 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Margin: Margin-based Label Smoothing for Network Calibration
Nov 30, 2021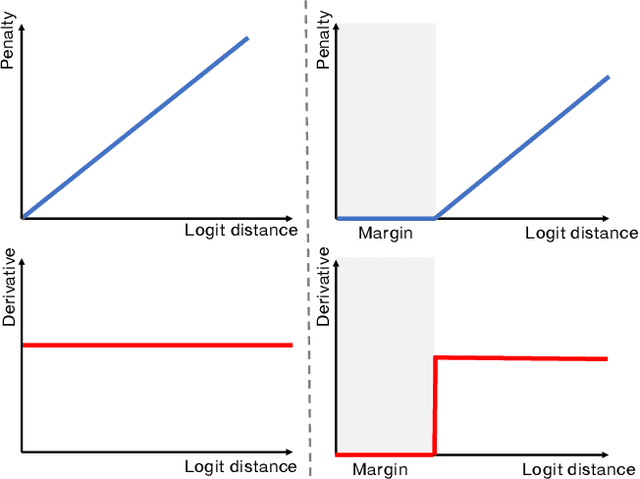
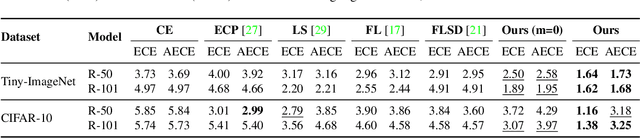
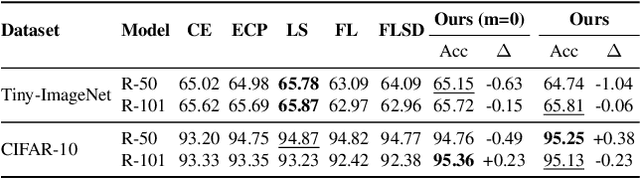
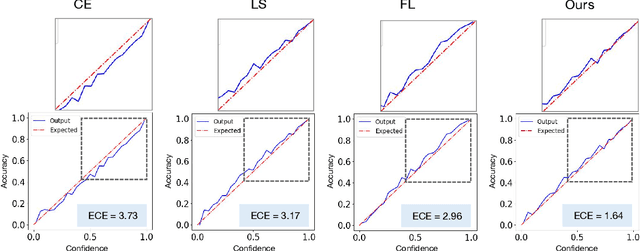
In spite of the dominant performances of deep neural networks, recent works have shown that they are poorly calibrated, resulting in over-confident predictions. Miscalibration can be exacerbated by overfitting due to the minimization of the cross-entropy during training, as it promotes the predicted softmax probabilities to match the one-hot label assignments. This yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations. Recent evidence from the literature suggests that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. We provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of image classification, semantic segmentation and NLP benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, without affecting the discriminative performance. The code is available at https://github.com/by-liu/MbLS .
A Hierarchical Multi-Task Approach to Gastrointestinal Image Analysis
Nov 16, 2021
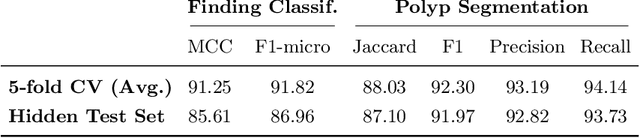
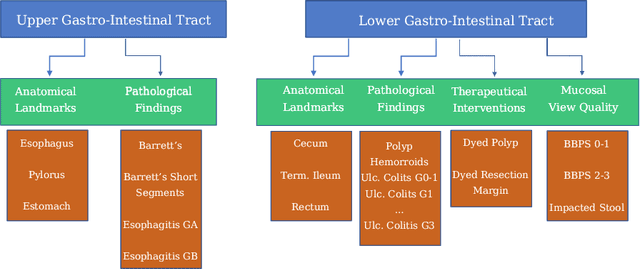
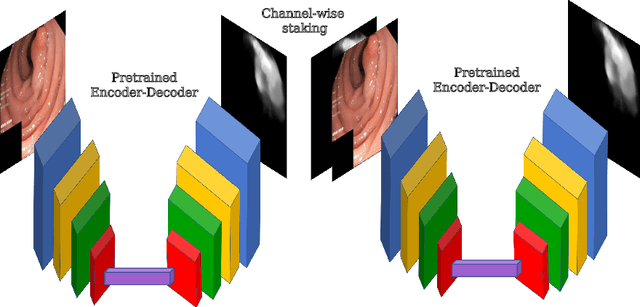
A large number of different lesions and pathologies can affect the human digestive system, resulting in life-threatening situations. Early detection plays a relevant role in the successful treatment and the increase of current survival rates to, e.g., colorectal cancer. The standard procedure enabling detection, endoscopic video analysis, generates large quantities of visual data that need to be carefully analyzed by an specialist. Due to the wide range of color, shape, and general visual appearance of pathologies, as well as highly varying image quality, such process is greatly dependent on the human operator experience and skill. In this work, we detail our solution to the task of multi-category classification of images from the gastrointestinal (GI) human tract within the 2020 Endotect