 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELM: Embedding and Logit Margins for Long-Tail Learning
Apr 27, 2022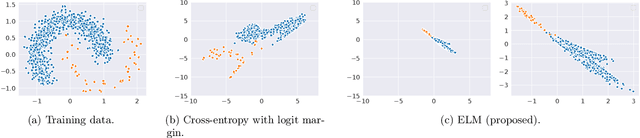
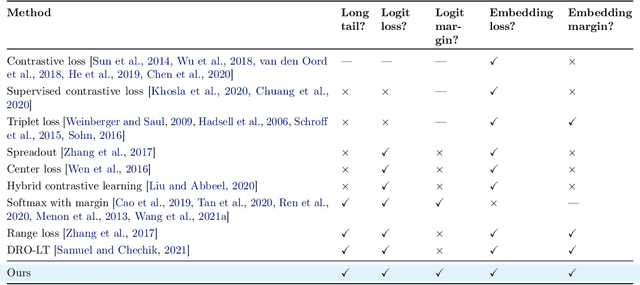
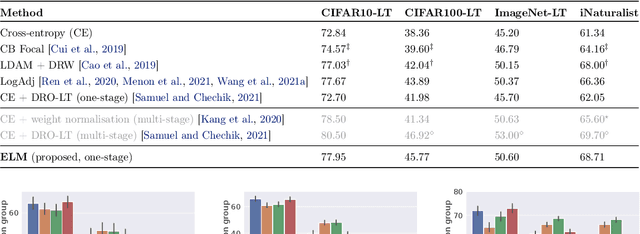
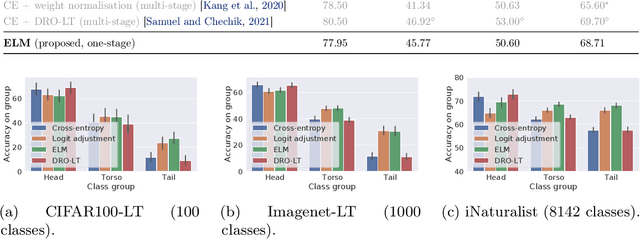
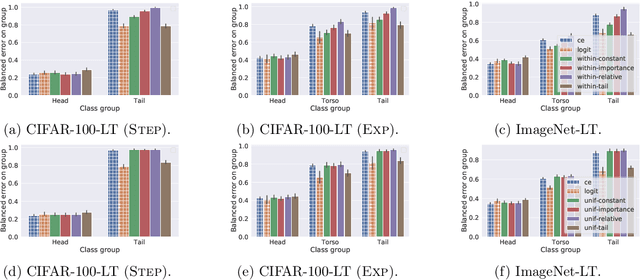
Long-tail learning is the problem of learning under skewed label distributions, which pose a challenge for standard learners. Several recent approaches for the problem have proposed enforcing a suitable margin in logit space. Such techniques are intuitive analogues of the guiding principle behind SVMs, and are equally applicable to linear models and neural models. However, when applied to neural models, such techniques do not explicitly control the geometry of the learned embeddings. This can be potentially sub-optimal, since embeddings for tail classes may be diffuse, resulting in poor generalization for these classes. We present Embedding and Logit Margins (ELM), a unified approach to enforce margins in logit space, and regularize the distribution of embeddings. This connects losses for long-tail learning to proposals in the literature on metric embedding, and contrastive learning. We theoretically show that minimising the proposed ELM objective helps reduce the generalisation gap. The ELM method is shown to perform well empirically, and results in tighter tail class embeddings.
