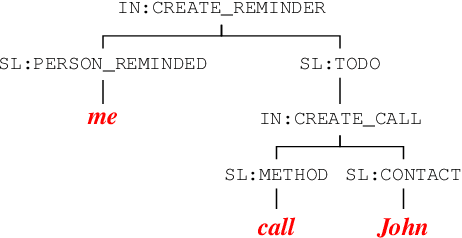

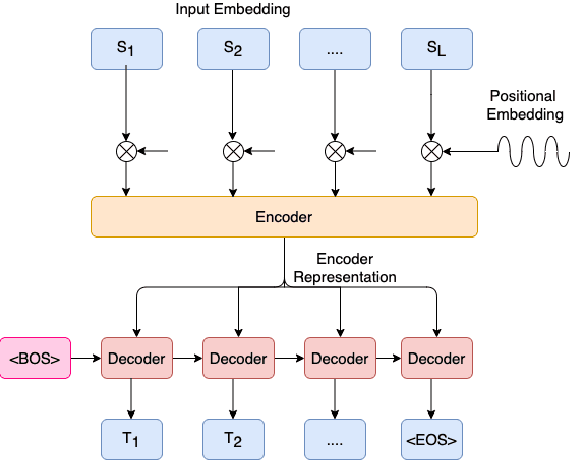
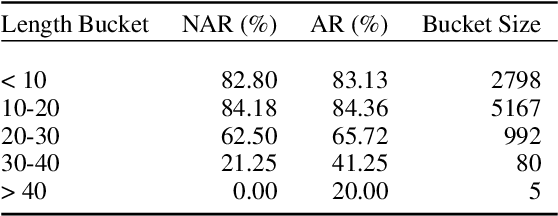
Semantic parsing using sequence-to-sequence models allows parsing of deeper representations compared to traditional word tagging based models. In spite of these advantages, widespread adoption of these models for real-time conversational use cases has been stymied by higher compute requirements and thus higher latency. In this work, we propose a non-autoregressive approach to predict semantic parse trees with an efficient seq2seq model architecture. By combining non-autoregressive prediction with convolutional neural networks, we achieve significant latency gains and parameter size reduction compared to traditional RNN models. Our novel architecture achieves up to an 81% reduction in latency on TOP dataset and retains competitive performance to non-pretrained models on three different semantic parsing datasets. Our code is available at https://github.com/facebookresearch/pytext
Lightweight Convolutional Representations for On-Device Natural Language Processing
Feb 04, 2020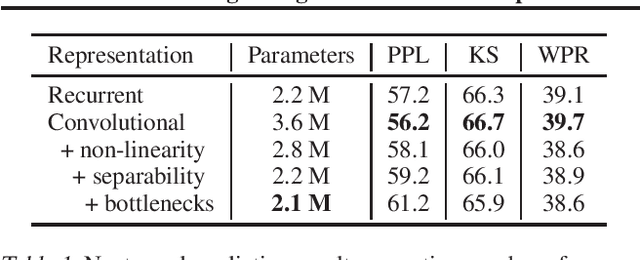
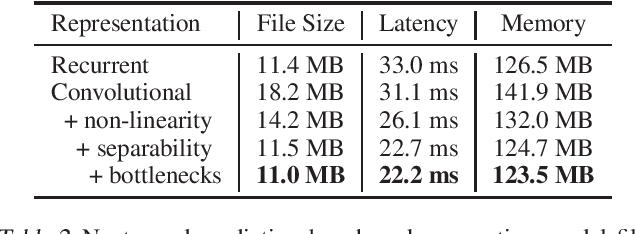
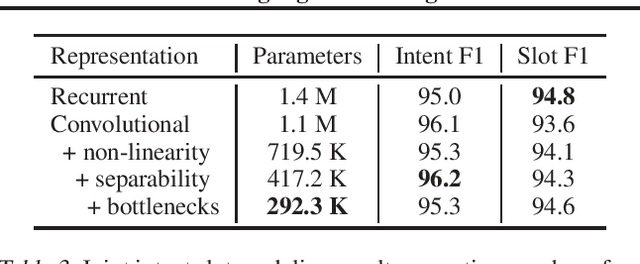
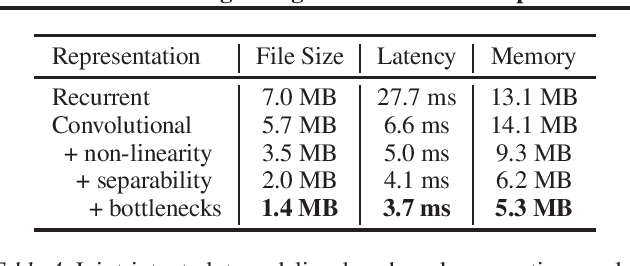
The increasing computational and memory complexities of deep neural networks have made it difficult to deploy them on low-resource electronic devices (e.g., mobile phones, tablets, wearables). Practitioners have developed numerous model compression methods to address these concerns, but few have condensed input representations themselves. In this work, we propose a fast, accurate, and lightweight convolutional representation that can be swapped into any neural model and compressed significantly (up to 32x) with a negligible reduction in performance. In addition, we show gains over recurrent representations when considering resource-centric metrics (e.g., model file size, latency, memory usage) on a Samsung Galaxy S9.