Challenge. Our approach is based on a Convolutional Neural Network minimizing a hierarchical error function that takes into account not only the finding category, but also its location within the GI tract (lower/upper tract), and the type of finding (pathological finding/therapeutic intervention/anatomical landmark/mucosal views' quality). We also describe in this paper our solution for the challenge task of polyp segmentation in colonoscopies, which was addressed with a pretrained double encoder-decoder network. Our internal cross-validation results show an average performance of 91.25 Mathews Correlation Coefficient (MCC) and 91.82 Micro-F1 score for the classification task, and a 92.30 F1 score for the polyp segmentation task. The organization provided feedback on the performance in a hidden test set for both tasks, which resulted in 85.61 MCC and 86.96 F1 score for classification, and 91.97 F1 score for polyp segmentation. At the time of writing no public ranking for this challenge had been released.
Convolutional Nets Versus Vision Transformers for Diabetic Foot Ulcer Classification
Nov 12, 2021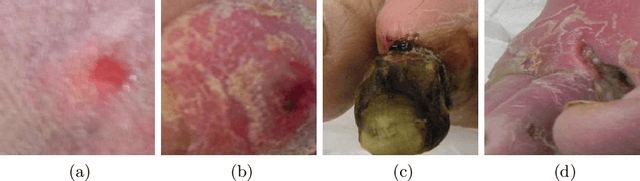
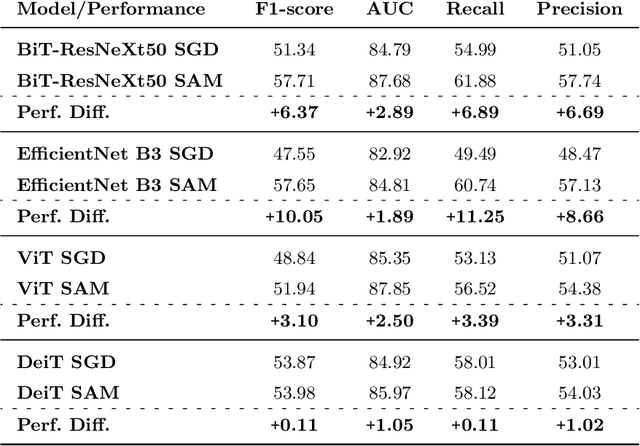
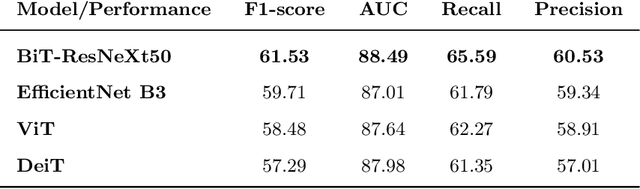
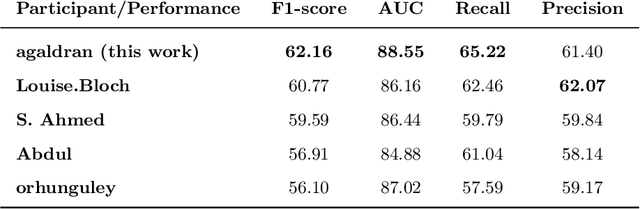
This paper compares well-established Convolutional Neural Networks (CNNs) to recently introduced Vision Transformers for the task of Diabetic Foot Ulcer Classification, in the context of the DFUC 2021 Grand-Challenge, in which this work attained the first position. Comprehensive experiments demonstrate that modern CNNs are still capable of outperforming Transformers in a low-data regime, likely owing to their ability for better exploiting spatial correlations. In addition, we empirically demonstrate that the recent Sharpness-Aware Minimization (SAM) optimization algorithm considerably improves the generalization capability of both kinds of models. Our results demonstrate that for this task, the combination of CNNs and the SAM optimization process results in superior performance than any other of the considered approaches.