When in Doubt, Summon the Titans: Efficient Inference with Large Models
Oct 19, 2021
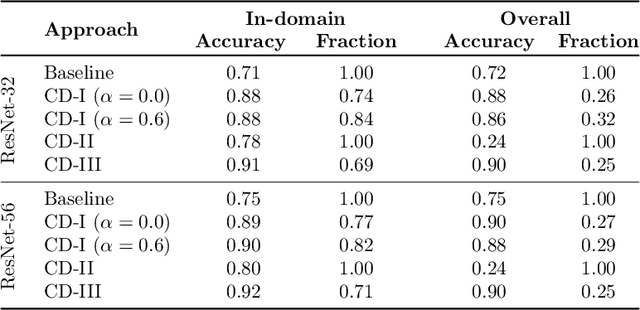
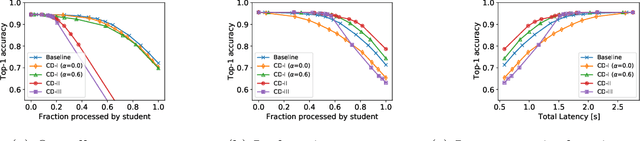
Scaling neural networks to "large" sizes, with billions of parameters, has been shown to yield impressive results on many challenging problems. However, the inference cost incurred by such large models often prevents their application in most real-world settings. In this paper, we propose a two-stage framework based on distillation that realizes the modelling benefits of the large models, while largely preserving the computational benefits of inference with more lightweight models. In a nutshell, we use the large teacher models to guide the lightweight student models to only make correct predictions on a subset of "easy" examples; for the "hard" examples, we fall-back to the teacher. Such an approach allows us to efficiently employ large models in practical scenarios where easy examples are much more frequent than rare hard examples. Our proposed use of distillation to only handle easy instances allows for a more aggressive trade-off in the student size, thereby reducing the amortized cost of inference and achieving better accuracy than standard distillation. Empirically, we demonstrate the benefits of our approach on both image classification and natural language processing benchmarks.
Training Over-parameterized Models with Non-decomposable Objectives
Jul 09, 2021
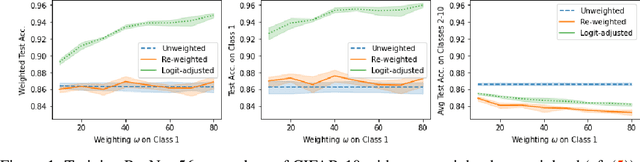

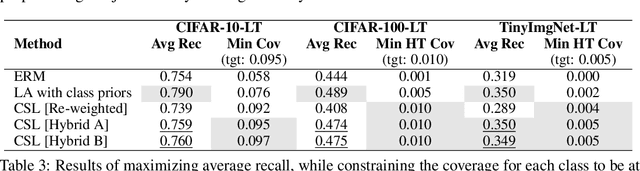
Many modern machine learning applications come with complex and nuanced design goals such as minimizing the worst-case error, satisfying a given precision or recall target, or enforcing group-fairness constraints. Popular techniques for optimizing such non-decomposable objectives reduce the problem into a sequence of cost-sensitive learning tasks, each of which is then solved by re-weighting the training loss with example-specific costs. We point out that the standard approach of re-weighting the loss to incorporate label costs can produce unsatisfactory results when used to train over-parameterized models. As a remedy, we propose new cost-sensitive losses that extend the classical idea of logit adjustment to handle more general cost matrices. Our losses are calibrated, and can be further improved with distilled labels from a teacher model. Through experiments on benchmark image datasets, we showcase the effectiveness of our approach in training ResNet models with common robust and constrained optimization objectives.