Evaluating Lottery Tickets Under Distributional Shifts
Oct 28, 2019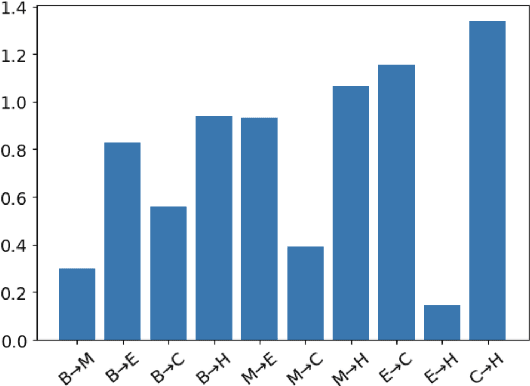
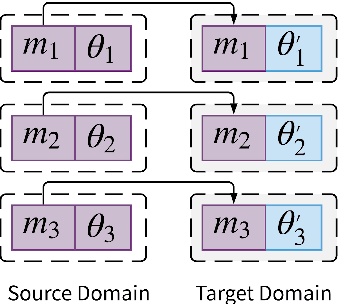
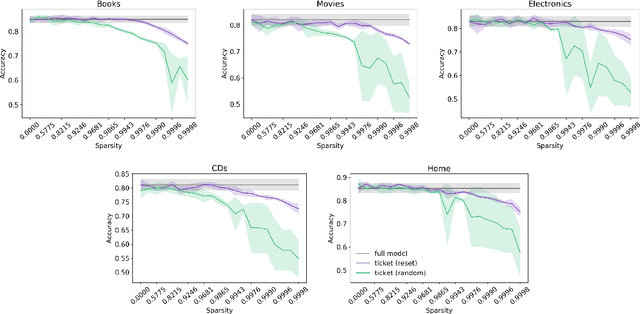
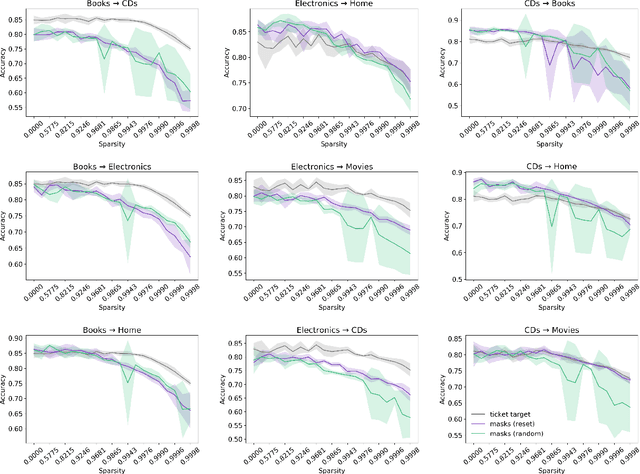
The Lottery Ticket Hypothesis suggests large, over-parameterized neural networks consist of small, sparse subnetworks that can be trained in isolation to reach a similar (or better) test accuracy. However, the initialization and generalizability of the obtained sparse subnetworks have been recently called into question. Our work focuses on evaluating the initialization of sparse subnetworks under distributional shifts. Specifically, we investigate the extent to which a sparse subnetwork obtained in a source domain can be re-trained in isolation in a dissimilar, target domain. In addition, we examine the effects of different initialization strategies at transfer-time. Our experiments show that sparse subnetworks obtained through lottery ticket training do not simply overfit to particular domains, but rather reflect an inductive bias of deep neural networks that can be exploited in multiple domains.