Double Encoder-Decoder Networks for Gastrointestinal Polyp Segmentation
Oct 05, 2021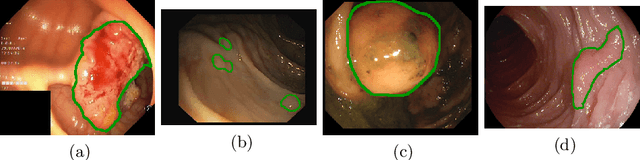

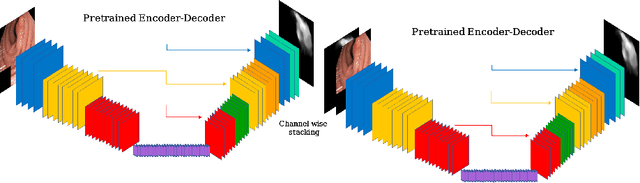
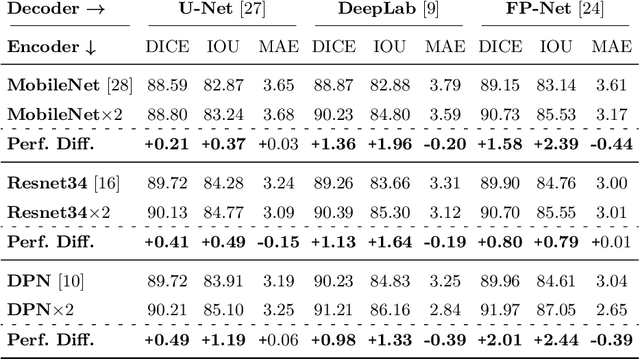
Polyps represent an early sign of the development of Colorectal Cancer. The standard procedure for their detection consists of colonoscopic examination of the gastrointestinal tract. However, the wide range of polyp shapes and visual appearances, as well as the reduced quality of this image modality, turn their automatic identification and segmentation with computational tools into a challenging computer vision task. In this work, we present a new strategy for the delineation of gastrointestinal polyps from endoscopic images based on a direct extension of common encoder-decoder networks for semantic segmentation. In our approach, two pretrained encoder-decoder networks are sequentially stacked: the second network takes as input the concatenation of the original frame and the initial prediction generated by the first network, which acts as an attention mechanism enabling the second network to focus on interesting areas within the image, thereby improving the quality of its predictions. Quantitative evaluation carried out on several polyp segmentation databases shows that double encoder-decoder networks clearly outperform their single encoder-decoder counterparts in all cases. In addition, our best double encoder-decoder combination attains excellent segmentation accuracy and reaches state-of-the-art performance results in all the considered datasets, with a remarkable boost of accuracy on images extracted from datasets not used for training.
Balanced-MixUp for Highly Imbalanced Medical Image Classification
Sep 20, 2021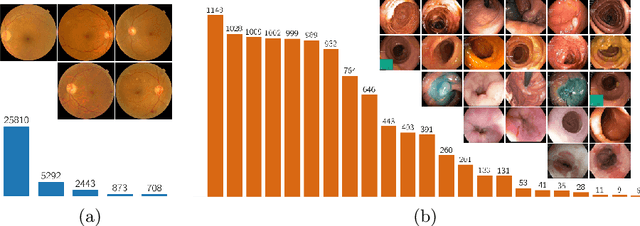
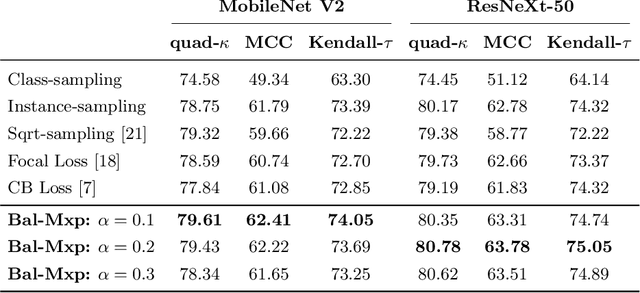

Highly imbalanced datasets are ubiquitous in medical image classification problems. In such problems, it is often the case that rare classes associated to less prevalent diseases are severely under-represented in labeled databases, typically resulting in poor performance of machine learning algorithms due to overfitting in the learning process. In this paper, we propose a novel mechanism for sampling training data based on the popular MixUp regularization technique, which we refer to as Balanced-MixUp. In short, Balanced-MixUp simultaneously performs regular (i.e., instance-based) and balanced (i.e., class-based) sampling of the training data. The resulting two sets of samples are then mixed-up to create a more balanced training distribution from which a neural network can effectively learn without incurring in heavily under-fitting the minority classes. We experiment with a highly imbalanced dataset of retinal images (55K samples, 5 classes) and a long-tail dataset of gastro-intestinal video frames (10K images, 23 classes), using two CNNs of varying representation capabilities. Experimental results demonstrate that applying Balanced-MixUp outperforms other conventional sampling schemes and loss functions specifically designed to deal with imbalanced data. Code is released at https://github.com/agaldran/balanced_mixup .