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021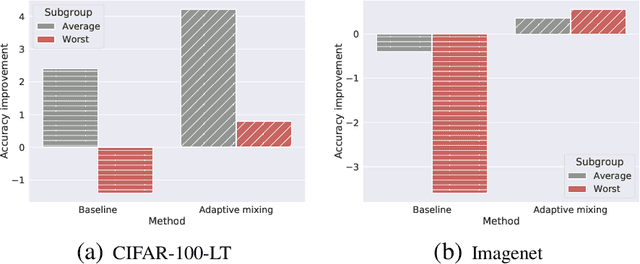

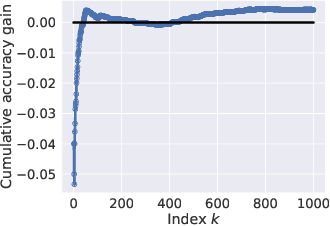
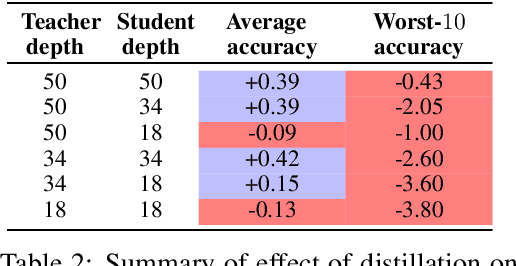
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021

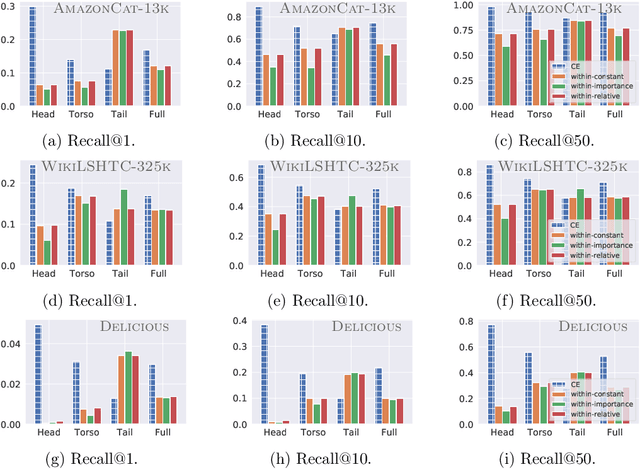
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Interval-censored Hawkes processes
Apr 16, 2021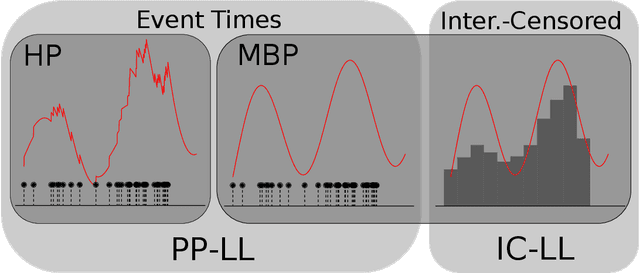
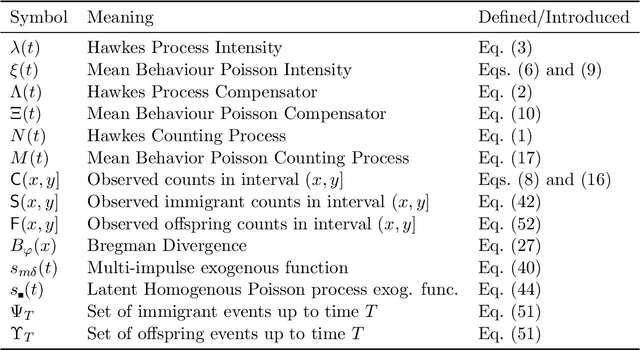
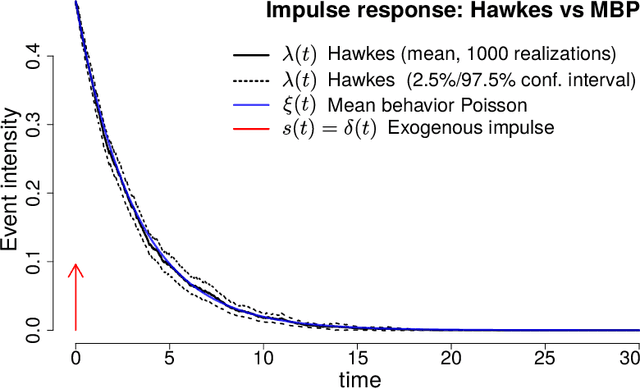
Hawkes processes are a popular means of modeling the event times of self-exciting phenomena, such as earthquake strikes or tweets on a topical subject. Classically, these models are fit to historical event time data via likelihood maximization. However, in many scenarios, the exact times of historical events are not recorded for either privacy (e.g., patient admittance to hospitals) or technical limitations (e.g., most transport data records the volume of vehicles passing loop detectors but not the individual times). The interval-censored setting denotes when only the aggregate counts of events at specific time intervals are observed. Fitting the parameters of interval-censored Hawkes processes requires designing new training objectives that do not rely on the exact event times. In this paper, we propose a model to estimate the parameters of a Hawkes process in interval-censored settings. Our model builds upon the existing Hawkes Intensity Process (HIP) of in several important directions. First, we observe that while HIP is formulated in terms of expected intensities, it is more natural to work instead with expected counts; further, one can express the latter as the solution to an integral equation closely related to the defining equation of HIP. Second, we show how a non-homogeneous Poisson approximation to the Hawkes process admits a tractable likelihood in the interval-censored setting; this approximation recovers the original HIP objective as a special case, and allows for the use of a broader class of Bregman divergences as loss function. Third, we explicate how to compute a tighter approximation to the ground truth in the likelihood. Finally, we show how our model can incorporate information about varying interval lengths. Experiments on synthetic and real-world data confirm our HIPPer model outperforms HIP and several other baselines on the task of interval-censored inference.
