 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAHANI: Culturally-Nuanced Visual Storytelling Pipeline for Non-Western Cultures
Oct 28, 2024



Large Language Models (LLMs) and Text-To-Image (T2I) models have demonstrated the ability to generate compelling text and visual stories. However, their outputs are predominantly aligned with the sensibilities of the Global North, often resulting in an outsider's gaze on other cultures. As a result, non-Western communities have to put extra effort into generating culturally specific stories. To address this challenge, we developed a visual storytelling pipeline called KAHANI that generates culturally grounded visual stories for non-Western cultures. Our pipeline leverages off-the-shelf models GPT-4 Turbo and Stable Diffusion XL (SDXL). By using Chain of Thought (CoT) and T2I prompting techniques, we capture the cultural context from user's prompt and generate vivid descriptions of the characters and scene compositions. To evaluate the effectiveness of KAHANI, we conducted a comparative user study with ChatGPT-4 (with DALL-E3) in which participants from different regions of India compared the cultural relevance of stories generated by the two tools. Results from the qualitative and quantitative analysis performed on the user study showed that KAHANI was able to capture and incorporate more Culturally Specific Items (CSIs) compared to ChatGPT-4. In terms of both its cultural competence and visual story generation quality, our pipeline outperformed ChatGPT-4 in 27 out of the 36 comparisons.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024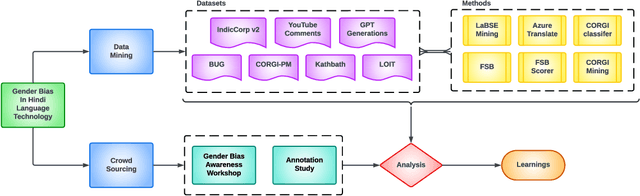

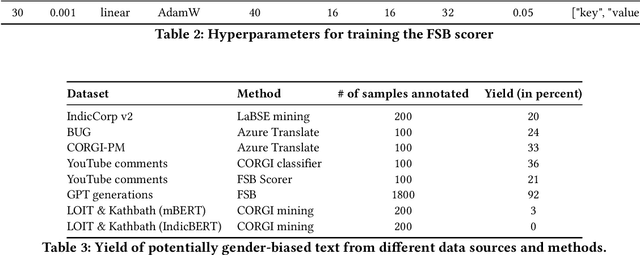
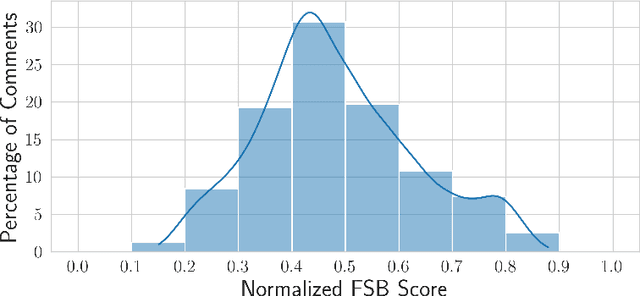
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
''Fifty Shades of Bias'': Normative Ratings of Gender Bias in GPT Generated English Text
Oct 26, 2023Language serves as a powerful tool for the manifestation of societal belief systems. In doing so, it also perpetuates the prevalent biases in our society. Gender bias is one of the most pervasive biases in our society and is seen in online and offline discourses. With LLMs increasingly gaining human-like fluency in text generation, gaining a nuanced understanding of the biases these systems can generate is imperative. Prior work often treats gender bias as a binary classification task. However, acknowledging that bias must be perceived at a relative scale; we investigate the generation and consequent receptivity of manual annotators to bias of varying degrees. Specifically, we create the first dataset of GPT-generated English text with normative ratings of gender bias. Ratings were obtained using Best--Worst Scaling -- an efficient comparative annotation framework. Next, we systematically analyze the variation of themes of gender biases in the observed ranking and show that identity-attack is most closely related to gender bias. Finally, we show the performance of existing automated models trained on related concepts on our dataset.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.
Your spouse needs professional help: Determining the Contextual Appropriateness of Messages through Modeling Social Relationships
Jul 06, 2023