The hidden label-marginal biases of segmentation losses
Apr 18, 2021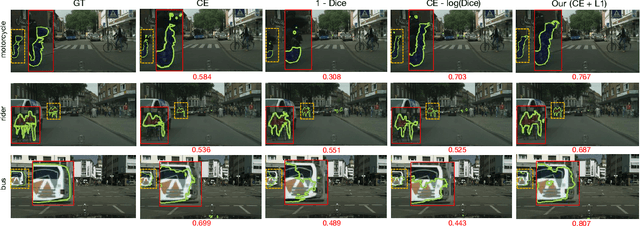
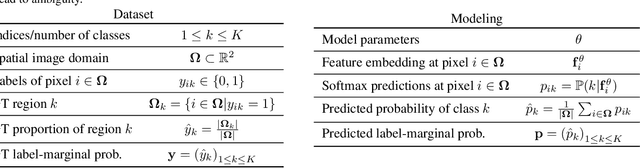
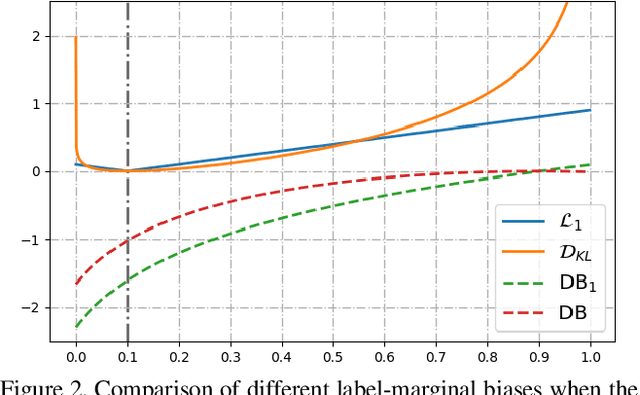
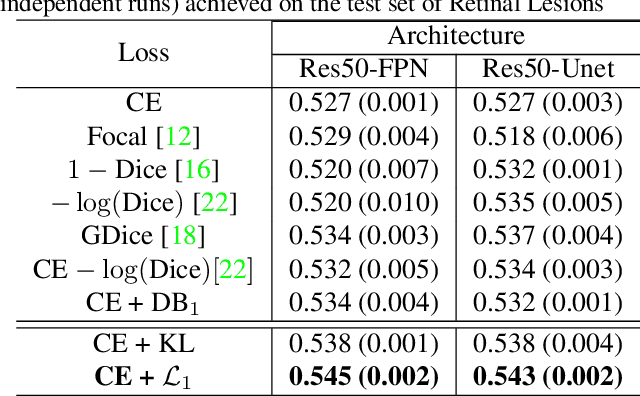
Most segmentation losses are arguably variants of the Cross-Entropy (CE) or Dice loss. In the literature, there is no clear consensus as to which of these losses is a better choice, with varying performances for each across different benchmarks and applications. We develop a theoretical analysis that links these two types of losses, exposing their advantages and weaknesses. First, we explicitly demonstrate that CE and Dice share a much deeper connection than previously thought: CE is an upper bound on both logarithmic and linear Dice losses. Furthermore, we provide an information-theoretic analysis, which highlights hidden label-marginal biases : Dice has an intrinsic bias towards imbalanced solutions, whereas CE implicitly encourages the ground-truth region proportions. Our theoretical results explain the wide experimental evidence in the medical-imaging literature, whereby Dice losses bring improvements for imbalanced segmentation. It also explains why CE dominates natural-image problems with diverse class proportions, in which case Dice might have difficulty adapting to different label-marginal distributions. Based on our theoretical analysis, we propose a principled and simple solution, which enables to control explicitly the label-marginal bias. Our loss integrates CE with explicit ${\cal L}_1$ regularization, which encourages label marginals to match target class proportions, thereby mitigating class imbalance but without losing generality. Comprehensive experiments and ablation studies over different losses and applications validate our theoretical analysis, as well as the effectiveness of our explicit label-marginal regularizers.
