 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly-stochastic mining for heterogeneous retrieval
Paper and Code
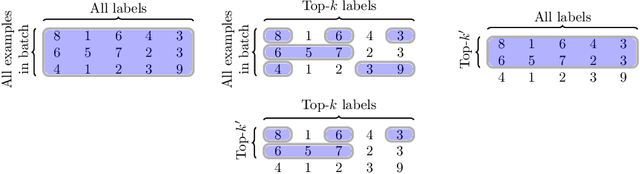


Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.