Distilling Double Descent
Feb 13, 2021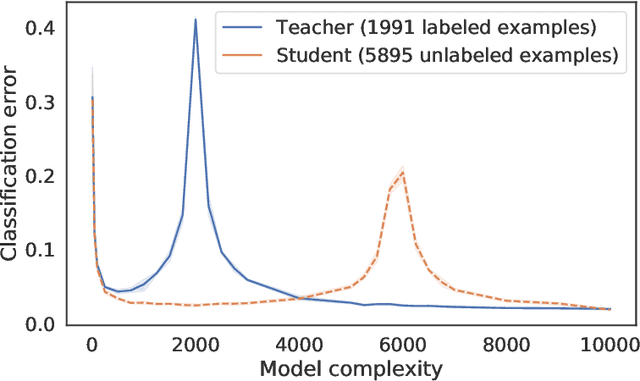
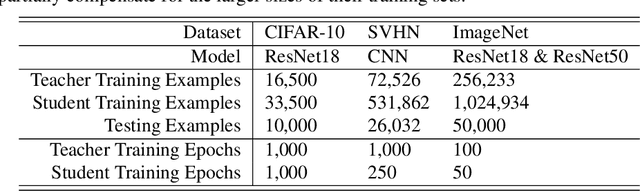
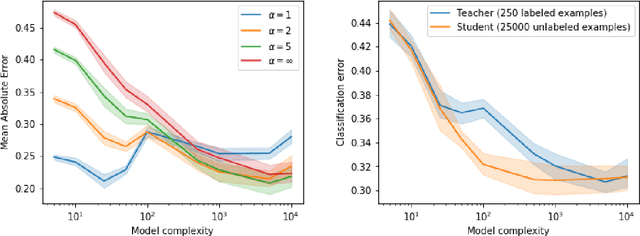
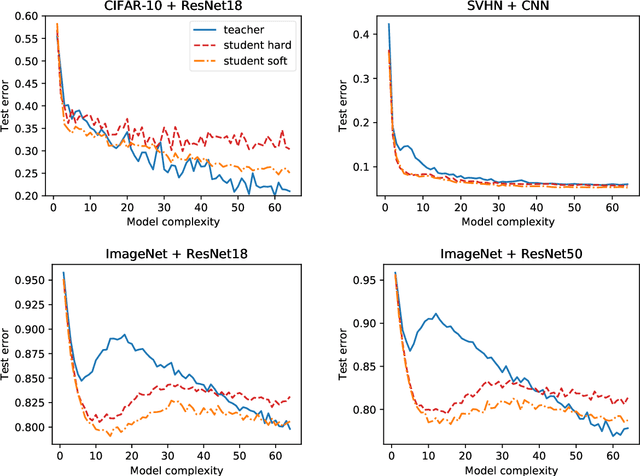
Distillation is the technique of training a "student" model based on examples that are labeled by a separate "teacher" model, which itself is trained on a labeled dataset. The most common explanations for why distillation "works" are predicated on the assumption that student is provided with \emph{soft} labels, \eg probabilities or confidences, from the teacher model. In this work, we show, that, even when the teacher model is highly overparameterized, and provides \emph{hard} labels, using a very large held-out unlabeled dataset to train the student model can result in a model that outperforms more "traditional" approaches. Our explanation for this phenomenon is based on recent work on "double descent". It has been observed that, once a model's complexity roughly exceeds the amount required to memorize the training data, increasing the complexity \emph{further} can, counterintuitively, result in \emph{better} generalization. Researchers have identified several settings in which it takes place, while others have made various attempts to explain it (thus far, with only partial success). In contrast, we avoid these questions, and instead seek to \emph{exploit} this phenomenon by demonstrating that a highly-overparameterized teacher can avoid overfitting via double descent, while a student trained on a larger independent dataset labeled by this teacher will avoid overfitting due to the size of its training set.