Cost-Sensitive Regularization for Diabetic Retinopathy Grading from Eye Fundus Images
Oct 01, 2020
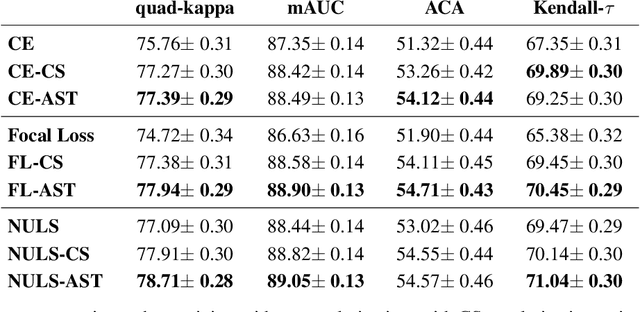

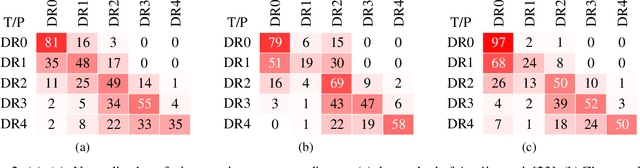
Assessing the degree of disease severity in biomedical images is a task similar to standard classification but constrained by an underlying structure in the label space. Such a structure reflects the monotonic relationship between different disease grades. In this paper, we propose a straightforward approach to enforce this constraint for the task of predicting Diabetic Retinopathy (DR) severity from eye fundus images based on the well-known notion of Cost-Sensitive classification. We expand standard classification losses with an extra term that acts as a regularizer, imposing greater penalties on predicted grades when they are farther away from the true grade associated to a particular image. Furthermore, we show how to adapt our method to the modelling of label noise in each of the sub-problems associated to DR grading, an approach we refer to as Atomic Sub-Task modeling. This yields models that can implicitly take into account the inherent noise present in DR grade annotations. Our experimental analysis on several public datasets reveals that, when a standard Convolutional Neural Network is trained using this simple strategy, improvements of 3-5\% of quadratic-weighted kappa scores can be achieved at a negligible computational cost. Code to reproduce our results is released at https://github.com/agaldran/cost_sensitive_loss_classification.
The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models
Sep 03, 2020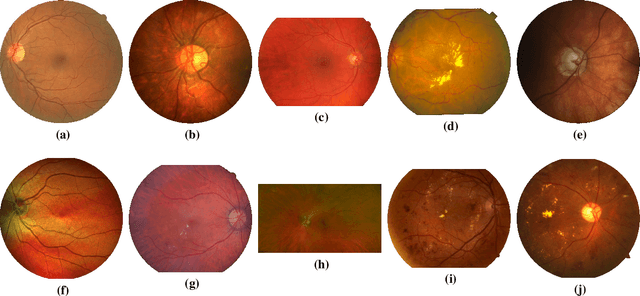
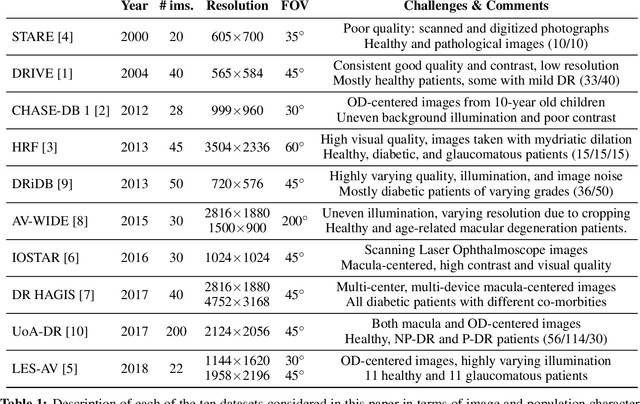
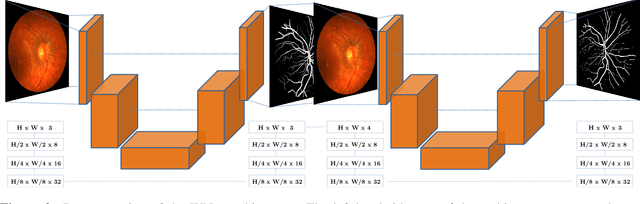
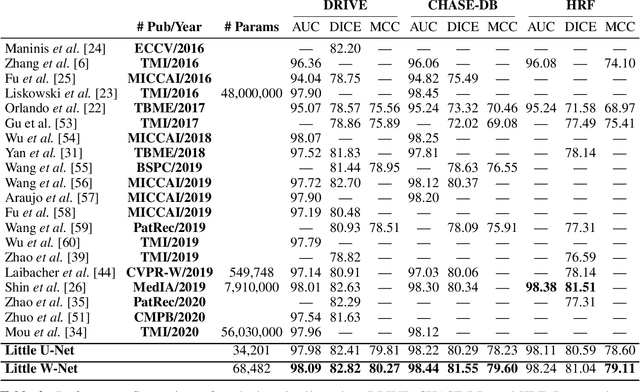
The segmentation of the retinal vasculature from eye fundus images represents one of the most fundamental tasks in retinal image analysis. Over recent years, increasingly complex approaches based on sophisticated Convolutional Neural Network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back and analyze the real need of such complexity. Specifically, we demonstrate that a minimalistic version of a standard