Optimizing Deep Neural Networks with Multiple Search Neuroevolution
Jan 17, 2019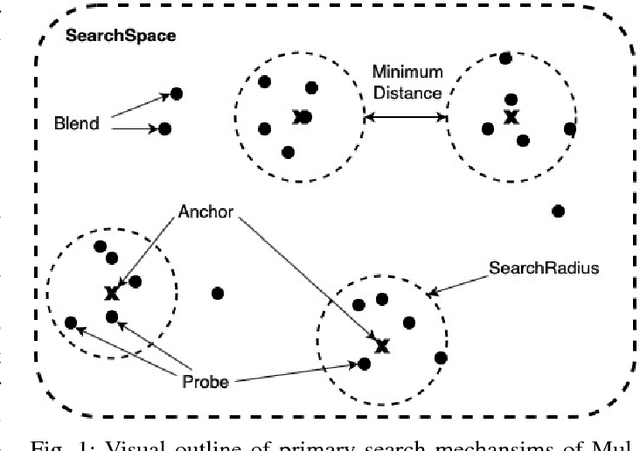
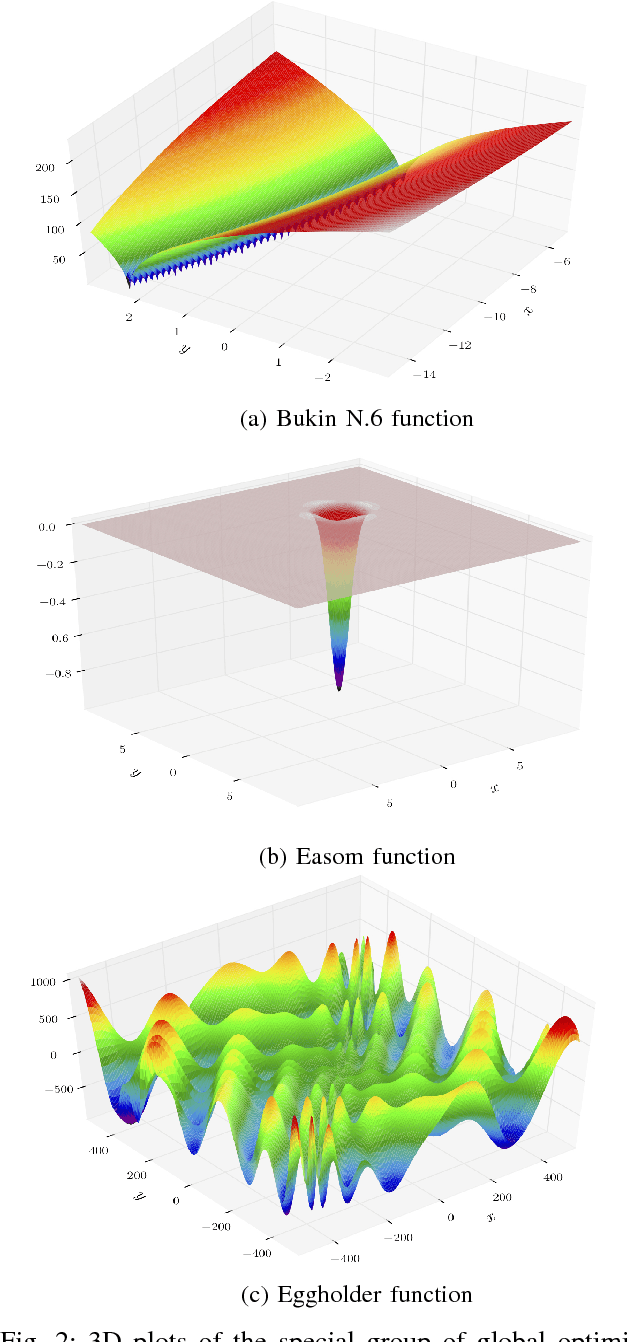
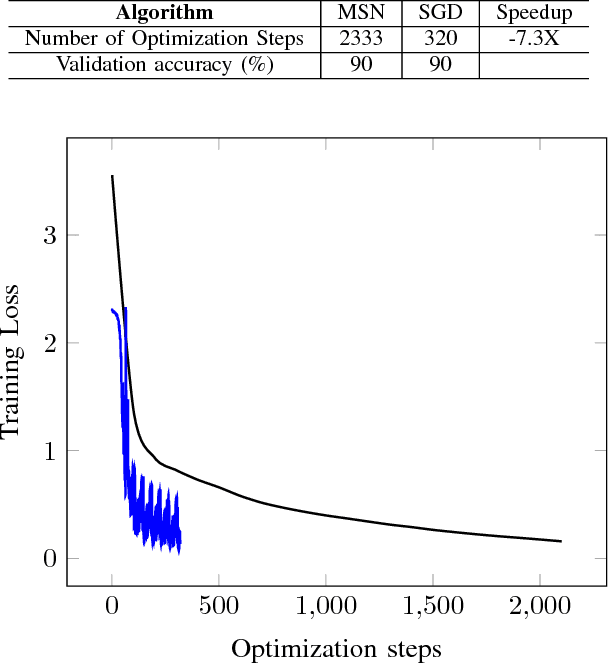
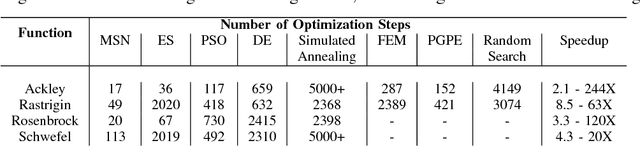
This paper presents an evolutionary metaheuristic called Multiple Search Neuroevolution (MSN) to optimize deep neural networks. The algorithm attempts to search multiple promising regions in the search space simultaneously, maintaining sufficient distance between them. It is tested by training neural networks for two tasks, and compared with other optimization algorithms. The first task is to solve Global Optimization functions with challenging topographies. We found to MSN to outperform classic optimization algorithms such as Evolution Strategies, reducing the number of optimization steps performed by at least 2X. The second task is to train a convolutional neural network (CNN) on the popular MNIST dataset. Using 3.33% of the training set, MSN reaches a validation accuracy of 90%. Stochastic Gradient Descent (SGD) was able to match the same accuracy figure, while taking 7X less optimization steps. Despite lagging, the fact that the MSN metaheurisitc trains a 4.7M-parameter CNN suggests promise for future development. This is by far the largest network ever evolved using a pool of only 50 samples.