Semantic Label Smoothing for Sequence to Sequence Problems
Oct 15, 2020
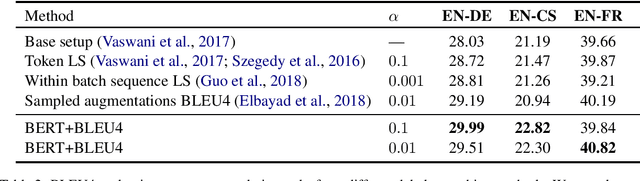

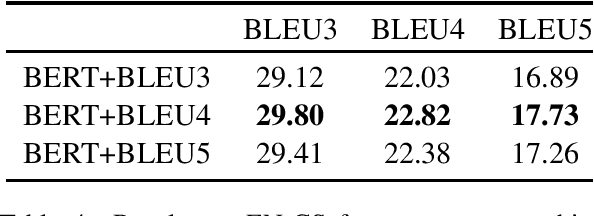
Label smoothing has been shown to be an effective regularization strategy in classification, that prevents overfitting and helps in label de-noising. However, extending such methods directly to seq2seq settings, such as Machine Translation, is challenging: the large target output space of such problems makes it intractable to apply label smoothing over all possible outputs. Most existing approaches for seq2seq settings either do token level smoothing, or smooth over sequences generated by randomly substituting tokens in the target sequence. Unlike these works, in this paper, we propose a technique that smooths over \emph{well formed} relevant sequences that not only have sufficient n-gram overlap with the target sequence, but are also \emph{semantically similar}. Our method shows a consistent and significant improvement over the state-of-the-art techniques on different datasets.
SupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy
Oct 06, 2020
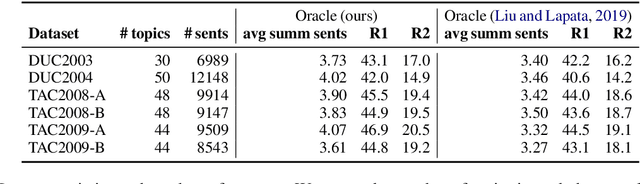
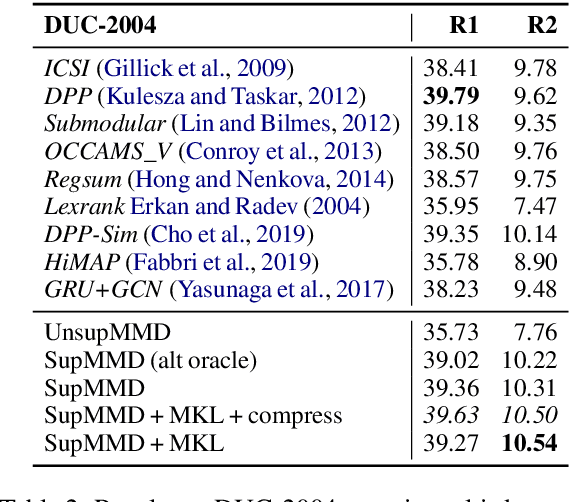

Most work on multi-document summarization has focused on generic summarization of information present in each individual document set. However, the under-explored setting of update summarization, where the goal is to identify the new information present in each set, is of equal practical interest (e.g., presenting readers with updates on an evolving news topic). In this work, we present SupMMD, a novel technique for generic and update summarization based on the maximum mean discrepancy from kernel two-sample testing. SupMMD combines both supervised learning for salience and unsupervised learning for coverage and diversity. Further, we adapt multiple kernel learning to make use of similarity across multiple information sources (e.g., text features and knowledge based concepts). We show the efficacy of SupMMD in both generic and update summarization tasks by meeting or exceeding the current state-of-the-art on the DUC-2004 and TAC-2009 datasets.
* 15 pages
Long-tail learning via logit adjustment
Jul 14, 2020
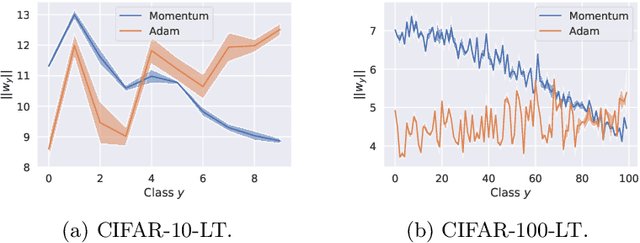
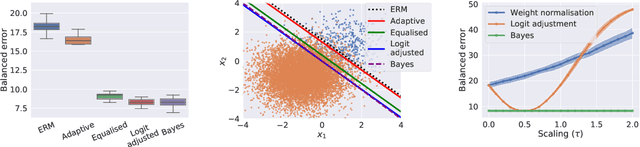
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels are associated with only a few samples. This poses a challenge for generalisation on such labels, and also makes na\"ive learning biased towards dominant labels. In this paper, we present two simple modifications of standard softmax cross-entropy training to cope with these challenges. Our techniques revisit the classic idea of logit adjustment based on the label frequencies, either applied post-hoc to a trained model, or enforced in the loss during training. Such adjustment encourages a large relative margin between logits of rare versus dominant labels. These techniques unify and generalise several recent proposals in the literature, while possessing firmer statistical grounding and empirical performance.