U-Net with several orders of magnitude less parameters, carefully trained and rigorously evaluated, closely approximates the performance of current best techniques. In addition, we propose a simple extension, dubbed W-Net, which reaches outstanding performance on several popular datasets, still using orders of magnitude less learnable weights than any previously published approach. Furthermore, we provide the most comprehensive cross-dataset performance analysis to date, involving up to 10 different databases. Our analysis demonstrates that the retinal vessel segmentation problem is far from solved when considering test images that differ substantially from the training data, and that this task represents an ideal scenario for the exploration of domain adaptation techniques. In this context, we experiment with a simple self-labeling strategy that allows us to moderately enhance cross-dataset performance, indicating that there is still much room for improvement in this area. Finally, we also test our approach on the Artery/Vein segmentation problem, where we again achieve results well-aligned with the state-of-the-art, at a fraction of the model complexity in recent literature. All the code to reproduce the results in this paper is released.
Learned Pre-Processing for Automatic Diabetic Retinopathy Detection on Eye Fundus Images
Jul 27, 2020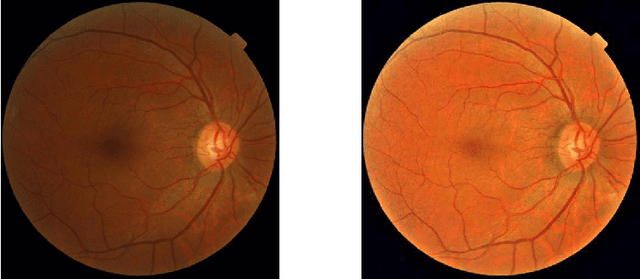
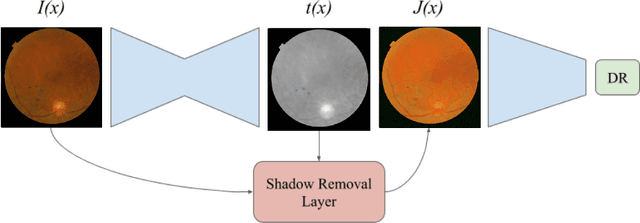
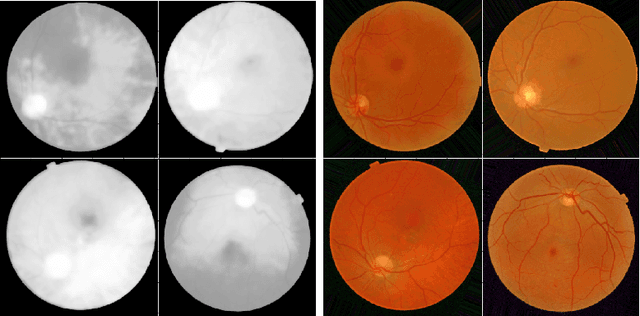
Diabetic Retinopathy is the leading cause of blindness in the working-age population of the world. The main aim of this paper is to improve the accuracy of Diabetic Retinopathy detection by implementing a shadow removal and color correction step as a preprocessing stage from eye fundus images. For this, we rely on recent findings indicating that application of image dehazing on the inverted intensity domain amounts to illumination compensation. Inspired by this work, we propose a Shadow Removal Layer that allows us to learn the pre-processing function for a particular task. We show that learning the pre-processing function improves the performance of the network on the Diabetic Retinopathy detection task.