Understanding interpersonal communication requires, in part, understanding the social context and norms in which a message is said. However, current methods for identifying offensive content in such communication largely operate independent of context, with only a few approaches considering community norms or prior conversation as context. Here, we introduce a new approach to identifying inappropriate communication by explicitly modeling the social relationship between the individuals. We introduce a new dataset of contextually-situated judgments of appropriateness and show that large language models can readily incorporate relationship information to accurately identify appropriateness in a given context. Using data from online conversations and movie dialogues, we provide insight into how the relationships themselves function as implicit norms and quantify the degree to which context-sensitivity is needed in different conversation settings. Further, we also demonstrate that contextual-appropriateness judgments are predictive of other social factors expressed in language such as condescension and politeness.
COVID-19 Activity Risk Calculator as a Gamified Public Health Intervention Tool
Dec 22, 2022Public health intervention techniques have been highly significant in reducing the negative impact of several epidemics and pandemics. Among all of the wide-spread diseases, one of the most dangerous one has been severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) or Coronavirus disease 2019 (COVID-19). The impact of the virus has been observed in over 200 countries leading to hospitalizations and deaths of millions of people. Currently existing COVID-19 risk estimation tools provided to the general public have been highly variable during the pandemic due to its dependency on rapidly evolving factors such as community transmission levels and variants. There has also been confusion surrounding certain personal protective strategies such as risk reduction by mask-wearing and vaccination. In order to create a simplified easy-to-use tool for estimating different individual risks associated with carrying out daily-life activity, we developed COVID-19 Activity Risk Calculator (CovARC). CovARC serves as a gamified public health intervention as users can "play with" how different risks associated with COVID-19 would change depending on several different factors when carrying out a daily routine activity. Empowering the public to make informed, data-driven decisions about safely engaging in activities may help to reduce COVID- 19 levels in the community. In this study, we demonstrate a streamlined, scalable and accurate COVID-19 risk calculation system. Our study also showcases quantitatively, the increased impact of interventions such as vaccination and mask-wearing when cases are higher, which could prove as a validity to inform and support policy decisions around mask mandate case thresholds and other non-pharmaceutical interventions.
Detector monitoring with artificial neural networks at the CMS experiment at the CERN Large Hadron Collider
Jul 27, 2018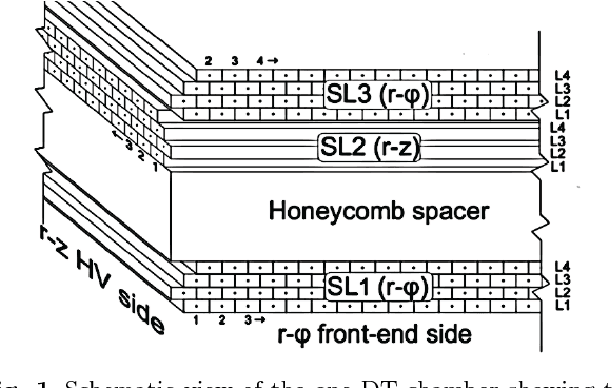
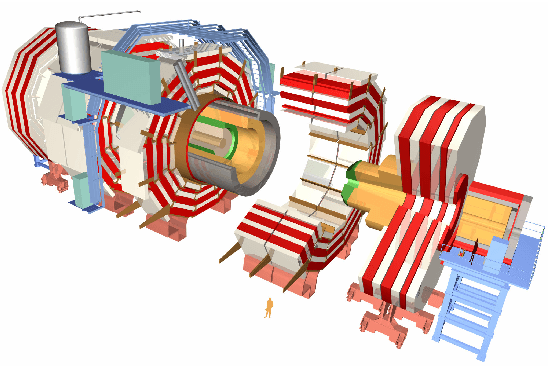
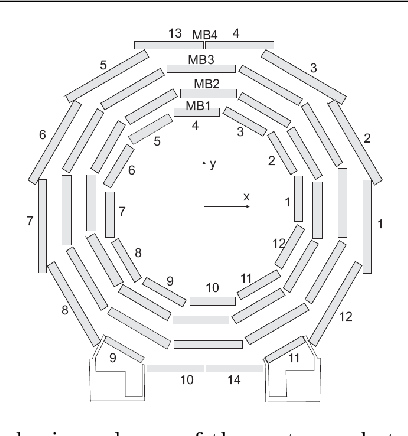
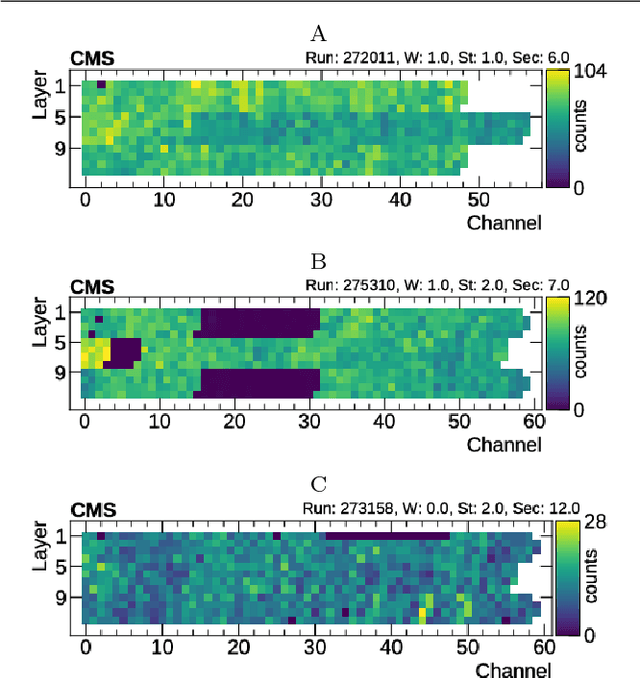
Reliable data quality monitoring is a key asset in delivering collision data suitable for physics analysis in any modern large-scale High Energy Physics experiment. This paper focuses on the use of artificial neural networks for supervised and semi-supervised problems related to the identification of anomalies in the data collected by the CMS muon detectors. We use deep neural networks to analyze LHC collision data, represented as images organized geographically. We train a classifier capable of detecting the known anomalous behaviors with unprecedented efficiency and explore the usage of convolutional autoencoders to extend anomaly detection capabilities to unforeseen failure modes. A generalization of this strategy could pave the way to the automation of the data quality assessment process for present and future high-energy physics experiments.