Self-supervised blur detection from synthetically blurred scenes
Aug 28, 2019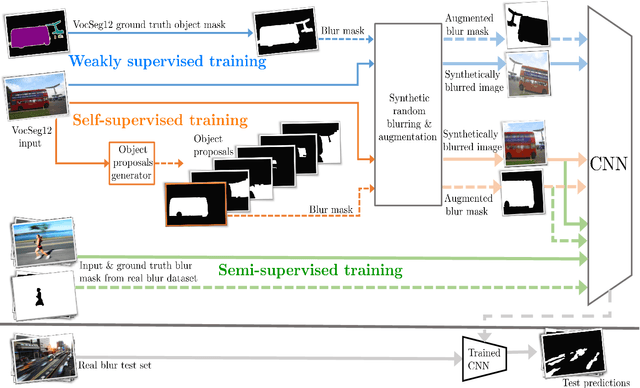
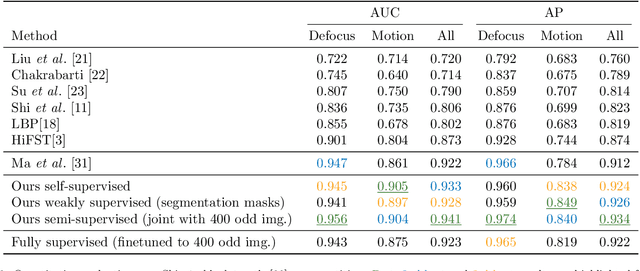
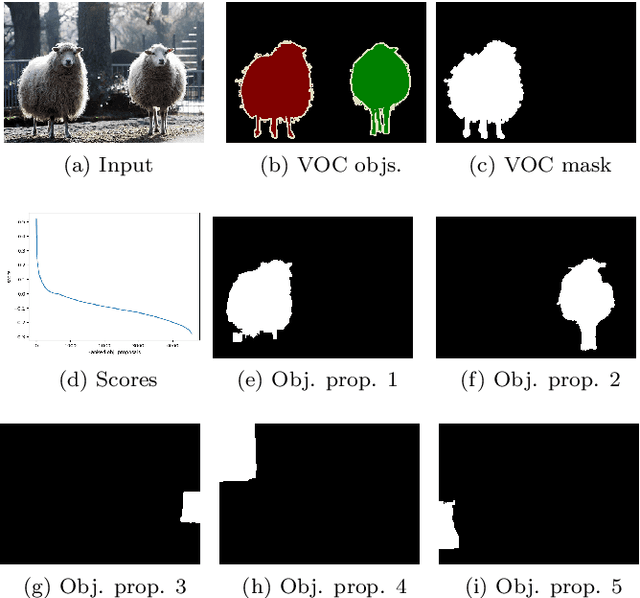
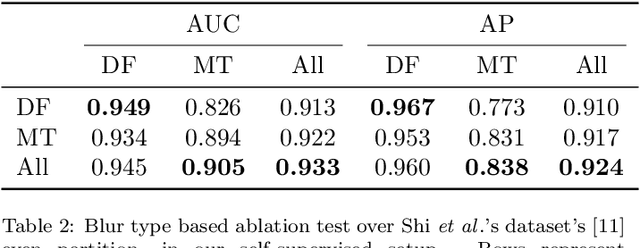
Blur detection aims at segmenting the blurred areas of a given image. Recent deep learning-based methods approach this problem by learning an end-to-end mapping between the blurred input and a binary mask representing the localization of its blurred areas. Nevertheless, the effectiveness of such deep models is limited due to the scarcity of datasets annotated in terms of blur segmentation, as blur annotation is labour intensive. In this work, we bypass the need for such annotated datasets for end-to-end learning, and instead rely on object proposals and a model for blur generation in order to produce a dataset of synthetically blurred images. This allows us to perform self-supervised learning over the generated image and ground truth blur mask pairs using CNNs, defining a framework that can be employed in purely self-supervised, weakly supervised or semi-supervised configurations. Interestingly, experimental results of such setups over the largest blur segmentation datasets available show that this approach achieves state of the art results in blur segmentation, even without ever observing any real blurred image.